OpenMP 学习笔记
OpenMP 学习笔记
什么是 OpenMP
OpenMP 是一种用于共享内存并行系统的并行计算方案,支持的编程语言包括 C、C++ 还有 Fortran。
简单的说 OpenMP 是利用 CPU 多线程技术加速计算的一套方案。并且是为不熟悉多线程技术的开发人员准备的。程序员通过在源代码中加入专用的 pragma 来指明自己的意图,由此编译器可以自动将程序进行并行化,并在必要之处加入同步互斥以及通信。支持 OpenMP 的编译器包括 Intel Compiler、GCC、Visual C++ 和 Open64 编译器。对于不支持 OpenMP 的编译器,则忽略这些 pragma,程序退化为通常的程序(一般为串行),代码仍然可以正常运作,只是不能利用多线程来加速程序执行。
OpenMP 是一种标准的并行计算方案,但是:
- OpenMP 只用于单机程序,这点上与 MPI 不同,不能用于集群服务器编程。
- OpenMP 只是利用多线程技术,不能利用 GPU 加速计算。
- OpenMP 并不会利用 SIMD 等指令等加速计算。
一个简单的例子
先看一个最简单的例子:
int main(int argc, char *argv[])
{
int ID = 0;
printf("hello(%d) ", ID);
printf("world(%d)\n", ID);
}
输出结果如下:
hello(0) world(0)
我们改写一下这个程序:
#include
int main(int argc, char *argv[])
{
#pragma omp parallel
{
int ID = 0;
printf("hello(%d) ", ID);
printf("world(%d)\n", ID);
}
}
编译时要加上对 OpenMP 的支持。对于 gcc 来说是:gcc -fopenmp
运行结果如下:
hello(0) world(0)
hello(0) hello(0) hello(0) world(0)
world(0)
world(0)
我们可以看出 hello world 被运行了 4 次。OpenMP 可以用环境变量来控制生成的线程的数量。
如果设置 OMP_NUM_THREADS = 4 那么就只会输出两次 hello world.
我用的 IDE 是 QtCreator ,这里就讲讲如何在 QtCreator 中设置环境变量。其实很简答,大家看下面截图就好了。
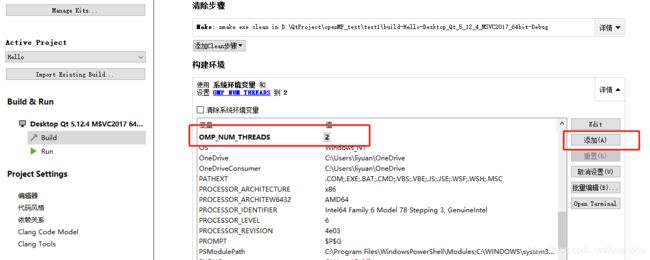
在简单说说 QtCreator 中如何设置编译器开启对 OpenMP 的支持:
如果编译器是 Visual C++,则在 pro 文件中增加如下一行:
QMAKE_CXXFLAGS+=/openmp
如果编译器是 GCC,则在 pro 文件中增加如下一行:
QMAKE_CXXFLAGS+= -fopenmp
再改一下程序:
#include
int main(int argc, char *argv[])
{
#pragma omp parallel
{
int ID = omp_get_thread_num();
printf("hello(%d) ", ID);
printf("world(%d)\n", ID);
}
}
运行结果如下:
hello(0) hello(1) world(1)
world(0)
除了用环境变量来控制线程数之外,还可以在程序中指定,比如下面这样:
#include
int main(int argc, char *argv[])
{
#pragma omp parallel num_threads(3)
{
int ID = omp_get_thread_num();
printf("hello(%d) ", ID);
printf("world(%d)\n", ID);
}
}
结果就不贴了。
从上面的例子可以看出,OpenMP 简化了线程的使用,使得我们不用考虑建立线程的那些细节。但是用了 OpenMP 之后,程序的运行结果与原来的程序也会有不同的。
Single Program Multiple Data(SPMD)
实现并行化的一个基本技巧是所谓的 SPMD,也就是将我们的数据复制好几份,每个线程操作一份数据。所有线程都执行完之后再把这些数据合并起来。
我们知道有如下的积分:
∫ 0 1 4 1 + x 2 d x = π \int_0^1 \frac{4}{1 + x^2} dx = \pi ∫011+x24dx=π
积分可以用求和在近似: $ \sum_{i=0}^{N} F(x_i) \Delta x \approx \pi$
第一版程序,不考虑并行化问题:
inline double f(double x)
{
return 4.0 / (1.0 + x * x);
}
int main(int argc, char *argv[])
{
const long num_steps = 1000000;
double sum = 0.0;
double step = 1.0 / num_steps;
for(int i =0 ; i < num_steps; ++i)
{
double x = (i + 0.5) * step;
sum += f(x);
}
double pi = step * sum;
printf("pi = %f", pi);
}
下面我们把这个程序改造成并行的。
#include
#include
#define NUM_THREADS 2
inline double f(double x)
{
return 4.0 / (1.0 + x * x);
}
int main(int argc, char *argv[])
{
const int num_steps = 1000000;
double sum[NUM_THREADS];
double step = 1.0 / num_steps;
int nthreads;
omp_set_num_threads(NUM_THREADS);
QTime t; t.start();
#pragma omp parallel
{
int id = omp_get_thread_num(); // 当前的是第几个线程
int nth = omp_get_num_threads(); // 总共有多少个线程
if(id == 0) nthreads = nth; // nth 是局部变量,需要传出去。只需要一个线程传出去就够了。
sum[id] = 0.0;
for(int i = id ; i < num_steps; i += nth)
{
double x = (i + 0.5) * step;
sum[id] += f(x);
}
}
double pi = 0.0;
for(int i = 0; i < nthreads; i++)
{
pi += sum[i] * step;
}
int el = t.elapsed();
printf("pi = %f\n", pi);
printf("elasped time = %d\n", el);
printf("nthreads = %d", nthreads);
}
运行结果如下:
pi = 3.141593
elasped time = 29
nthreads = 2
我们可以试着更改线程的数量:
pi = 3.141593
elasped time = 29
nthreads = 1
---------------------------
pi = 3.141593
elasped time = 29
nthreads = 2、。,5 、。,采用VC、。,ccccccccc
---------------------------
pi = 3.141593
elasped time = 23
nthreads = 3
---------------------------
pi = 3.141593
elasped time = 12
nthreads = 4
---------------------------
pi = 3.141593
elasped time = 43
nthreads = 10
可以看出随着线程的增加,计算时间是在缩小的,但是当线程数大于CPU 的内核数时计算时间范围增加了。
worksharing
上面介绍了 SPMD 方法,使用这种方法还是需要我们的程序做挺多的修改的。OpenMP 还针对常见的并行化需求,提供了些更简单的方法。这些方法被称为 worksharing construct。又细分为下面三种主要的方法:
-
循环结构
-
Sections/section 结构
-
Task 结构
循环结构(Loop Construct)
for 循环是代码中非常常见的一种结构,OpenMP 为此特别的做了处理。比如下面的代码,我们只需要告诉 openMP 分块算出来的 sum 最后要加到一起。剩下的如何把 for 循环分到多个线程中的事情 OpenMP 都替我们做了。
#define NUM_THREADS 2
inline double f(double x)
{
return 4.0 / (1.0 + x * x);
}
int main(int argc, char *argv[])
{
const int num_steps = 100000000;
double step = 1.0 / num_steps;
int nthreads;
double pi = 0;
omp_set_num_threads(NUM_THREADS);
QTime t; t.start();
double sum = 0.0;
#pragma omp parallel
{
nthreads = omp_get_num_threads();
#pragma omp for reduction(+:sum)
for(int i = 0 ; i < num_steps; i ++)
{
double x = (i + 0.5) * step;
sum += f(x);
}
}
pi = step * sum;
int el = t.elapsed();
printf("pi = %f\n", pi);
printf("elasped time = %d\n", el);
printf("nthreads = %d\n", nthreads);
}
这个代码告诉编译器各个线程计算出的 sum 需要加到一起。
pragma omp parallel 和 pragma omp for 可以合并到一起。像下面这样:
int main(int argc, char *argv[])
{
const int num_steps = 100000000;
double step = 1.0 / num_steps;
omp_set_num_threads(NUM_THREADS);
QTime t; t.start();
double sum = 0.0;
#pragma omp parallel for reduction(+:sum)
for(int i = 0 ; i < num_steps; i ++)
{
double x = (i + 0.5) * step;
sum += f(x);
}
double pi = step * sum;
int el = t.elapsed();
printf("pi = %f\n", pi);
printf("elasped time = %d\n", el);
}
Master 结构(Master construct)
这个用来标识出只由主线程运行的代码块。比如下面的代码片段:
#pragma omp parallel
{
do_many_things();
#pragma omp master
exchange_boundaries();
#pragma omp barrier
do_many_other_things();
}
这里 exchange_boundaries() 只需执行一次。所以我们要求在主线程中执行。
Single 结构 (Single construct)
Single construct 类似于 Master construct。只能由一个线程执行,但是不要求必须是主线程。这个结构自带 barrier ,如果不需要 barrier 可以加上 nowait.
#pragma omp parallel
{
do_many_things();
#pragma omp single
exchange_boundaries();
do_many_other_things();
}
ordered 结构(ordered construct)
ordered 结构可以确保这个区域是顺序执行的。比如下面的代码:
void f(int i)
{
int id = omp_get_thread_num();
printf("i = %d, id = %d\n", i, id);
}
int main(int argc, char *argv[])
{
#pragma omp parallel for
for(int i = 0 ; i < 5; i ++)
{
QThread::msleep(rand() % 100);
f(i);
}
}
运行结果如下:
i = 0, id = 0
i = 4, id = 3
i = 3, id = 2
i = 2, id = 1
i = 1, id = 0
加上 ordered 之后:
void f(int i)
{
int id = omp_get_thread_num();
printf("i = %d, id = %d\n", i, id);
}
int main(int argc, char *argv[])
{
#pragma omp parallel for ordered
for(int i = 0 ; i < 5; i ++)
{
QThread::msleep(rand() % 100);
#pragma omp ordered
f(i);
}
}
运行结果如下:
i = 0, id = 0
i = 1, id = 0
i = 2, id = 1
i = 3, id = 2
i = 4, id = 3
线程同步
线程同步有多种方法,在 OpenMP 中主要会用到如下的这些:
- critical
- atomic
- barrier
- ordered
- flush
- locks
下面依次介绍。
临界区 (critical)
所谓临界区,是一个特殊的代码块,这个代码块一个时刻只有一个线程可以进入。如果一个线程已经在这个代码块中了,那么其他的线程就会被阻塞。
比如我们上面提到的计算 pi 的程序,利用临界区可以改写为:
#include
#define NUM_THREADS 4
inline double f(double x)
{
return 4.0 / (1.0 + x * x);
}
int main(int argc, char *argv[])
{
const int num_steps = 100000000;
double step = 1.0 / num_steps;
int nthreads = 1;
double pi = 0;
omp_set_num_threads(NUM_THREADS);
QTime t; t.start();
#pragma omp parallel
{
int id = omp_get_thread_num(); // 当前的是第几个线程
int nth = omp_get_num_threads(); // 总共有多少个线程
if(id == 0) nthreads = nth;
double sum = 0.0;
for(int i = id ; i < num_steps; i += nth)
{
double x = (i + 0.5) * step;
sum += f(x);
}
#pragma omp critical
pi += sum * step;
}
int el = t.elapsed();
printf("pi = %f\n", pi);
printf("elasped time = %d\n", el);
printf("nthreads = %d\n", nthreads);
}
这个例子里 sum 成为了线程的局部变量,这些 sum 依次的加进 pi 的结果里就能得到最终的 pi.
atomic
所谓原子操作,也能保证一条语句执行时没有其他线程打断。但是原子操作只能对应简单的语句。而且只能是一条语句,不能是一个代码块。
#pragma omp parallel
{
int id = omp_get_thread_num(); // 当前的是第几个线程
int nth = omp_get_num_threads(); // 总共有多少个线程
if(id == 0) nthreads = nth;
double sum = 0.0;
for(int i = id ; i < num_steps; i += nth)
{
double x = (i + 0.5) * step;
sum += f(x);
}
sum *= step;
#pragma omp atomic
pi += sum;
}
Barrier
Barrier 是一组线程的一个边界,只有当所有的 线程都执行到 Barrier 时才会往下执行。我们前面介绍的 omp for 都是默认有 Barrier 的。也就是我们的 for 循环的各个线程都执行完才会往下执行。如果不希望要这个 barrier 可以加上 nowait ,比如下面这样:
#progma omp for nowait
for(int i = 0; i < N; i++)
{
B[i] = big_calc1(C, i);
}
A[id] = big_calc2(id);
上面的代码我们可以看出计算 B 和 计算 A 没有必须的先后关系。所以for循环结束处不需要 barrier。
下面再给个人为加 barrier 的例子:
#pragma omp parallel shared(A, B, C) private(id)
{
id = omp_get_thread_num();
A[id] = big_calc1(id);
#pragma omp barrier
#pragma omp for
for(int i = 0; i < N; i++)
{
C[i] = big_calc2(A, i);
}
#pragma omp for nowait
for(int i = 0; i < N; i++)
{
B[i] = big_calc3(C, i);
}
A[id] = big_calc4(id);
}
可以看出 C 的计算需要先算出 A,所以这里需要有个 barrier。for 循环默认带 barrier,所以第一个for循环后面不需要加 barrier。
分段并行 (Sections)
有时候我们程序的两个部门没有直接的关联,可以同时运行。这时可以用 secion 来指定。
比如下面的程序:
int main(int argc, char *argv[])
{
#pragma omp parallel
{
#pragma omp sections
{
#pragma omp section
{
printf("section 1 start, id = %d\n", omp_get_thread_num());
QThread::msleep(2000);
printf("section 1 end, id = %d\n", omp_get_thread_num());
}
#pragma omp section
{
printf("section 2 start, id = %d\n", omp_get_thread_num());
QThread::msleep(500);
printf("section 2 end, id = %d\n", omp_get_thread_num());
}
}
#pragma omp sections
{
#pragma omp section
{
printf("section 3 start, id = %d\n", omp_get_thread_num());
QThread::msleep(2000);
printf("section 3 end, id = %d\n", omp_get_thread_num());
}
#pragma omp section
{
printf("section 4 start, id = %d\n", omp_get_thread_num());
QThread::msleep(500);
printf("section 4 end, id = %d\n", omp_get_thread_num());
}
}
}
printf("end of this program\n");
}
运行结果如下:
section 1 start, id = 0
section 2 start, id = 1
section 2 end, id = 1
section 1 end, id = 0
section 3 start, id = 1
section 4 start, id = 2
section 4 end, id = 2
section 3 end, id = 1
end of this program
我们看到第一个sections 里所有的 section 都执行完之后才会往下继续执行第二个 sections。
可以通过增加 nowait 指示字改变这个特性。
int main(int argc, char *argv[])
{
#pragma omp parallel
{
#pragma omp sections nowait
{
#pragma omp section
{
printf("section 1 start, id = %d\n", omp_get_thread_num());
QThread::msleep(2000);
printf("section 1 end, id = %d\n", omp_get_thread_num());
}
#pragma omp section
{
printf("section 2 start, id = %d\n", omp_get_thread_num());
QThread::msleep(500);
printf("section 2 end, id = %d\n", omp_get_thread_num());
}
}
#pragma omp sections
{
#pragma omp section
{
printf("section 3 start, id = %d\n", omp_get_thread_num());
QThread::msleep(2000);
printf("section 3 end, id = %d\n", omp_get_thread_num());
}
#pragma omp section
{
printf("section 4 start, id = %d\n", omp_get_thread_num());
QThread::msleep(500);
printf("section 4 end, id = %d\n", omp_get_thread_num());
}
}
}
printf("end of this program\n");
}
结果如下:
section 1 start, id = 0
section 2 start, id = 1
section 3 start, id = 2
section 4 start, id = 3
section 2 end, id = 1
section 4 end, id = 3
section 1 end, id = 0
section 3 end, id = 2
end of this program
我们看到两个 sections 是一起开始的。但是这时更好的方法是将两个 sections 合并成一个 secitons.