在Pig中执行pig Latin语句的WordCount时报错为:ERROR org.apache.pig.tools.grunt.Grunt - ERROR 1066:
具体的报错信息如下:
2018-08-26 02:56:16,841 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - Failed!
2018-08-26 02:56:16,907 [main] ERROR org.apache.pig.tools.grunt.Grunt - ERROR 1066: Unable to open iterator for alias cntd. Backend error : java.lang.IllegalStateException: Job in state DEFINE instead of RUNNING
Details at logfile: /root/pig_1535266466706.log
在网上查找报错的具体的原因:
通过在网上查找,尝试了在Hadoop的配置文件的mapred-site.xml中添加如下信息
然后重启hadoop和historyserver
[root@bigdata11 hadoop]# stop-all.sh
[root@bigdata11 hadoop]#start-all.sh
[root@bigdata11 hadoop]#mr-jobhistory-daemon.sh start historyserver
再次执行Pig Latin
grunt> mydata = load '/root/input/data.txt' as (line:chararray);
grunt> words = foreach mydata generate flatten(TOKENIZE(line)) as word;
2018-08-26 02:43:42,363 [main] INFO org.apache.pig.impl.util.SpillableMemoryManager - Selected heap (Tenured Gen) of size 699072512 to monitor. collectionUsageThreshold = 489350752, usageThreshold = 489350752
grunt> words = foreach mydata generate flatten(TOKENIZE(line)) as word;
grunt> grpd = group words by word;
grunt> cntd = foreach grpd generate group,COUNT(words);
grunt> dump cntd;
发现还是报错

经过仔细查看日志,才发现时是pig导入数据的时候出现了错误


仔细检查发现是用的Linux本地的路径,而不是用的HDFS的路径;
把上面的修改配置文件的mapred-site.xml内容注释掉,并且重启Hadoop和historyserver
再次执行Pig Latin
grunt> mydata = load '/input/test.txt' as (line:chararray);
grunt> words = foreach mydata generate flatten(TOKENIZE(line)) as word;
grunt> grpd = group words by word;
grunt> cntd = foreach grpd generate group,COUNT(words);
grunt> dump cntd;
最后输出的结果为:
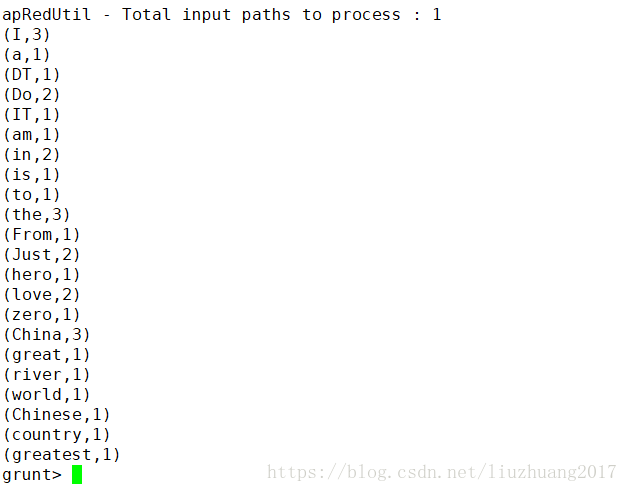
证明的确是加载数据的路径出错了,并非是hadoop的配置文件的问题。
总结:不管是对MySQL,Oracle,MoogoDB,Redis,Hive,Pig,Hadoop还是编写Java,Python,Shell程序,查看日志信息都是非常重要的,切记,不要只看日志信息的最后错误提示,前面的内容也需要仔细查看。