Flink流计算编程--在WindowedStream中体会EventTime与ProcessingTime
一、Flink流处理简介
Flink流处理的API叫做DataStream,可以在保证Exactly-Once的前提下提供高吞吐、低延时的实时流处理。用Flink作为流处理框架成功的案例可参考Flink母公司–Data Artisans官方blog中的2篇文章:
How we selected Apache Flink as our Stream Processing Framework at the Otto Group Business Intelligence Department
RBEA: Scalable Real-Time Analytics at King
二、Flink中的Time模型
Flink中提供了3种时间模型:EventTime、ProcessingTime、与Ingestion Time。底层实现上分为2种:Processing Time与Event Time,而Ingestion Time本质上也是一种Event Time,可以通过官方文档上的一张图展现是3者的区别:
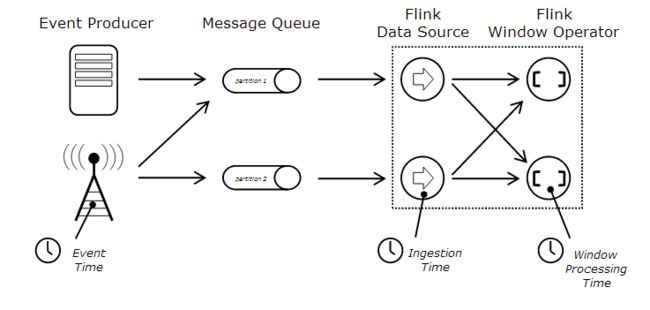
Event Time:事件产生的时间,即数据产生时自带时间戳,例如‘2016/06/17 11:04:00.960’
Ingestion Time:数据进入到Flink的时间,即数据进入source operator时获取时间戳
Processing Time:系统时间,与数据本身的时间戳无关,即在window窗口内计算完成的时间(默认的Time)
关于Flink中的Time,可以参考官方文档中的说明:Event Time。
关于Event Time,需要指出的是:数据产生的时间,编程时首先就是要告诉Flink,哪一列作为Event Time列,同时分配时间戳(TimeStamp)并发出水位线(WaterMark),来跟踪Event Time。简单理解,就是以Event Time列作为时间。水位线既然是用来标记Event Time的,那么Event Time在产生时有可能因为网络或程序错误导致的时间乱序,即Late Element的产生,因此WaterMark分为有序与无序2种:
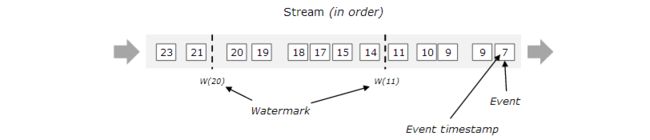
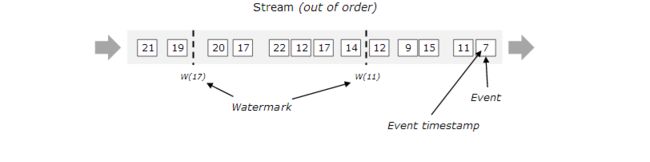
关于Late Element,举个例子说明:数据随着时间的流逝而产生,即数据的产生本是升序的,当Flink采用Event Time作为时间模型时,理论上也应该是升序的数据不断的进行计算。但是突然有个“延迟的”数据进入到了Flink,此时时间窗口已过,那么这个“延迟的”数据就不会被正确的计算。
对于这些数据,流处理的可能无法实时正确计算,因为WarterMark不可能无限制的等待Late Element的到来,所以可以通过之后的批处理(batch)对已经计算的数据进行更正。
关于流计算、时间模型与窗口的说明,可以参考:
Streaming 101

Streaming 102

三、Flink流处理编程的步骤
共5个步骤:
1、获取DataStream的运行环境
2、从Source中创建DataStream
3、在DataStream上进行transformation操作
4、将结果输出
5、执行流处理程序
四、程序说明
说明:
IDE:IntelliJ IDEA Community Edition(From JetBrains)
开发语言: Scala 2.10
运行环境:Flink 1.0.3 集群(1个JobManager+2个TaskManager)
程序提交:客户端CLI
管理工具:maven 3.3.9
五、程序演示–体会Event Time
关键点:
设置Event time characteristic:
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)复写map方法,实现稍微复杂点的map transaction:
map(new EventTimeFunction)分配timestamp以及watermark:
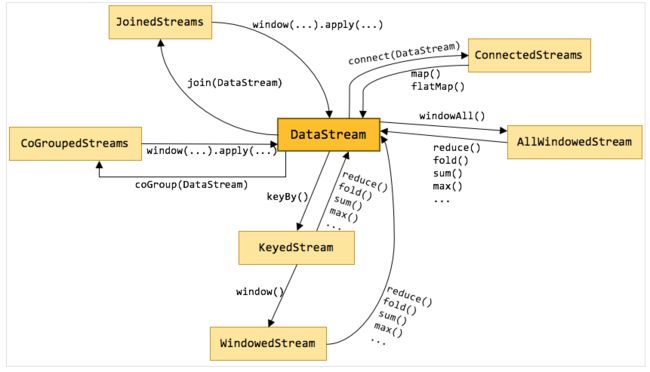
val timeValue = parsedStream.assignAscendingTimestamps(_._2)在dataStream上运行keyBy操作,产生keyedStream,继而在keyedStream上运行window操作,产生windowedStream,此时,windowedStream包含的元素主要包含3方面:K->key,W->window,T->Iterable[(..)],即每个key在特定窗口内的元素的集合。不同的stream之间的互相调用,可以参考:
Flink 原理与实现:数据流上的类型和操作
在windowedStream上聚合sum:
val sumVolumePerMinute = timeValue
.keyBy(_._1)
.window(TumblingEventTimeWindows.of(Time.minutes(1)))
.sum(3)
.name("sum volume per minute")运行程序,测试结果:
输入:
600000.SH,600000,20160520,93000960,1,39,173200,400,800,66,0,0,62420,76334,93002085
600000.SH,600000,20160520,93059000,1,39,173200,200,1000,66,0,0,62420,76334,93002085
600000.SH,600000,20160520,93101000,1,39,173200,300,1200,66,0,0,62420,76334,93002085
......输出如下:
(60000,20160520093000960,600)
(60000,20160520093101000,300)
...可以看出,结果就是按照Event Time的时间窗口计算得出的,而无关系统的时间(包括输入的快慢)。
Event Time Test的详细完整代码如下:
import java.text.SimpleDateFormat
import org.apache.flink.api.common.functions.MapFunction
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows
import org.apache.flink.streaming.api.windowing.time.Time
/**
* 这是一个简单的Flink DataStream程序,实现每分钟的累计成交量
* source:通过SocketStream模拟kafka消费数据
* sink:直接print输出到local,以后要实现sink到HDFS以及写到Redis
* 技术点:
* 1、采用EventTime统计每分钟的累计成交量,而不是系统时钟(processing Time)
* 2、将输入的时间合并并生成Long类型的毫秒时间,以此作为Timestamp,生成Timestamp和WaterMark
* 3、采用TumblingEventTimeWindow作为窗口,即翻滚窗口,不重叠的范围内实现统计
*/
object TransactionSumVolume1 {
case class Transaction(szWindCode:String, szCode:Long, nAction:String, nTime:String, seq:Long, nIndex:Long, nPrice:Long,
nVolume:Long, nTurnover:Long, nBSFlag:Int, chOrderKind:String, chFunctionCode:String,
nAskOrder:Long, nBidOrder:Long, localTime:Long
)
def main(args: Array[String]): Unit = {
/**
* when Running the program, you should input 2 parameters: hostname and port of Socket
*/
if (args.length != 2) {
System.err.println("USAGE:\nSocketTextStreamWordCount " )
return
}
val hostName = args(0)
val port = args(1).toInt
/**
* Step 1. Obtain an execution environment for DataStream operation
* set EventTime instead of Processing Time
*/
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
/**
* Step 2. Create DataStream from socket
*/
val input = env.socketTextStream(hostName,port)
/**
* Step 3. Implement '分钟成交量' logic
*/
/**
* parse input stream to a new Class which is implement the Map function
*/
val parsedStream = input
.map(new EventTimeFunction)
/**
* assign Timestamp and WaterMark for Event time: eventTime(params should be a Long type)
*/
val timeValue = parsedStream.assignAscendingTimestamps(_._2)
val sumVolumePerMinute = timeValue
.keyBy(_._1)
.window(TumblingEventTimeWindows.of(Time.minutes(1)))
.sum(3)
.name("sum volume per minute")
/**
* Step 4. Sink the final result to standard output(.out file)
*/
sumVolumePerMinute.map(value => (value._1,value._3,value._4)).print()
/**
* Step 5. program execution
*/
env.execute("SocketTextStream for sum of volume Example")
}
class EventTimeFunction extends MapFunction[String, (Long, Long, String, Long)] {
def map(s: String): (Long, Long, String, Long) = {
val columns = s.split(",")
val transaction : Transaction = Transaction(columns(0),columns(1).toLong,columns(2),columns(3),columns(4).toLong,columns(5).toLong,
columns(6).toLong,columns(7).toLong,columns(8).toLong,columns(9).toInt,columns(9),columns(10),columns(11).toLong,
columns(12).toLong,columns(13).toLong)
val format = new SimpleDateFormat("yyyyMMddHHmmssSSS")
val volume : Long = transaction.nVolume
val szCode : Long = transaction.szCode
if (transaction.nTime.length == 8 ) {
val eventTimeString = transaction.nAction + '0' + transaction.nTime
val eventTime : Long= format.parse(eventTimeString).getTime
(szCode, eventTime, eventTimeString, volume)
}else {
val eventTimeString = transaction.nAction + transaction.nTime
val eventTime = format.parse(eventTimeString).getTime
(szCode, eventTime, eventTimeString, volume)
}
}
}
}六、程序演示–体会Processing Time
关键点:
设置TumblingProcessingTimeWindow,由于默认的Time Characteristic就是Processing Time,因此不用特别指定,在windowed assign时,只需指定系统自带的timeWindow即可:
timeWindow(Time.seconds(15))在windowedStream之后,需要进行聚合操作,产生新的DataStream。系统提供了sum、reduce、fold等操作,但是如果遇到窗口内的计算非常复杂的情况,则需要采用apply{…}方法。windowedStream.apply{}的方法可参考源码:org.apache.flink.streaming.api.scala.WindowedStream.scala
提供了6种不同的方法,详情见:
WindowedStream.scala
这个测试就是在windowedStream上调用了apply方法,实现了稍微复杂的运算:
.apply{ (k : Long, w : TimeWindow, T: Iterable[(Long, Long, Long)], out : Collector[(Long,String,String,Double)]) =>
var sumVolume : Long = 0
var sumTurnover : Long = 0
for(elem <- T){
sumVolume = sumVolume + elem._2
sumTurnover = sumTurnover + elem._3
}
val format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS")
val vwap : Double = BigDecimal(String.valueOf(sumTurnover))
./ (BigDecimal(String.valueOf(sumVolume)))
.setScale(2,BigDecimal.RoundingMode.HALF_UP)
.toDouble
out.collect((k,format.format(w.getStart),format.format(w.getEnd),vwap))
}运行程序,测试结果:
输入(由于是Processing Time,输入时要注意时间间隔,超过15秒的就会产生新窗口,我的操作是前2条数据同时输入,隔一段时间后输入第3条数据):
600000.SH,600000,20160520,93000960,1,39,173200,400,800,66,0,0,62420,76334,93002085
600000.SH,600000,20160520,93059000,1,39,173200,200,1000,66,0,0,62420,76334,93002085
600000.SH,600000,20160520,93101000,1,39,173200,300,1200,66,0,0,62420,76334,93002085
......结果如下:
(60000,2016-06-16 17:56:00.000,2016-06-16 17:56:15.000,3.0)
(60000,2016-06-16 17:58:15.000,2016-06-16 17:58:30.000,4.0)可以看到,这个结果跟事件的时间没有任何关系,只跟系统处理完成的时间有关。
完整的代码如下:
import java.text.SimpleDateFormat
import org.apache.flink.api.common.functions.MapFunction
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.util.Collector
/**
* 这个Flink DataStream程序,实现“每15秒的加权平均价--VWAP”
* source:通过SocketStream模拟kafka消费数据
* sink:直接print输出到local,以后要实现sink到HDFS以及写到Redis
* 技术点:
* 1、采用默认的Processing Time统计每15秒钟的加权平均价
* 2、采用TumblingProcessingTimeWindow作为窗口,即翻滚窗口,系统时钟,不重叠的范围内实现统计
* 3、在WindowedStream上实现自定义的apply算法,即加权平均价,而非简单的Aggregation
*/
object TransactionVWap {
case class Transaction(szWindCode:String, szCode:Long, nAction:String, nTime:String, seq:Long, nIndex:Long, nPrice:Long,
nVolume:Long, nTurnover:Long, nBSFlag:Int, chOrderKind:String, chFunctionCode:String,
nAskOrder:Long, nBidOrder:Long, localTime:Long
)
def main(args: Array[String]): Unit = {
/**
* when Running the program, you should input 2 parameters: hostname and port of Socket
*/
if (args.length != 2) {
System.err.println("USAGE:\nSocketTextStreamWordCount " )
return
}
val hostName = args(0)
val port = args(1).toInt
/**
* Step 1. Obtain an execution environment for DataStream operation
* set EventTime instead of Processing Time
*/
val env = StreamExecutionEnvironment.getExecutionEnvironment
//Processing time is also the Default TimeCharacteristic
env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime)
/**
* Step 2. Create DataStream from socket
*/
val input = env.socketTextStream(hostName,port)
/**
* Step 3. Implement '每15秒加权平均价-VWAP' logic
* Note: windowedStream contains 3 attributes: T=>elements, K=>key, W=>window
*/
val sumVolumePerMinute = input
//transform Transaction to tuple(szCode, volume, turnover)
.map(new VwapField)
//partition by szCode
.keyBy(_._1)
//building Tumbling window for 15 seconds
.timeWindow(Time.seconds(15))
//compute VWAP in window
.apply{ (k : Long, w : TimeWindow, T: Iterable[(Long, Long, Long)], out : Collector[(Long,String,String,Double)]) =>
var sumVolume : Long = 0
var sumTurnover : Long = 0
for(elem <- T){
sumVolume = sumVolume + elem._2
sumTurnover = sumTurnover + elem._3
}
val format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS")
val vwap : Double = BigDecimal(String.valueOf(sumTurnover))
./ (BigDecimal(String.valueOf(sumVolume)))
.setScale(2,BigDecimal.RoundingMode.HALF_UP)
.toDouble
out.collect((k,format.format(w.getStart),format.format(w.getEnd),vwap))
}
.name("VWAP per 15 seconds")
/**
* Step 4. Sink the final result to standard output(.out file)
*/
sumVolumePerMinute.print()
/**
* Step 5. program execution
*/
env.execute("SocketTextStream for sum of volume Example")
}
class VwapField extends MapFunction[String, (Long, Long, Long)] {
def map(s: String): (Long, Long, Long) = {
val columns = s.split(",")
val transaction : Transaction = Transaction(columns(0),columns(1).toLong,columns(2),columns(3),columns(4).toLong,columns(5).toLong,
columns(6).toLong,columns(7).toLong,columns(8).toLong,columns(9).toInt,columns(9),columns(10),columns(11).toLong,
columns(12).toLong,columns(13).toLong)
val volume : Long = transaction.nVolume
val szCode : Long = transaction.szCode
val turnover : Long = transaction.nTurnover
(szCode, volume, turnover)
}
}
}
七、总结
何时用Event Time,何时用Processing Time,这个要看具体的业务场景。
同时,对于Event Time中的Late Element,大家可以自己模拟输入,看看结果如何。
自定义function与operator都应该是有状态的,以便恢复,这里简化,并没有设置state。
参考文档
1.https://www.oreilly.com/ideas/the-world-beyond-batch-streaming-101
2.https://www.oreilly.com/ideas/the-world-beyond-batch-streaming-102
3.https://ci.apache.org/projects/flink/flink-docs-master/apis/streaming/index.html
4.https://ci.apache.org/projects/flink/flink-docs-master/apis/streaming/event_time.html
5.https://ci.apache.org/projects/flink/flink-docs-master/apis/streaming/windows.html
6.http://blog.madhukaraphatak.com/introduction-to-flink-streaming-part-9/
7.http://www.cnblogs.com/fxjwind/p/5434572.html
8.https://github.com/apache/flink/
9.http://wuchong.me/blog/2016/05/20/flink-internals-streams-and-operations-on-streams/
10.http://data-artisans.com/blog/
11.http://dataartisans.github.io/flink-training/