YOLOV3解读(1)
所使用的yolov3为tensorflow版本:https://github.com/qqwweee/keras-yolo3
参数
xml数据集中的参数
图片的位置 框的4个坐标及标签(xmin,ymin,xmax,ymax,label_id)

预测特征图(Prediction Feature Map)的anchor框(anchor box)集合
- 3个尺度(scale)的特征图,每个特征图3个anchor框,共9个框,从小到大排列;
- 1 ~ 3是大尺度(52x52)特征图所使用的,4 ~ 6是中尺度(26x26),7 ~ 9是小尺度(13x13)
- 大尺度特征图检测小物体,小尺度检测大物体;
- 9个anchor来源于边界框(Bounding Box)的k-means聚类。
COCO的anchors如下:
10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
图片输入尺寸,默认为416x416
- 图片尺寸满足32的倍数,在DarkNet网络中,含有5次步长为2的降采样卷积(32=2^5)
- 在最底层时,特征图尺寸需要满足为奇数,如13,以保证中心点落在唯一框中。当为偶数时,则导致中心点落在中心的4个框中。
创建模型
创建YOLOv3的网络模型,输入:
- input_shape:图片尺寸;
- anchors:9个anchor box;
- num_classes:类别数;
- freeze_body:网络冻结模式,1是冻结DarkNet53模型,2是全部冻结保留最后3层;
- weights_path:预训练模型的权重
model = create_model(input_shape, anchors, num_classes,
freeze_body=2,
weights_path=pretrained_path)

样本数量
Shuffle
将数据集拆分为10份,训练9份,验证1份
val_split = 0.1 # 训练和验证的比例
with open(annotation_path) as f:
lines = f.readlines()
np.random.seed(47)
np.random.shuffle(lines)
np.random.seed(None)
num_val = int(len(lines) * val_split) # 验证集数量
num_train = len(lines) - num_val # 训练集数量
一阶段训练
- 优化器使用常见的Adam;
- 损失函数,直接使用,模型的输出y_pred,忽略真值y_true;
实现
model.compile(optimizer=Adam(lr=1e-3), loss={
# 使用定制的 yolo_loss Lambda层
'yolo_loss': lambda y_true, y_pred: y_pred}) # 损失函数
把y_true当成一个输入,构成多输入模型,把loss写成层(Lambda层),作为最后的输出。这样,构建模型的时候,就只需要将模型的输出(output)定义为loss即可。而编译(compile)的时候,直接将loss设置为y_pred,因为模型的输出就是loss,即y_pred就是loss,因而无视y_true。训练的时候,随便添加一个符合形状的y_true数组即可。
模型fit数据,使用数据生成包装器(data_generator_wrapper),按批次生成训练和验证数据。最终,模型model存储权重。
实现如下:
batch_size = 32 # batch
model.fit_generator(data_generator_wrapper(lines[:num_train], batch_size, input_shape, anchors, num_classes),
steps_per_epoch=max(1, num_train // batch_size),
validation_data=data_generator_wrapper(
lines[num_train:], batch_size, input_shape, anchors, num_classes),
validation_steps=max(1, num_val // batch_size),
epochs=50,
initial_epoch=0,
callbacks=[logging, checkpoint])
# 存储最终的参数,再训练过程中,也通过回调存储
model.save_weights(log_dir + 'trained_weights_stage_1.h5')
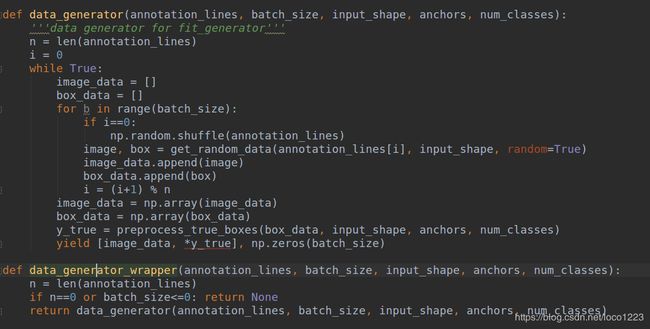
annotation_lines #指读入的图片地址,也可能就是图片信息,也就是框,类等信息
# with open(annotation_path) as f:
# lines = f.readlines()
#data_generator_wrapper(lines[:num_train]
get_random_data(annotation_line, input_shape, random=True, max_boxes=20, jitter=.3, hue=.1, sat=1.5, val=1.5, proc_img=True)
#随机打乱 步骤,读取图片大小及需要的大小,
#不随机,将图片处理到需求大小,并调整框的位置;
#随机,可对对图片进行翻转,将图片处理到需求大小,并调整框的位置,空缺处用均匀色填充;
preprocess_true_boxes(true_boxes, input_shape, anchors, num_classes):
#y_true: list of array, shape like yolo_outputs, xywh are reletive value
#返回y_true。计算真实框的长宽,归一化,计算经神经网络后的grid大小,分别缩小了32,16,8,并各对应三个anchor,构建y_true的形状,根据#宽设计一个mask,筛选出最合适的钱20个预测anchor,并将数据填入到y_true中。
#np.expand_dims:xpand_dims(a, axis)就是在axis的那一个轴上把数据加上去,这个数据在axis这个轴的0位置
#yield:yield就是 return 返回一个值,并且记住这个返回的位置,下次迭代就从这个位置后(下一行)开始。带有yield的函数不仅仅只用于for循环中,而且可用于某个函数的参数,只要这个函数的参数允许迭代参数。
在训练过程中,也会存储模型的参数,只存储权重(save_weights_only),只存储最优结果(save_best_only),每隔3个epoch存储一次(period),
即:
checkpoint = ModelCheckpoint(log_dir + 'ep{epoch:03d}-loss{loss:.3f}-val_loss{val_loss:.3f}.h5',
monitor='val_loss', save_weights_only=True,
save_best_only=True, period=3) # 只存储weights权重
二阶段训练
第2阶段,使用第1阶段已训练的网络权重,继续训练:
- 将全部的参数都设置为可训练,而第1阶段则是冻结(freeze)部分参数;
- 优化器,仍是Adam,只是学习率(lr)有所下降,从1e-3减少至1e-4,细腻地学习最优参数;
- 损失函数,仍是只使用y_pred,忽略y_true。
实现
for i in range(len(model.layers)):
model.layers[i].trainable = True
#设置之前的训练模型每一层均为可训练的状态
model.compile(optimizer=Adam(lr=1e-4),
loss={'yolo_loss': lambda y_true, y_pred: y_pred})
第2阶段的模型fit数据,与第1阶段类似,从第50个epoch开始,一直训练到第100个epoch,触发条件则提前终止。额外增加了两个回调reduce_lr和early_stopping
- reduce_lr:当评价指标不在提升时,减少学习率,每次减少10%(factor),当学习率3次未减少(patience)时,终止训练。
- early_stopping:验证集准确率,连续增加小于0(min_delta)时,持续10个epoch(patience),则终止训练。
实现
reduce_lr = ReduceLROnPlateau(monitor='val_loss', factor=0.1, patience=3, verbose=1) # 当评价指标不在提升时,减少学习率
early_stopping = EarlyStopping(monitor='val_loss', min_delta=0, patience=10, verbose=1) # 验证集准确率,下降前终止
batch_size = 32
model.fit_generator(data_generator_wrapper(lines[:num_train], batch_size, input_shape, anchors, num_classes),
steps_per_epoch=max(1, num_train // batch_size),
validation_data=data_generator_wrapper(lines[num_train:], batch_size, input_shape, anchors,
num_classes),
validation_steps=max(1, num_val // batch_size),
epochs=100,
initial_epoch=50,
callbacks=[logging, checkpoint, reduce_lr, early_stopping])
model.save_weights(log_dir + 'trained_weights_final.h5')
至此,在第2阶段训练完成之后,输出的网络参数,就是最终的模型参数。
补充(EarlyStopping)
EarlyStopping是Callback(回调类)的子类,Callback用于指定在每个阶段开始和结束的时候执行的操作。在Callback中,有一些已经实现的简单接口,如acc、val_acc、loss和val_loss等,还有一些复杂接口,如ModelCheckpoint(用于存储模型参数)和TensorBoard(用于画图)。
常见的Callback回调接口
def on_epoch_begin(self, epoch, logs=None):
def on_epoch_end(self, epoch, logs=None):
def on_batch_begin(self, batch, logs=None):
def on_batch_end(self, batch, logs=None):
def on_train_begin(self, logs=None):
def on_train_end(self, logs=None):
EarlyStopping则是用于提前停止训练的Callback。具体地,当训练或验证集中的loss不再减小,即减小的程度小于某个阈值时,停止训练,提高调参效率,避免浪费资源。
在model的fit数据中,设置callbacks回调,列表形式,支持设置多个,如
callbacks=[logging, checkpoint, reduce_lr, early_stopping]
EarlyStopping的参数:
- monitor:监控数据的类型,支持acc、val_acc、loss、val_loss等;
- min_delta:停止的阈值,与mode参数配合,增加或下降最少的阈值;
- mode:min是最少,max是最多,auto是自动,与min_delta配合;
- patience:达到阈值之后,能够容忍的epoch数,避免停止过早;
- verbose:日志的繁杂程度,值越大,输出的信息越多。
min_delta和patience需要相互配合,避免模型停止在抖动过程中,在设置的时候,需要相互协调。一般而言,min_delta降低,patience适当减少;min_delta增加,则patience适当延长。
实例
early_stopping = EarlyStopping(monitor='val_loss', min_delta=0, patience=10, verbose=1)
参考:
http://www.jintiankansha.me/t/b40H0pLG7p