大数据平台搭建:Hadoop-3.x + Spark-2.x + Hive-2.x + Hbase-1.4 + Phoenix-4.14 + Cassandra + ES + Accumulo-1.9
换了新笔记本,做个笔记。
一,软件准备(自取所需)
Java-1.8
Scala-2.11
Hadoop-3.1.1
Spark-2.3.2
Hive-2.3.4
phoenix
二,SSH免密码登录
(即使是当地的单机也需要SSH,否则格式化的hadoop的存储系统时无权限,导致失败
:本地主机:@localhost:权限被拒绝(公钥,密码)开始)
公共密钥生成命令(在客户端下依次执行,所有选项按回车即可)
(1)$ ssh-keygen -t dsa -f ~/.ssh/id_dsa
(2)$ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
[注释:〜/.ssh/id_dsa.pub文件为公钥,拷贝到服务器的〜/.ssh /目录中,执行cat ~/.ssh/id_dsa.pub >> 〜/.ssh/authorized_keys,权限只给用户本人,否则无法连接]
尝试连接(第一次可能需要输入密码):
:〜$ ssh localhost

Ps:如果配了ssh免密,登入时还需要输入密码,需要需改.ssh文件夹访问权限,分配权限为登陆用户
chmod 700 /home/raini/.ssh
chmod 600 /home/raini/.ssh/*
chown raini: /home/raini/.ssh
chown raini: /home/raini/.ssh/*
三,安装Java和Scala
1.分别解压Java和Scala到自己想存放的目录
2.配置环境变量
raini @ biyuzhe:〜$ gedit .bashrc (在末尾加入)
## java
export JAVA_HOME=/home/raini/app/jdk
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib:$CLASSPATH
export PATH=${JAVA_HOME}/bin:$JRE_HOME/bin:$PATH
## scala
export SCALA_HOME=/home/raini/app/scala
export PATH=${SCALA_HOME}/bin:$PATH3.执行$ source .bashrc (应用更改)
4.验证

四,安装Hadoop
解压:tar -zxvf hadoop-3.1.1.tar.gz
2. raini @ biyuzhe:〜$ gedit .bashrc(在文件里追加)
## hadoop-3.x
export HADOOP_HOME=/home/raini/app/hadoop
export CLASSPATH=".:$JAVA_HOME/lib:$CLASSPATH"
#
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
#
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_CONF_DIR=$HADOOP_HOME
export HADOOP_PREFIX=$HADOOP_HOME
export HADOOP_LIBEXEC_DIR=$HADOOP_HOME/libexec
export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native:$JAVA_LIBRARY_PATH
export HADOOP_CONF_DIR=$HADOOP_PREFIX/etc/hadoop
#
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
#
#export HDFS_DATANODE_USER=root
#export HDFS_DATANODE_SECURE_USER=root
#export HDFS_SECONDARYNAMENODE_USER=root
#export HDFS_NAMENODE_USER=root
3. vi etc/hadoop/core-site.xml
fs.defaultFS
hdfs://biyuzhe:9000
hadoop.tmp.dir
/home/raini/app/hadoop/tmp/tmp
集群模式:

4. vi etc/hadoop/hdfs-site.xml
dfs.replication
1
dfs.namenode.name.dir
/home/raini/app/hadoop/tmp/hdfs/name
dfs.namenode.data.dir
/home/raini/app/hadoop/tmp/hdfs/data

集群模式:

5. vi etc/hadoop/mapred-site.xml
集群模式(单机可选):
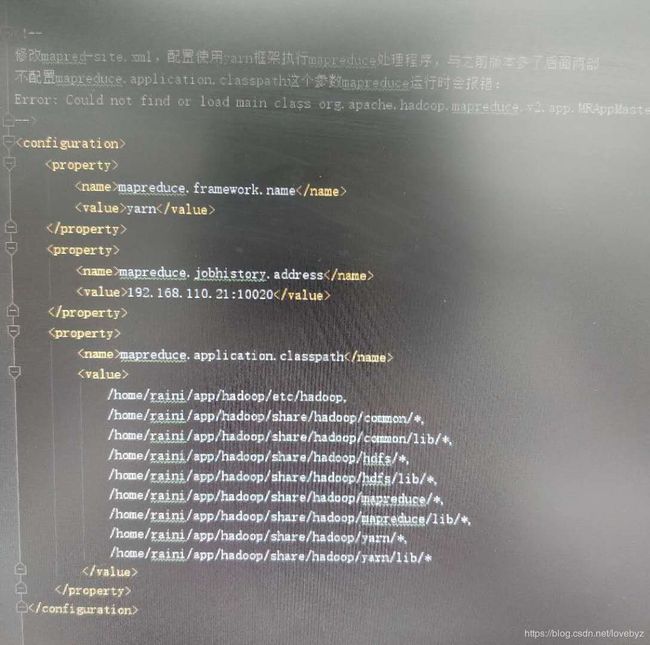
6. vi hadoop-env.sh
export JAVA_HOME=/home/raini/app/jdk
export HADOOP_HOME=/home/raini/app/hadoop
# 默认情况下,Hadoop的生成大量调试日志。 为了制止这种行为,开头和结尾查找行的export HADOOP_OPTS并将其更改为:
export HADOOP_OPTS="$HADOOP_OPTS -XX:-PrintWarnings -Djava.net.preferIPv4Stack=true"
# pid文件
export HADOOP_PID_DIR=/home/raini/app/tmp/pids7.格式化HDFS文件系统
$ bin/hdfs namenode -format8.启动名称节点和数据节点守护进程
$ sbin/start-dfs.sh9.jps查看进程

10.访问名称节点的网络服务
http://localhost:9870/ ,查看hadoop状况

五,安装Spark
解压:tar -zxvf spark-2.3.2-bin-hadoop2.7.tgz
2. raini @ biyuzhe:〜$ gedit .bashrc(在文件里追加)
顺便把pyspark也配置了
## spark
export SPARK_HOME=/home/raini/app/spark
export PATH=${SPARK_HOME}/bin:$PATH
export PYSPARK_PYTHONPATH=${SPARK_HOME}/bin:${SPARK_HOME}/python:${SPARK_HOME}/python/lib/py4j-0.10.7-src.zip:$PATH
# PYSPARK
export PYSPARK_DRIVER_PYTHON=$ANACONDA_ROOT/bin/ipython notebook
export PYSPARK_PYTHON=$ANACONDA_ROOT/envs/py35/bin/python
export PYSPARK_DRIVER_PYTHON_OPTS="notebook"3.更改配置
1. vim slaves (追加自己的主机名)
##localhost
biyuzhe
2.vim spark-env.sh
追加:
export JAVA_HOME=/home/raini/app/jdk
export SCALA_HOME=/home/raini/app/scala
export SPARK_WORKER_MEMORY=1G
export HADOOP_HOME=/home/raini/app/hadoop
export HADOOP_CONF_DIR=/home/raini/app/hadoop/etc/hadoop
export SPARK_MASTER_HOST=biyuzhe
export SPARK_PID_DIR=/home/raini/app/spark/data/pid
export SPARK_LOCAL_DIRS=/home/raini/app/spark/data/spark_shuffle
3.vim spark-defaults.conf
追加:
# Example:
# spark.master spark://master:7077
# spark.eventLog.enabled true
# spark.eventLog.dir hdfs://namenode:8021/directory ## 但是hadoop配置的是9000
# spark.serializer org.apache.spark.serializer.KryoSerializer
# spark.driver.memory 5g
# spark.executor.extraJavaOptions -XX:+PrintGCDetails -Dkey=value -Dnumbers="one two three"
spark.master spark://biyuzhe:7077
spark.eventLog.enabled true
spark.eventLog.dir hdfs://biyuzhe:9000/eventLog
spark.serializer org.apache.spark.serializer.KryoSerializer
spark.driver.memory 1g
# spark.executor.extraJavaOptions -XX:+PrintGCDetails -Dkey=value -Dnumbers="one two three"
## 安装mmlspark
#spark.jars.packages Azure:mmlspark:0.12
raini @ biyuzhe:〜$ hadoop fs -mkdir /eventLog
4.启动Spark
$SPARK_HOME/sbin/start-all.sh
5.web监控
http://biyuzhe:8080/
(六)配置Pyspark环境
1.追加配置(基于anoconda envs)
# added by Anaconda3
export ANACONDA_ROOT=/home/raini/app/anoconda3
export PATH=${ANACONDA_ROOT}/bin:$PATH
# pyspark
export PYSPARK_DRIVER_PYTHON=$ANACONDA_ROOT/bin/ipython notebook
export PYSPARK_PYTHON=$ANACONDA_ROOT/envs/py35/bin/python
export PYSPARK_DRIVER_PYTHON_OPTS="notebook"raini @ biyuzhe:〜$ source .bashrc
2.运行pyspark
raini @ biyuzhe:〜$ pyspark --packages Azure:mmlspark:0.14
自动跳转到的IPython的中,现在就可以编辑与运行代码了:

不使用的IPython的:

3.Pyspark设置指定的Python的版本
修改spark-env.sh文件,在末尾添加
export PYSPARK_PYTHON=/home/raini/app/anoconda3/envs/py35/bin/python
(完)
遇到的问题
1. Spark无法连接Hadoop异常:
错误SparkContext:91 - 初始化SparkContext时出错.java.net.ConnectException
:从biyuzhe / 127.0.1.1调用biyuzhe:8021连接异常失败: java.net.ConnectException:拒绝连接; 有关更多详细信息,请参阅:
sun.reflect
上的sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
中的sun.reflect.NativeConstructorAccessorImpl.newInstance0(本地方法)中的http://wiki.apache .org / hadoop / ConnectionRefused.DissatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
在java.lang.reflect.Constructor.newInstance(Constructor.java:423)
在org.apache.hadoop.net.NetUtils.wrapWithMessage(NetUtils.java) :792)
在org.apache .hadoop。 net.NetUtils.wrapException(NetUtils.java:732)
在org.apache.hadoop.ipc.Client.call(Client.java:1479)
在org.apache .hadoop。 ipc.Client.call(Client.java:1412)...
方法1.修改配置的端口8021(火花的默认)成9000(HDFS的默认)
方法2(待验证)./ etc / hosts中不要有:: 1的段,屏蔽掉:

六,安装Hive
MySQL的安装
sudo apt install mysql-server
一、(仅对于新安装的执行这步,已有MySQL的跳过)
重置root用户密码:
SET PASSWORD FOR 'root'@'localhost' = PASSWORD('root');
或:
update mysql.user set authentication_string=PASSWORD('root'), plugin='mysql_native_password' where user='root';
给用户赋权:
grant all privileges on *.* to 'root'@'%' identified by 'root';
grant all privileges on *.* to 'root'@'localhost' identified by 'root';(与上相仿)
更新:
flush privileges;
二、
登录MySQL:
# mysql -u root -p
建立数据库hive:
mysql> create database hive;
mysql> show databases;
修改hive数据库的字符集为latin1:
mysql> alter database hive character set latin1;
创建hive用户,并授权:
mysql> create user 'hive'@'localhost' identified by 'hive';
mysql> grant select,insert,update,delete,alter,create,index,references on metastore.* to 'hive'@'localhost';
或者:mysql>grant all privileges on *.* to 'hive'@'node1' identified by 'hive' with grant option;
注意:@后面改成你的hostname
更新:
mysql>flush privileges;
三、使用新用户登录并设置密码
$ mysql [-h master] -uhive -p (回车再回车)
mysql> SET PASSWORD FOR hive@localhost = PASSWORD('hive');
查询的MySQL的版本:
mysql>select version(); //5.7.24-0ubuntu0.18.04.1
下载MySQL的JDBC的驱动包:
http://dev.mysql.com/downloads/connector/j/
选择独立平台,下载mysql-connector-java-8.0.13.zip,复制msyql的JDBC驱动包到蜂巢的LIB目录下。
Hive安装配置
在.bashrc中添加如下:
#Hive
export HIVE_HOME = /home/raini/app/hive
export PATH = $ PATH:${HIVE_HOME}/bin
export CLASSPATH = $CLASSPATH.:{HIVE_HOME}/lib
配置hive-env.sh文件:
HADOOP_HOME = /home/raini/app/hadoop
export HIVE_CONF_DIR = /home/raini/app/hive/conf
#export HADOOP_HEAPSIZE = 512
#导入第三方lib包,参考(https://blog.csdn.net/qianshangding0708/article/details/50381966)
#export HIVE_AUX_JARS_PATH = /home/raini/app/hive/../.jar(绝对路径,多个用,分隔)
PS :(不配置该变量,仅需要将所需 jar放入新建目录 $ {HIVE_HOME}/auxlib下即可)
(可选配置):
HADOOP_HOME=/usr/local/Cellar/hadoop/3.1.1/libexec
export HIVE_CONF_DIR=/Users/zhengsiming/app/hive/conf
#export HADOOP_HEAPSIZE = 512
export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8.0_201.jdk/Contents/Home
export HADOOP_HOME=/usr/local/Cellar/hadoop/3.1.1/libexec
export HIVE_HOME=/Users/zhengsiming/app/hive
- 配置Hive的site.xml文件
(创建Hive-site.xml中所需文件夹):
raini @ biyuzhe:〜$ hadoop fs -mkdir -p /user/hive/tmp
raini @ biyuzhe:〜$ hadoop fs -mkdir -p /user/hive/log
raini @ biyuzhe:〜$ hadoop fs -mkdir -p /user/hive/warehouse
(需要给755权限):
raini @ biyuzhe:〜$ hadoop fs -chmod g + w /user/hive/tmp
raini @ biyuzhe:〜$ hadoop fs -chmod g + w /user/hive/log
raini @ biyuzhe:〜$ hadoop fs -chmod g + w /user/hive/warehouse
(一步到位):
hdfs dfs -mkdir -p /user/hive/warehouse
hdfs dfs -mkdir -p /user/hive/tmp
hdfs dfs -mkdir -p /user/hive/log
hdfs dfs -chmod -R 777 /user/hive/warehouse
hadoop fs -chmod 777 /user/hive/tmp
hdfs dfs -chmod -R 777 /user/hive/tmp
hdfs dfs -chmod -R 777 /user/hive/log(新建hive-site.xml文件):
javax.jdo.option.ConnectionURL
jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true
javax.jdo.option.ConnectionDriverName
com.mysql.cj.jdbc.Driver
MySQL-5.5之前 com.mysql.jdbc.Driver
javax.jdo.option.ConnectionUserName
hive
javax.jdo.option.ConnectionPassword
hive
hive.metastore.warehouse.dir
/user/hive/warehouse
指定Hive的数据存储目录,默认位置在HDFS的/user/hive/warehouse路径下
hive.exec.scratdir
/user/hive/tmp
hive的数据临时文件目录,默认位置为HDFS的/tmp/hive路径下
hive.querylog.location
/home/raini/app/hive/logs
这个是用于存放hive相关日志的目录,Location of Hive run time structured log file
hive.server2.logging.operation.log.location
/home/raini/app/hive/iotmp/operation_logs
Top level directory where operation logs are stored if logging functionality is enabled
hive.downloaded.resources.dir
/home/raini/app/hive/iotmp/resource_dir
Temporary local directory for added resources in the remote file system.
hive.exec.local.scratchdir
/home/raini/app/hive/iotmp/scratchdir
Local scratch space for Hive jobs
hive.cli.print.current.db
true
- (vim hive-log4j.proprties)和(vim hive-exec-log4j2.properties):
property.hive.log.dir =(/home/raini/app/app/hive/log)
#当hive运行时,日志存储的地方,(上面hive已经配置过了,所以这步跳过)
- (第一次执行,初始化):
raini@biyuzhe:~$ schematool -dbType mysql -initSchema
--(启动hive服务):
raini@biyuzhe:~$ hive --service metastore &
raini@biyuzhe:~$ hive --service metastore > /tmp/hive_metastore.log 2>&1 &
--(启动hive):
raini@biyuzhe:~$ hive
Loading class `com.mysql.jdbc.Driver'. This is deprecated. The new driver class is `com.mysql.cj.jdbc.Driver'. The driver is automatically registered via the SPI and manual loading of the driver class is generally unnecessary.
Ps:(最新的mysql驱动用的驱动名称变了,
所以改变jdbc.driverClassName= com.mysql.cj.jdbc.Driver )
--(测试):
hive (default)> create table test(id int, name string) row format delimited FIELDS TERMINATED BY ',';
OK
Time taken: 3.162 seconds
多余的:若是分布式,scp -r hive-2.3/ raini@node2:/home/app/hive之后只需做一部就可设置node2节点为客户端节点(可以在node2终端打开hive)
beeline连接hiveserver2
连接之前要先设置代理用户,可不输入用户名和密码直接回车进入。在hadoop的core-site.xml中,设置如下属性(proxyuser后面是运行hive的超级用户,raini是我的用户名):
hadoop.proxyuser.raini.hosts
*
hadoop.proxyuser.raini.groups
*
设置了以后, 无论使用什么用户登陆,都使用hive超级用户 (raini启动hiveserver2) 来代理, 使当前用户以raini的权限进行操作, 但所建立的表还是属于当前用户.
--(端口信息可以在hive-site.xml修改,默认的,可跳过):
hive.server2.thrift.port
10000
hive.server2.thrift.bind.host
localhost
--(在一个窗口中启动hiveserver2):
或放置后台:raini@biyuzhe:~/app$ hive --service hiveserver2 &

此时后台多了一个RunJar

--(启动beeline):
beeline> !connect jdbc:hive2://localhost:10000

可以看到不输入用户名密码也可以进入,(因为前面hdfs 上的文件夹/ tmp 和/ hive /仓给给了权限,可777,也可755 )
Hbase安装
(也可以使用Hbase自带zookeeper)
zookeeper安装
只需配置conf/zoo.cfg即可
zoo.cfg(单机)
# 最重要的5个 # 通常是tickTime=tickTime*initLimit 就是20000
tickTime=2000
initLimit=5
syncLimit=2
dataDir=/home/raini/app/zookeeper/dataDir
dataLogDir=/home/raini/app/zookeeper/dataLogDir
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1zoo.cfg(集群)
# 最重要的5个 # 通常是tickTime=tickTime*initLimit 就是20000
tickTime=2000
initLimit=5
syncLimit=2
dataDir=/home/raini/app/zookeeper/dataDir
dataLogDir=/home/raini/app/zookeeper/dataLogDir
# 先查看端口是否占用,或修改成12181
clientPort=2181
# 3台机器
server.1=192.168.110.1:2888:3888
server.2=192.168.110.2:2888:3888
server.3=192.168.110.3:2888:3888
#maxClientCnxns=60
#autopurge.snapRetainCount=3
#autopurge.purgeInterval=1完成~ 发送到另外两台机器。
然后:
node1的data/myid配置如下:
echo '1' > data/myid
node2的data/myid配置如下:
echo '2' > data/myid
node3的data/myid配置如下:
echo '3' > data/myid分别启动:
zkServer.sh start > /home/app/zookeeper/zookeeper.out
查看状态:
zkServer.sh status
最后:
将zoo.cfg 复制到hbase/conf/下即可。
Ps: 若第一台zoo启动后没查看到进程,可以不管它,启动完后面的机器它会自己起来的。
Hbase-env.sh
## 追加:
export JAVA_HOME=/home/raini/app/jdk
export HBASE_CLASSPATH=/home/raini/app/hbase/conf/
export HBASE_PID_DIR=/home/raini/app/tmp/pids
#使用HBase自带的zookeeper(单机环境)
export HBASE_MANAGES_ZK=true
#不使用HBase自带的zookeeper(集群环境)
export HBASE_MANAGES_ZK=false
hbase-site.xml
(单机环境):
hbase.rootdir
hdfs://biyuzhe:9000/hbase
hbase.cluster.distributed
true
hbase.zookeeper.quorum
127.0.0.1
hbase.zookeeper.property.clientPort
2181
zookeeper.znode.parent
/hbase
hbase.zookeeper.property.dataDir
/home/raini/app/tmp/hbase_zoo_dataDir
dfs.replication
1
hbase.master.maxclockskew
150000
zookeeper.session.timeout.ms
150000
(集群环境-3台):

注意:
hbase.zookeeper.property.clientPort 和 zookeeper.znode.parent 要配置好(方便以后配置janusGraph)
还有配置里使用的要么使用IP,不然全使用hostname,以免出现janusGraph(hbase-client)连接不上hbase-server
regionservers
#修改为主机名 <----建议写与hostname不同的主机ip , 不需要写master-ip在里边,因为master作为Hmaster了
node2-ip
node3-ip
启动Hbase
在node1$ start-hbase.sh
运行Hbase
$ hbase shell
HBase Shell 基本操作
status –查看HBase状态
hbase(main):001:0> status
version –查看HBase版本信息
hbase(main):002:0> version
create tablename,columnname1,…,columnnameN –创建表
hbase(main):013:0* create 'testtable','colfam1','colfam2','colfam3'
describe tablename –描述表定义
hbase(main):014:0> describe 'testtable'
list –列出所有表
hbase(main):015:0> list
put tablename,rowname,columnname,value –插入数据
hbase(main):019:0* put 'testtable','row1','colfam1','123'
hbase(main):020:0> put 'testtable','row1','colfam1:col1','456'
scan tablename –全表查询
hbase(main):021:0> scan 'testtable'
get tablename,rowname –查询表中行的数据
hbase(main):022:0> get 'testtable','row1'
count tablename –查询表中的记录数
hbase(main):023:0> count 'testtable'
delete tablename,rowname, columnname–删除一个CELL
hbase(main):041:0> delete 'testtable','row1','colfam1:col1'
disable & drop tablename –删除表
hbase(main):043:0> disable 'testtable'
hbase(main):042:0> drop 'testtable'
exists tablename –判断表是否存在
hbase(main):045:0> exists 'testtable'
disable&alter tablename –删除表中一个列族
hbase(main):008:0> describe 'testtable'
truncate tablename –清空整张表
hbase(main):005:0> truncate 'testtable'
hbase(main):016:0* disable 'testtable'
hbase(main):011:0> alter 'testtable',NAME=>'colfam1',METHOD=>'delete'
hbase(main):012:0> describe 'testtable'
hbase(main):018:0> enable 'testtable'
deleteall tablename rowname –删除表中整行
hbase(main):010:0> scan 'testtable'
hbase(main):012:0> deleteall 'testtable','row1'
Phoenix安装配置
下载:http://mirror.bit.edu.cn/apache/phoenix/
官网:http://phoenix.apache.org/#
前提:Hadoop ,zookeeper,Hbase-1.4 都安装成功
解压:$ tar -zxvf ./apache-phoenix-4.14.1-HBase-1.4-bin.tar.gz
安装:Phoenix 仅安装在Master节点
配置:
1、将 Phoenix 目录下的 phoenix-4.14.1-HBase-1.4-client.jar、phoenix-core-4.14.1-HBase-1.4.jar、phoenix-4.14.1-HBase-1.4-server.jar 拷贝到 hbase 集群各个节点 的安装目录 lib 里。
2、将 hbase 配置文件 hbase-site.xml 拷贝到 Phoenix 的 bin 目录下,覆盖原有的配置文件。
3、将 hdfs 配置文件 core-site.xml、 hdfs-site.xml 拷贝到 Phoenix 的 bin 目录下。
环境变量:
#phoenix
export PHOENIX_HOME=/home/raini/app/phoenix
export PHOENIX_CLASSPATH=$PHOENIX_HOME
export PATH=$PATH:$PHOENIX_HOME/bin修改启动文件权限:
Phoenix/bin/下 : chmod 777 psql.py和sqlline.py
启动:
重启 hbase 集群,raini@biyuzhe:~/app/phoenix$ python2 ./bin/sqlline.py biyuzhe:2181

Cassandra的安装及配置
- 安装jdk和python-2.7(建议直接安装anaconda2)
- vi .bashrc
# cassandra
export CASSANDRA_HOME=/home/raini/app/cassandra
export PATH=$CASSANDRA_HOME/bin:$PATH- 新建cassandra数据存放的文件夹(用安装包的方式就需要这一步)
可以根据磁盘情况设置这3个文件夹,但是要和cassandra.yaml里的想对应
mkdir /home/raini/app/tmp/cassandra/data
mkdir /home/raini/app/tmp/cassandra/commitlog
mkdir /home/raini/app/tmp/cassandra/saved_caches
mkdir /home/raini/app/tmp/cassandra/hintstmp/cassandra/data SSTable文件在磁盘中的存储位置,可以有多个地址
tmp/cassandra/commitlog 文件在磁盘中的存储位置.
tmp/cassandra/saved_caches 数据缓存文件在磁盘中的存储位置.保存表和行的缓存
tmp/cassandra/hints 存储提示目录
如果可能,可以考虑将tmp/cassandra/data和tmp/cassandra/commitlog设置在不同的磁盘中,这样有利于分散整体系统的磁盘I/O的压力.
- 修改con/cassandra.yaml中的一些参数
cluster_name: 'JanusGraphCassandraCluster'
hints_directory: /cassandra/hints #存储提示目录
- seeds: "127.0.0.1" #Cassandra集群中的种子节点地址,可以设置多个,用半角逗号隔开,必须是ip
listen_address: localhost #需要监听的IP或主机名。改成本机IP
start_rpc: true #是否开始thrift rpc服务器,默认false
rpc_address: localhost #Cassandra服务器对外提供服务的地址 本机ip
rpc_port: 9160 #Cassandra服务器对外提供服务的端口号 9161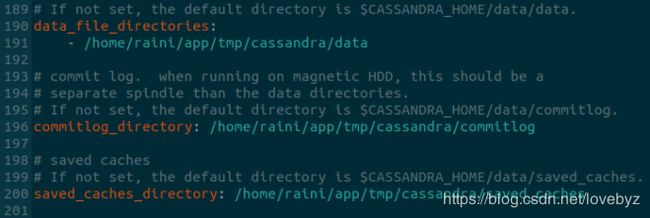
启动:
$ cassandra -f -R #启动,-f表示前台启动,-R表示以管理员身份启动
$ cassandra >> /home/raini/app/cassandra/cassandra.out & #后台启动
在某些本地化的环境中,如果得到如下错误:
expr: 语法错误
expr: 语法错误
bin/cassandra: 59: [: Illegal number:
bin/cassandra: 63: [: Illegal number:
bin/cassandra: 67: [: Illegal number:
expr: 语法错误
bin/cassandra: 81: [: Illegal number:
Invalid initial heap size: -XmsM
Error: Could not create the Java Virtual Machine.
Error: A fatal exception has occurred. Program will exit.

这种情况下,在/etc/cassandra/cassandra-env.sh中取消以下行注释即可:
#MAX_HEAP_SIZE="4G"
#HEAP_NEWSIZE="800M"将MAX HEAP SIZE 设置为不超过硬件RAM的一半,这没用。Cassandra使用Off-Heap-Storage。
简单使用
进入数据库
$ bin/cqlsh
#类似于mysql 现在还没有配置身份验证 所以暂时不需要带上用户名密码
$ ./bin/cqlsh node1 9042 # 连接到一个指定的服务器 (9042是监听端口)
thriftServer端口是9161
基本用法
在使用命令的时候记得常用tab,会有自动补齐功能。
帮助:
cqlsh> help;
cqlsh> CREATE_TABLE help;
显示当前cluster:
cqlsh> DESCRIBE CLUSTER;
显示当前存在的keyspaces:
cqlsh> DESCRIBE KEYSPACES ;
Cluster: JanusGraphCassandraCluster
这些system_traces system_schema system_auth system system_distributed自带的系统keyspaces是用来做内部管理的,有点和master,temp database类似。Cassandra使用这些keyspaces保存schema,tracing和security information。
使用keyspace和表
-Cassandra keyspace和关系型数据库的概念类似。它可以定义一个或多个(表 or column families)。
创建keyspace:
cqlsh> CREATE KEYSPACE janusgraph WITH replication = {'class': 'SimpleStrategy', 'replication_factor': '1'};
cqlsh> DESCRIBE janusgraph;
注:class代表使用什么作为replication策略,replication_factor表示这个keyspace的数据需要写到几个node上面去。在production的环境下面,一定不能只使用1个replication_factor。
切换到新建的keyspace:
cqlsh> USE janusgraph ;
在新建的keyspace里面创建表:
cqlsh:janusgraph> CREATE TABLE user ( first_name text, last_name text, PRIMARY KEY (first_name));
cqlsh:janusgraph> DESCRIBE user ;
注:也可以直接使用 CREATE TABLE janusgraph.user ( 这种语法创建表,不需要切换keyspace。
插入数据到表中:
cqlsh:janusgraph> INSERT INTO user (first_name, last_name ) VALUES ( 'zhe', 'xiao');
cqlsh:janusgraph> SELECT * FROM user ;
cqlsh:my_keyspace> DELETE last_name FROM user WHERE first_name = 'zhe';
cqlsh:my_keyspace> select * from user ;
cqlsh:my_keyspace> DELETE FROM user WHERE first_name = 'zhe';
清空或者删除表:
cqlsh:my_keyspace> TRUNCATE user ;
cqlsh:my_keyspace> DROP TABLE user ;
遇到问题
启动cassandra报错:java.lang.OutOfMemoryError: unable to create new native thread
当前会话有效设置
ulimit -u # 查看nproc
ulimit -u 65535 # 设置nproc,仅当前会话有效
全局有效
cat /etc/security/limits.d/90-nproc.conf
* soft nproc 1024
vi /etc/security/limits.d/90-nproc.conf
* soft nproc 655350
ES安装及配置
elasticsearch.yml
3台机器配置不同点1:
(node1)node.name: es-node-1
(node2)node.name: es-node-2
(node3)node.name: es-node-3
3台机器配置不同点2:
(node1)network.host: 192.168.110.21
(node2)network.host: 192.168.110.22
(node3)network.host: 192.168.110.23
3台机器配置如下:
(3个配置文件,最少可以只有两处不同,红标处--即需要修改为对应机器的参数)node1示例:
单机模式: 只需将黄线处注释掉即可。
jvm.options
修改为:
-Xms2g
-Xms2g
Ps: 数值需一样,很多人配置为机器内存的1/2
报错一:
ERROR: bootstrap checks failed
解决方案:
vim /etc/security/limits.conf //添加, 【注销后并重新登录生效】
* soft nofile 300000
* hard nofile 300000
* soft nproc 102400
* hard nproc 102400
查看是否生效
[seven@localhost ~]$ ulimit -Hn
65536
报错二:
max virtual memory areas vm.max_map_count [65530] likely too low, increase to at least [262144]
解决方案:
vim /etc/sysctl.conf //添加
fs.file-max = 1645037
vm.max_map_count=655360执行:sysctl -p
ERROR三: bootstrap checks failed
system call filters failed to install; check the logs and fix your configuration or disable system call filters at your own risk
解决方法:在elasticsearch.yml中配置bootstrap.system_call_filter为false,注意要在Memory下面:
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
ERROR四: max number of threads [1024] for user [raini] is too low, increase to at least [4096]
修改 /etc/security/limits.d/90-nproc.conf
原:
* soft nproc 1024
改为:
* soft nproc 5120Ps: Xshell连接的集群需要断开重连接才生效
启动ES:
每台机器都执行:elasticseach > ./elasticseach.out &
Accumulo安装
参考:Accumulo安装:Hbase同胞兄弟-1.9.2