【高并发专题】-JUC-AQS及拓展组件详解
本篇主要介绍AQS原理及其构建的各种同步装置和锁.
AQS是类AbstractQueuedSynchronizer的缩写,位于java.util.concurrent包下,可以用来构建锁,各种同步装置.其底层的数据结构如下图:

是基于链表实现的FIFO队列,队列中维护了等待线程的各种信息.
AQS内部使用int类型的state来表示状态,state=0表示还没有线程获取锁,1表示已有线程获取到锁,>1表示重入锁的数量.
AQS是基于模板方法模式设计的,使用者需要继承AQS并覆写其中的部分方法,子类通过父类提供的acquire和release方法来修改队列中的节点状态.
AQS可以同时实现排它锁和共享锁(独占,共享)
AQS其内部维护了一个CLH队列(https://blog.csdn.net/aesop_wubo/article/details/7533186)来管理锁,线程会尝试获取锁,如果当前线程获取锁失败,就将其状态等信息封装成一个Node节点加入到AQS提供的sync queue队列里,接下来会循环尝试获取锁,条件是为Head的直接后继节点时才会尝试,以此来保证FIFO公平性,如果失败了就会阻塞自己,直到被唤醒.当持有锁的线程释放锁后,会唤醒队列中的后继线程.
AQS提供了很多同步组件,Semaphore,CountDownLatch,CyclicBarrier,ReentrantLock.虽然这块内容我已经在多线程专题,以及面试专题里多次梳理,但其重要性依旧值得继续梳理.
Semaphore是信号量的意思,可以控制线程的并发数,当一段代码需要限制并发的线程数时可以使用,比如下面这段代码,我启动了50个线程,但每次仅允许5个线程执行sayHello方法,5个线程执行完,释放许可其它线程才可以进入继续执行,为了让效果比较明显,我让线程在执行完sayHello方法后休眠2秒,这样运行之后你就可以看到明显的效果了,你好每次只输出5个,然后停顿2秒继续输出5个...
public class AQSTest1 {
public static void main(String[] args) {
Semaphore semaphore = new Semaphore(5);
ExecutorService es = Executors.newCachedThreadPool();
for (int i = 0; i < 50; i++) {
es.execute(()-> {
try {
semaphore.acquire();
sayHello();
Thread.sleep(2000);
semaphore.release();
} catch (Exception e) {
e.printStackTrace();
}
});
}
es.shutdown();
}
public static void sayHello(){
System.out.println("你好!");
}
}CountDownLatch,可以让线程进入等待状态,直到计数器减为0,被阻塞的线程才会被唤醒,比较实用,常用来汇总各个线程执行后的结果.比如我启动多个线程去读取汇总Excel中多个sheet页中的内容:
public class AQSTest2 {
public static void main(String[] args) throws Exception {
AtomicInteger sheet = new AtomicInteger(0);
CountDownLatch latch = new CountDownLatch(5);
ExecutorService es = Executors.newCachedThreadPool();
for (int i = 0; i < 5 ; i++) {
es.execute(()-> {
try {
sheet.incrementAndGet();
System.out.println(Thread.currentThread().getName()+":读取:"+sheet+"中的数据");
Thread.sleep(2000);
latch.countDown();
} catch (Exception e) {
e.printStackTrace();
}
});
}
latch.await();
System.out.println("全部读取完毕,汇总中...");
es.shutdown();
}
}与CountDownLatch功能类似,可以重复实用的工具:
CyclicBarrier,循环屏障,相对于技术器只能用一次的场景,CyclicBarrier可以循环多次使用,其中参数parties代表需要等待的线程数量,当等待的线程数量达到该值时,await()方法后的代码才会被执行.
public class AQSTest3 {
public static void main(String[] args) throws Exception {
ExecutorService es = Executors.newCachedThreadPool();
CyclicBarrier cb = new CyclicBarrier(9);
for (int i = 0; i < 10; i++) {
es.execute(() -> {
try {
System.out.println("比赛即将开始,请所有选手就位...");
Thread.sleep(2000);
cb.await();
System.out.println("所有选手已就位,开始赛马...");
Thread.sleep(3000);
cb.await();
System.out.println("所有选手已到达终点,比赛结束...");
} catch (Exception e) {
e.printStackTrace();
}
});
}
es.shutdown();
}
}JDK通过AQS构建了各种锁,我已经专门总结过了,可以参考这篇:https://blog.csdn.net/lovexiaotaozi/article/details/90767521
Future,Callable,FutureTask.
Future可以用来获取Callable执行完成后的结果,它们一般成对使用,用callable.call()提交,用future.get()获取执行结果.
public class AQSTest4 {
public static void main(String[] args) throws Exception {
ExecutorService es = Executors.newCachedThreadPool();
Future future = es.submit(() -> {
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
return "你好!";
});
System.out.println(future.get());
es.shutdown();
}
}FutureTask 相当于是Future和Runnable的结合,用起来更加简洁方便:
public class AQSTest5 {
public static void main(String[] args) throws Exception {
ExecutorService es = Executors.newFixedThreadPool(1);
FutureTask futureTask = new FutureTask(() -> {
Thread.sleep(2000);
return "哈哈";
});
es.submit(futureTask);
System.out.println(futureTask.get());
es.shutdown();
}
}Fork/Join框架
Fork框架采取工作窃取算法,当有线程完成自身任务后,会从其他线程的任务双端队列的尾部窃取任务来执行,以此来提高线程的工作效率.
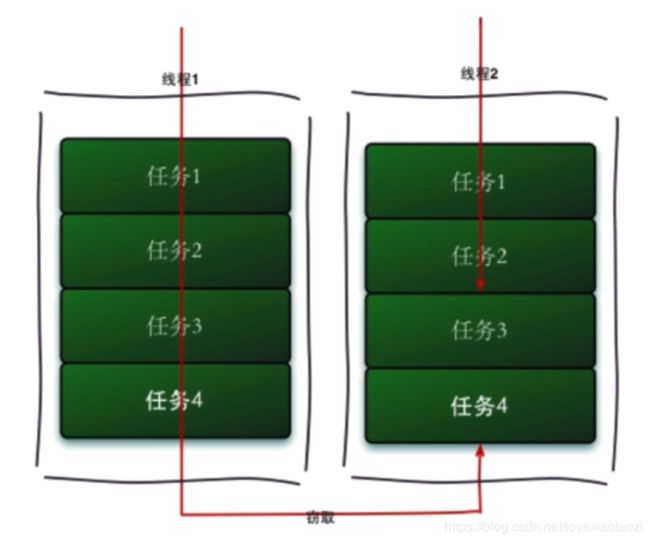
TIPS:
①一旦使用了Fork/Join框架,就不能使用其它同步机制
②所拆分的任务不能执行IO操作
③任务不能抛出检查异常,必须通过必要的代码来处理异常.
Fork/Join框架主要提供了2个类
ForkJoinPool和ForkJoinTask,ForkJoinPool是线程池,与ThreedPoolExecutor不同的是,它可以使用有限个线程完成非常多的具有父子关系的任务,但ThreedPoolExecutor不行,比如要完成200万个具有父子关系的任务时,ForkJoinPool可以用几个线程就能完成,但ThreedPoolExecutor则需要200万个线程,因为ThreedPoolExecutor无法选择优先执行子任务.
ForkJoinTask提供了fork方法实现,我们通过一个简单的例子来介绍一下Fork/Join框架的使用。需求是求1+2+3+4...+100
实现代码如下:
public class CountTask extends RecursiveTask{
private static final int THREAD_HOLD = 2;
private int start;
private int end;
public CountTask(int start,int end){
this.start = start;
this.end = end;
}
@Override
protected Integer compute() {
int sum = 0;
//如果任务足够小就计算
boolean canCompute = (end - start) <= THREAD_HOLD;
if(canCompute){
for(int i=start;i<=end;i++){
sum += i;
}
}else{
int middle = (start + end) / 2;
CountTask left = new CountTask(start,middle);
CountTask right = new CountTask(middle+1,end);
//执行子任务
left.fork();
right.fork();
//获取子任务结果
int lResult = left.join();
int rResult = right.join();
sum = lResult + rResult;
}
return sum;
}
public static void main(String[] args){
ForkJoinPool pool = new ForkJoinPool();
CountTask task = new CountTask(1,4);
Future result = pool.submit(task);
try {
System.out.println(result.get());
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
} Fork/Join框架可以提高多核CPU的使用率,从而提高代码执行效率,不过在实际开发中用得较少.
BlockingQueue阻塞队列
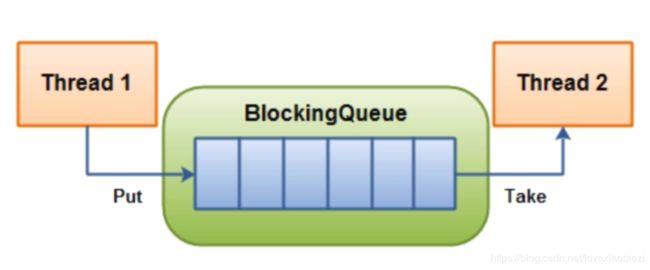
阻塞队列可以实现消费者生产者模型, 生产者向队列中添加元素,当队列被放满时生产者线程被阻塞,直到有消费者消费队列中的元素,生产者才会被唤醒.当队列中无元素或者被消费者消费空后,消费者线程被阻塞,直到有生产者添加新元素进队列.
阻塞队列提供了四种元素消费和生产的方式:

第一种,如果不能添加/获取/查询元素,就会抛出异常,对应add/remove/element方法
第二种,如果不能马上添加/获取/查询元素,就会返回一个特殊值,一般是布尔类型的值,对应offer/poll/peek方法
第三种,如果不能马上添加/获取元素,操作将会阻塞,对应put/take方法
第四种,如果不能马上添加/获取元素,操作将会被阻塞指定的时间,如果阻塞时间内还没有添加/获取成功,则返回一个布尔类型的值.
BlockingQueue有多个实现类:ArrayBlockingQueue,DelayQueue,LinkedBlockingQueue,PriorityBlockingQueue,SynchronousQueue.
ArrayBlockingQueue是一个有界的队列,底层是基于数组的阻塞队列,以FIFO形式存储数据,在创建时必须指定队列的大小.ArrayBlockingQueue的生产者和消费者使用了同一把锁,所以无法真正做到消费者和生产者并行运行.
写了一个20个生产者,1个消费者的小Demo,代码非常简单,重在理解:
public class AQSTest7 {
public static void main(String[] args) {
ArrayBlockingQueue queue = new ArrayBlockingQueue<>(5);
AtomicBoolean ok = new AtomicBoolean(true);
AtomicInteger num = new AtomicInteger(0);
ExecutorService es = Executors.newCachedThreadPool();
for (int i = 0; i < 20; i++) {
es.execute(()-> {
try {
String msg = "hi" + num.incrementAndGet();
queue.offer(msg,2,TimeUnit.SECONDS);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}
while (true){
try {
String msg = queue.poll(2,TimeUnit.SECONDS);
if (msg == null)
break;
System.out.println("获取到的消息是:"+ msg);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
es.shutdown();
}
} DelayQueue只有当元素指定的延迟时间到了,才能从队列中取出该元素,元素是按照过期时间进行排序的,队列是无限大的,生产者可以不断的生产元素而不会被阻塞,只有消费者是会被阻塞的,使用场景比较多,比如定时关闭连接,缓存处理,超时处理等.
LinkedBlockingQueue是基于链表的阻塞队列,队列中的元素达到队列的最大值才会被阻塞,该最大值可以在构造时指定.
LinkedBlockingQueue的在高并发场景下的效率较高,主要是因为消费者和生产者使用了不同的锁,可以实现异步,边生产边消费.
值得注意的是,LinkedBlockingQueue在初始化构造时应当指定队列大小,否则会采用默认最大值Integer.MAX_VALUE,如果在生产者生成速度远大于消费者消费速度的场景下,很可能会导致队列还没有达到最大值时,系统资源就被耗尽了.
PriorityBlockingQueue是基于优先级的阻塞队列,优先级的排序通过构造时传入的comparator决定,队列是无界的,所以生产者永远不会被阻塞,消费者会被阻塞,需要注意当生产者生产速度远大于消费者生产速度时,会有可能耗尽堆资源.
SynchronousQueue是无缓冲的同步等待队列,只允许放入一个元素,然后生产者会被阻塞,直到有消费者消费掉该元素.
总结:BlockingQueue为程序员提供了友好的生产者消费者工具,程序员无需关心多线程环境下线程的等待/唤醒等细节,可以把更多精力方法更高级的功能上.