深度学习加速器Layer Normalization-LN
前面介绍了Batch Normalization(BN),公众号菜单栏可以获得文章链接,今天介绍一种和BN类似的深度学习normalize算法Layer Normalization(LN)。
LN提出:BN针对一个minibatch的输入样本,计算均值和方差,基于计算的均值和方差来对某一层神经网络的输入X中每一个case进行归一化操作。但BN有两个明显不足:1、高度依赖于mini-batch的大小,实际使用中会对mini-Batch大小进行约束,不适合类似在线学习(mini-batch为1)情况;2、不适用于RNN网络中normalize操作:BN实际使用时需要计算并且保存某一层神经网络mini-batch的均值和方差等统计信息,对于对一个固定深度的前向神经网络(DNN,CNN)使用BN,很方便;但对于RNN来说,sequence的长度是不一致的,换句话说RNN的深度不是固定的,不同的time-step需要保存不同的statics特征,可能存在一个特殊sequence比其的sequence长很多,这样training时,计算很麻烦。但LN可以有效解决上面这两个问题。
LN怎么做:
LN是基于BN转化而来的,所以还是先从BN谈起。
对于一个多层前向神经网络中的某一层Hi,计算方式如公式(1)所示:
![]()
针对深度学习,存在“covariate shift”(具体定义见BN介绍文章)现象,因此需要通过normalize操作,使Hi层的输入拥有固定的均值和方差,以此削弱协方差偏移现象对深度网络的训练时的影响,加快网络收敛。normalize的对Hi层输入进行变换,如公式(2)所示:
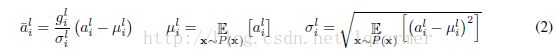
直接使用公式(2)进行normalize不现实,因为需要针对整个trainingset来进行计算,因此,BN通过mini-batch的输入样本近似的计算normalize中的均值和方差,因此成为batch-Normalization。
与BN不同,LN是针对深度网络的某一层的所有神经元的输入按公式(3)进行normalize操作:

由此可见BN与LN的不同之处在于:LN中同层神经元输入拥有相同的均值和方差,不同的输入样本有不同的均值和方差;而BN中则针对不同神经元输入计算均值和方差,同一个minibatch中的输入拥有相同的均值和方差。因此,LN不依赖于mini-batch的大小和输入sequence的深度,因此可以用于bath-size为1和RNN中对边长的输入sequence的normalize操作。
RNN中的LN操作与公式(3)稍有不同,计算公式如(4)所示:
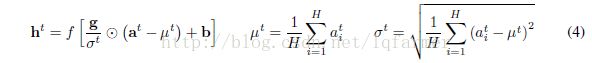
在传统RNN中,recurrent unit经过累加求和后的输入(summed input)的量级会随着训练进行发生波动,导致梯度爆炸或梯度消失发生。加入LN之后,Normalization term会对summed input的进行尺度变换,使RNN在training和inference时更加稳定。
实践证明,LN用于RNN进行Normalization时,取得了比BN更好的效果。但用于CNN时,效果并不如BN明显。
参考文献:
[1] Layer Normalization. Jimmy Lei Ba,Jamie Ryan Kiros
[2] Batch normalization: Accelerating deep network training by reducing internal covariate shift. Sergey Ioffe and Christian Szegedy.
[3] Batch normalized recurrent neural networks. C´esar Laurent, Gabriel Pereyra, Phil´emon Brakel, Ying Zhang, and Yoshua Bengio.
更多深度学习在NLP方面应用的经典论文、实践经验和最新消息,欢迎关注微信公众号“深度学习与NLP”或“DeepLearning_NLP”或扫描二维码添加关注。
