Spark学习笔记:Spark基础
目录
Spark基础
1.Spark基础入门
(1)什么是Spark
(2)Spark生态圈
(3)Spark的特点与MapReduce对比
2.Spark体系结构与安装部署
(1)Spark体系结构
(2)Spark的安装与部署
(3)Spark HA的实现
3.执行Spark Demo
(1)Spark-submit
(2)Spark-shell
(3)Spark实现WordCount
(4)Spark WordCount的Java版本
(5)Spark WordCount的Scala版本
4.Spark运行机制及原理分析
Spark基础
1.Spark基础入门
(1)什么是Spark
Spark是用于大规模数据处理的统一分析引擎
(2)Spark生态圈
Spark Core:内核
Spark SQL:用于处理结构化数据的组件,类似Hive
Spark Streaming:用于处理流式数据的组件,类似Storm
Spark MLLib:机器学习
Spark Graphx: 图计算
(3)Spark的特点与MapReduce对比
Spark的特点
1.基于内存,所以速度快,但同时也是缺点,因为Spark没有对内存进行管理,容易OOM(out of memory内存溢出),可以用Java Heap Dump对内存溢出问题进行分析
2.可以使用Scala、Java、Python、R等语言进行开发
3.兼容Hadoop
Spark与MapReuce对比
1.MapReduce最大的缺点,Shuffle过程中会有很多I/O开销,可以看到这里有6个地方会产生IO,而Spark只会在1和6的地方产生I/O,其他的过程都在内存中进行
2.Spark是MapReduce的替代方案,兼容Hive、HDFS、融入到Hadoop
2.Spark体系结构与安装部署
(1)Spark体系结构
1.主从架构:存在单点故障的问题,因此需要实现HA
2.Spark体系结构图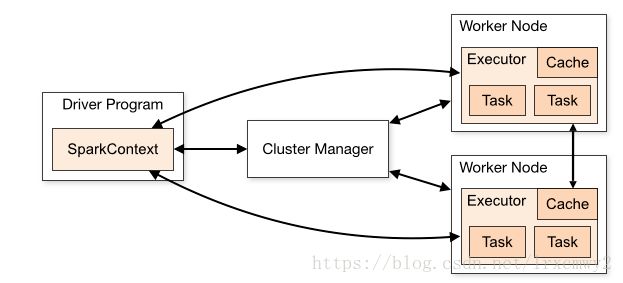
Driver Program可以理解为是客户端,而右边的可以理解为服务器端。 Cluster Manager是主节点,主节点并不负责真正任务的执行,任务的执行由Worker Node完成。
这是一张更详细的架构图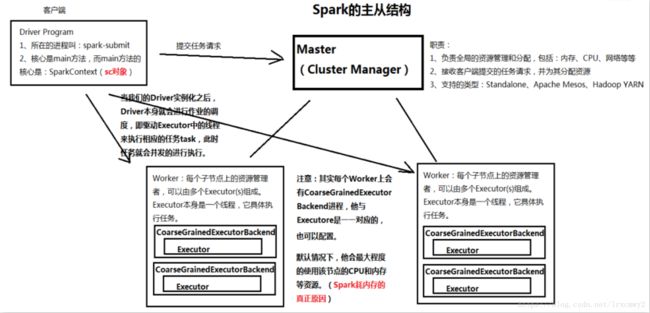
如果要搭建全分布模式,至少需要两个worker
要实现HA的话,则必须借助ZooKeeper
(2)Spark的安装与部署
Spark伪分布模式的部署
解压 tar -zxvf spark-2.2.0-bin-hadoop2.6.tgz -C ~/training/
注意:由于Hadoop和Spark的脚本有冲突,设置环境变量的时候,只能设置一个
核心配置文件: conf/spark-env.sh
export JAVA_HOME=/root/training/jdk1.8.0_144
export SPARK_MASTER_HOST=bigdata111
export SPARK_MASTER_PORT=7077
从节点的地址:slaves文件中填入主机名即可,注意hosts文件里要有对ip的解析
启动Spark集群 sbin/start-all.sh,这里我个人是给这个文件做了一个软链接start-spark.sh,因为hadoop下的启动脚本也是start-all.sh,会有冲突
Web界面:主机名:8080
Spark全分布模式的部署
全分布式的部署与伪分布式类似,在每个节点上都解压压缩包,修改conf/spark-env.sh
在主节点上的slaves文件中填入从节点的主机名
然后在每个节点上启动集群即可
(3)Spark HA的实现
1.基于文件系统的单点恢复
适用于开发和测试环境
恢复目录:保存集群的运行信息
在spark-env.sh中 增加
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=FILESYSTEM -Dspark.deploy.recoveryDirectory=/root/training/spark-2.2.0-bin-hadoop2.6/recovery"如果有运行的任务,任务信息就会被写入到恢复目录下
当节点宕掉重启之后, Spark就可以从恢复目录中的文件获取之前的状态并进行恢复
2.基于zookeeper实现Standby Master
zookeeper的功能:数据同步、选举的功能、分布式锁(秒杀)
启动zookeeper,运行zkServer.sh,然后会选举出zookeeper集群的leader和follower,节点状态可以通过zkServer.sh status查看
zookeeper数据同步功能
启动zookeeper后,在随意一个节点的zkCli.sh(即zk shell)中输入create /node001 helloworld
在其他节点的shell中get /node001都可以看得见这个虚数据helloworld
zookeeper选举功能
每个zookeeper集群都会有一个leader,其他都是follower,当leader节点宕机了,其他的follower会选举出leader
zookeeper实现Standby Master
在spark-env.sh中增加
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=bigdata112:2181,bigdata113:2181,bigdata114:2181 -Dspark.deploy.zookeeper.dir=/mysparkHA"其中Dspark.deploy.zookeeper.url参数是zookeeper集群每个节点的地址,之前有提到zookeeper需要有三个节点以上
注释下面的两行
#export SPARK_MASTER_HOST=bigdata112
#export SPARK_MASTER_PORT=7077
配置好后在两台机器上启动spark-master,在web界面上就会发现一个是ALIVE,一个是StandBy
3.执行Spark Demo
(1)Spark-submit
Spark-submit可以提交任务到Spark集群执行,也可以提交到hadoop的yarn集群执行
这里运行了一个蒙特卡罗求圆周率的Demo,运行1000次
spark-submit --master spark://centos:7077 --class org.apache.spark.examples.SparkPi /opt/software/spark-2.2.0-bin-hadoop2.6/examples/jars/spark-examples_2.11-2.2.0.jar 1000--master后面跟spark的地址,然后用--class指定类和jar包,以及运行次数
(2)Spark-shell
Spark-shell是Spark自带的交互式程序,方便用户进行交互式变成,用户可以在该命令行下用scala编写spark程序。
Spark-shell有两种运行模式:本地模式和集群模式
本地模式:不连接到集群,在本地直接执行Spark任务(local模式)
直接运行spark-shell
集群模式:连接到集群,在集群执行任务
集群模式下的shell将作为一个独立的Application链接到Master上
运行spark-shell --master spark://centos:7077
Spark的Web上可以看见
(3)Spark实现WordCount
Spark可以集成到HDFS,读取HDFS里的文件
先做一个测试文件data.txt,上传到HDFS上
执行WordCount![]()
进行单步分析![]()
可以看到一个String类型的RDD,用来存储文本信息,但这个时候并不会真正的执行![]()
执行rdd1.collect之后,才会真正的执行,获取文本文件里的字符串,放进RDD里
flatmap_是表示rdd1里的每个元素,然后使用split方法,间隔符是空格,同样的,要执行collect才算真正执行![]()
map((_,1))是把元素里的每个元素都映射成了(word,1)的kv对,这个语法糖等价于下面这条语句
reduceByKey方法是使用一个相关的函数来合并每个key的value的值的一个算子,前面的下划线可以理解为sum,用来迭代计算和,后面的下划线是每个kv对的value
总结:RDD就是一个集合,存在依赖关系,RDD有些方法不会触发计算,有些会触发计算
(4)Spark WordCount的Java版本
新建Java Project,名为ZSparkDemo,然后在project下新建folder,名为lib,然后把/opt/software/spark-2.2.0-bin-hadoop2.6/jars下的jar包复制到lib文件夹里
代码与注释如下
package demo;
import java.util.Arrays;
import java.util.Iterator;
import java.util.List;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
/*
* 打包成jar包上传到集群环境后,使用spark-submit提交任务
* spark-submit --master spark://centos:7077 --class demo.JavaWordCount /WordCount.jar hdfs://10.1.130.233:9000/input/data.txt
*/
public class JavaWordCount {
public static void main(String[] args) {
// 配置参数,setAppName方法指定app的名字
// setMaster方法用以设定Master的URL,设为local就会在本地以单线程运行
// local[4]就会在本地以4核运行,设为"spark://master:7077就会在独立集群上运行,或者不写就会默认在集群运行
//SparkConf conf = new SparkConf().setAppName("JavaWordCount").setMaster("local");
SparkConf conf = new SparkConf().setAppName("JavaWordCount");
// 创建一个SparkContext对象
JavaSparkContext sc = new JavaSparkContext(conf);
// 指定路径,读入数据,路径可以是本地路径,也可以是HDFS上的
// 这个方法返回的是一个Java的RDD,类型是String
//JavaRDD datas = sc.textFile("hdfs://10.1.130.233:9000/input/data.txt");
//这里可以不把路径写死,而是将args传入的第一个参数作为路径
JavaRDD datas = sc.textFile(args[0]);
// 分词
// 这里需要实现FlatMapFunction接口,表示要对每个传入的文本所要执行的操作FlatMapFunction
// 把U改成String,第一个String代表输入的文本,第二个String表示分词后的每个单词
JavaRDD words = datas.flatMap(new FlatMapFunction() {
@Override
// line表示每一行传入的数据
public Iterator call(String line) throws Exception {
// 因为split完之后,返回的是一个String类型的数组,所以要用Arrays的asList方法转换成是一个List,然后才能用iterator
return Arrays.asList(line.split(" ")).iterator();
}
});
// 每个单词记一次数map((单词,1)
// 这里需要实现PairFunction接口,PairFunction
// String代表传入的参数,K2,V2相当于MapReduce里Map的输出(Beijing,1),所以Key是String类型,V是Integer类型
JavaPairRDD wordOne = words.mapToPair(new PairFunction() {
@Override
public Tuple2 call(String word) throws Exception {
// Beijing --->(Beijing,1)
return new Tuple2(word, 1);
}
});
// 执行Reduce的操作,把相同单词的value做求和
// Function2,前面两个Integer表示:两个key相同的value,最后一个Integer表示运算的结果
JavaPairRDD count = wordOne.reduceByKey(new Function2() {
@Override
public Integer call(Integer a, Integer b) throws Exception {
// TODO Auto-generated method stub
return a + b;
}
});
// 触发计算
List> result = count.collect();
// 输出到Console
for (Tuple2 r : result) {
System.out.println(r._1 + ":" + r._2);
}
// 停止SparkContext对象
sc.stop();
}
}
打包成jar包后上传到集群环境, 通过spark-submit提交到集群运行
spark-submit --master spark://centos:7077 --class demo.JavaWordCount /WordCount.jar hdfs://10.1.130.233:9000/input/data.txt在集群上运行结果如下
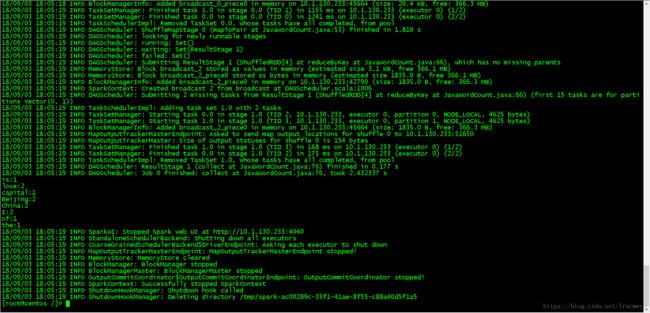
在Spark WebUI![]()
(5)Spark WordCount的Scala版本
package demo
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
object WordCount {
def main(args: Array[String]): Unit = {
//获取Spark配置,setAppName方法用来设置app的名字,setMaster设为local则为在本地运行不提交到集群
//val conf = new SparkConf().setAppName("WordCount").setMaster("local")
val conf=new SparkConf().setAppName("WordCount")
//获取SparkContext
val sc = new SparkContext(conf)
//textFile指定路径,然后做分词,转换成kv对,再reduceByKey做统计处理
//val count=sc.textFile("hdfs://centos:9000/input/data.txt").flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _)
val count=sc.textFile(args(0)).flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)
//将结果保存到HDFS目录下,repartition方法设定只返回一个RDD,saveAsTextFile设定结果保存的地址
count.repartition(1).saveAsTextFile(args(1))
//触发计算
val result=count.collect()
//输出结果
result.foreach(println)
//停止SparkContext对象
sc.stop()
}
}执行语句
spark-submit --master spark://centos:7077 --class demo.WordCount /WordCount.jar hdfs://centos:9000/input/data.txt hdfs://centos:9000/output/result运行结果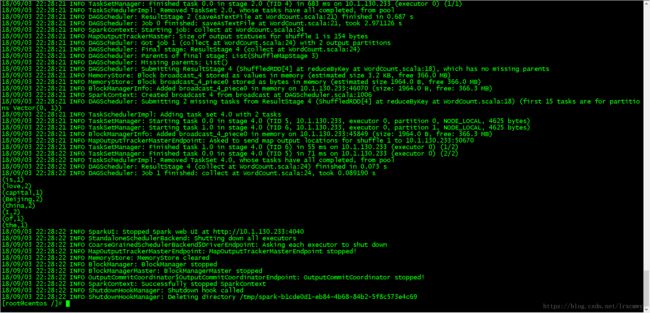 在HDFS里也可以看到生成的文件
在HDFS里也可以看到生成的文件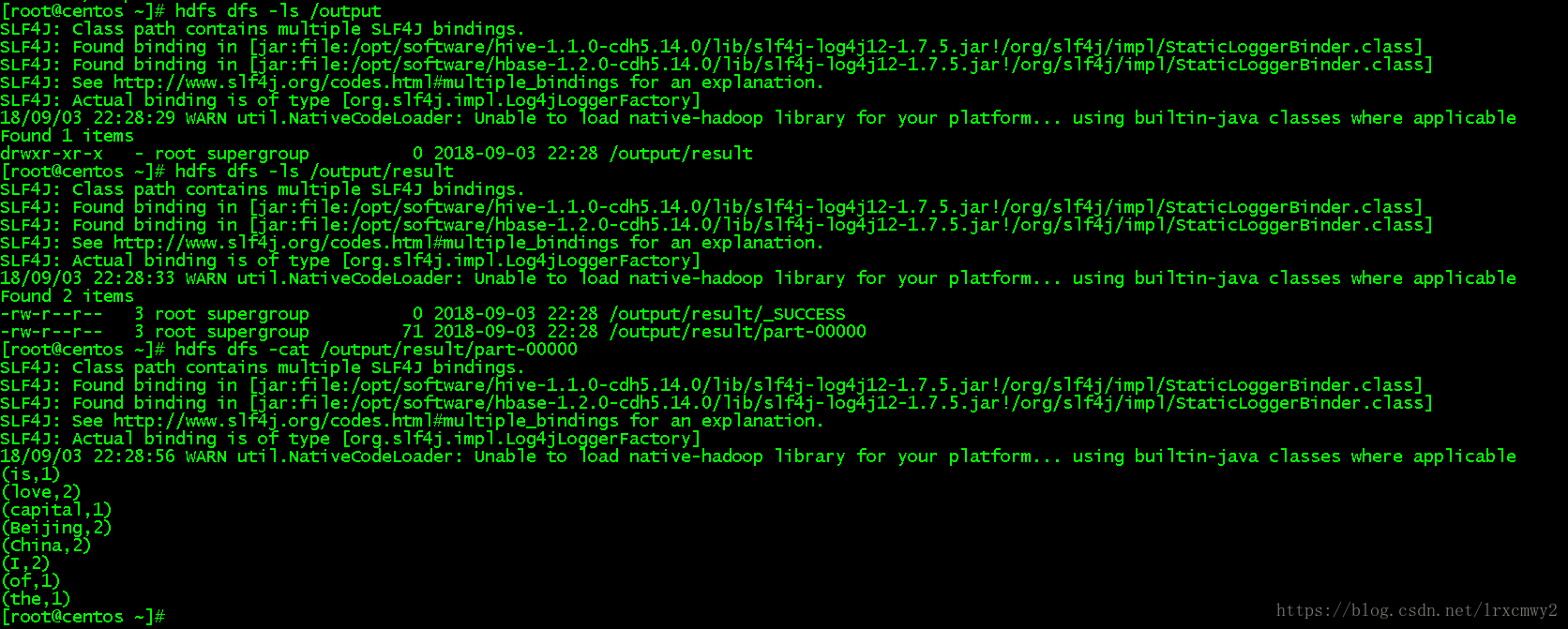
WordCount流程分析图
4.Spark运行机制及原理分析
