关于Hadoop-HA的配置---从零开始
写在文前,可能我说的有不对的地方,希望各位老鸟批评指正,本着虚心接受的态度分享这篇文章!
关于hadoop-ha大家配置的时候可能会遇到这样或者那样的报错,实在很让人头疼,因为操作有点多,也很多人不知道到底要执行的步骤顺序,今天给大家分享一下自己的愚见,我的hadoop是2.5.0的版本。
我们来看看,HA的原理图:

我的集群规划是:
如图:

这里会有两种状态
1、故障了要手动切换
2、自动故障转移
但是在下面的配置中,是完整的配置(就是包括自动故障转移的配置,但是其实操作的步骤并没有一开始就配置好自动故障转移,所以配置文件中我会标出,然后大家有几个属性先别配置)
1、前期准备环境:
三台虚拟机(最少)
hosts文件要配置好,三台都可以相互通过主机名ping通(以下是我的,三台都要一样)
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.163.103 bigdata-03
192.168.163.101 bigdata-01
192.168.163.102 bigdata-02
防火墙都关了
server iptables stop(关闭防火墙)
chkconfig iptables off(开机不自启动)
免密钥登录(这个一定要,不然你启动的时候,老是要让你输入各种密码)
其实就两条命令,但是注意,三台机器都要用相同的用户去执行,不然会出问题!!!出问题了就去把.ssh这个目录下的文件删除,重新生成
在三台机器上都执行ssh-keygen -t rsa 然后三次回车,运行结束会在~/.ssh下生成两个新文件:id_rsa.pub和id_rsa就是公钥和私钥
然后也是在三台机器上都执行:ssh-copy-id bigdata-01;ssh-copy-id bigdata-02;ssh-copy-id bigdata-03(你的公钥和私钥要发给别人,也要发给自己,切记!!)
同步时间
这个方法挺多的,大概思路就是第一台机器去访问外网同步时间,然后另外几台通过脚本去同步第一台(时间会有几秒甚至几分钟误差,这个没关系),但是其实时间不一样,我发现也没什么影响,所以。。。这里就不给出具体的方法了,大家自行百度脑补下。
2、我们来理下思路,首先给出配置文件里写什么:
最首先需要依赖zookeeper把,所以zookeeper配置如下(我有三台zookeeper):
dataDir=/opt/modules/App/zookeeper-3.4.5/zkData
server.1=bigdata-01:2888:3888
server.2=bigdata-02:2888:3888
server.3=bigdata-03:2888:3888
然后在dataDir目录下(其实就是我这里写的zkData下面)写上一个文件叫myid,里面的值就是第一台机器写1,第二台写2,第三台写3,就可以了,要跟你的server.1这里的1,对应上就好,然后开启zookeeper,看到是一台leader,两台follower,这里zookeeper开启要给他点时间,因为他要三台相互感知到,所以别急。。一般5分钟内就没问题了,如果5分钟过了,还没好的话,可以去看日志了,因为应该是报错了。
现在可以开始配置我们的hadoop集群了,第一步在hadoop-env.sh和mapred-env.sh还有yarn-env.sh中写上你的jdk路径(有可能这条属性被注释掉了,记得解开,把前面的#去掉就可以了)export JAVA_HOME=/opt/modules/jdk1.7.0_67
然后core-site.xml
fs.defaultFS
hdfs://ns1
hadoop.tmp.dir
/opt/modules/App/hadoop-2.5.0/data/tmp
hadoop.http.staticuser.user
beifeng
ha.zookeeper.quorum
bigdata-01:2181,bigdata-02:2181,bigdata-03:2181
然后是hdfs-site.xml
dfs.replication
3
property>
dfs.permissions.enabled
false
dfs.nameservices
ns1
dfs.blocksize
134217728
dfs.ha.namenodes.ns1
nn1,nn2
dfs.namenode.rpc-address.ns1.nn1
bigdata-01:8020
dfs.namenode.http-address.ns1.nn1
bigdata-01:50070
dfs.namenode.rpc-address.ns1.nn2
bigdata-02:8020
dfs.namenode.http-address.ns1.nn2
bigdata-02:50070
dfs.namenode.shared.edits.dir
qjournal://bigdata-01:8485;bigdata-02:8485;bigdata-03:8485/ns1
dfs.journalnode.edits.dir
/opt/modules/App/hadoop-2.5.0/data/journal
dfs.client.failover.proxy.provider.ns1
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
dfs.ha.fencing.methods
sshfence ----这个参数的值可以有多种,你也可以换成shell(/bin/true)试试,也是可以的,这个脚本do nothing 返回0
dfs.ha.fencing.ssh.private-key-files
/home/beifeng/.ssh/id_rsa
dfs.ha.fencing.ssh.connect-timeout
30000
dfs.ha.automatic-failover.enabled
true
然后是mapred-site.xml
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
bigdata-01:10020
mapreduce.jobhistory.webapp.address
bigdata-01:19888
然后是yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
bigdata-03
yarn.log-aggregation-enable
true
yarn.log-aggregation.retain-seconds
106800
然后slave里面写上自己的datanode的节点名称(例如:以下)
bigdata-01
bigdata-02
bigdata-03
注:只要配置一台,配置完了,把配置分发给其他机器,使用如下命令(scp命令):
提醒下,你发送前可以把hadoop中的share/doc这个目录下的东西删掉,因为是些帮助文档,太大了,影响传输速度所以。。。rm -rf share/doc
scp -r hadoop2.5.0/ bigdata-02:/opt/modules/
scp -r hadoop2.5.0/ bigdata-03:/opt/modules/
-----------------好,配置就给到这里-----------------------
2、启动过程
1)首先zookeeper已经启动好了吧(三台都要启动)开启命令 bin/zkServer.sh start
2)启动三台journalnode(这个是用来同步两台namenode的数据的)
sbin/hadoop-deamon.sh start journalnode
3)操作namenode(只要格式化一台,另一台同步,两台都格式化,你就做错了!!)
格式化第一台:bin/hdfs namenode -format
启动刚格式化好的namenode:sbin/hadoop-deamon.sh start namenode
在第二台机器上同步namenode的数据:bin/hdfs namenode -bootstrapStandby
启动第二台的namenode:sbin/hadoop-deamon.sh start namenode
4)查看web(这里应该两台都是stanby)
http://bigdata-01:50070
http://bigdata-01:50070
5)然后手动切换namenode状态
手动切换namenode状态(也可以在第一台切换第二台为active,毕竟一个集群)
$ bin/hdfs haadmin -transitionToActive nn1 ##切换成active
$ bin/hdfs haadmin -transitionToStandby nn1 ##切换成standby
注: 如果不让你切换的时候,bin/hdfs haadmin -transitionToActive nn2 --forceactive
也可以直接通过命令行查看namenode状态, bin/hdfs haadmin -getServiceState nn1
--------------------------到这里你的手动故障转移已经配置成功了-----------------------------------------
6)这时候就应该配置自动故障转移了!(其实完整的配置我在上面已经给过了)首先你要把你的集群完整的关闭,一定要全关了!!
自动故障转移的配置其实要在zookeeper上生成一个节点 hadoop-ha,这个是自动生成的,通过下面的命令生成:
bin/hdfs zkfc -formatZK
然后你登录zookeeper的客户端,就是bin/zkCli.sh里面通过 “ls /” 可以看到多了个节点
这时候讲道理集群应该是没问题了!
你可以直接通过sbin/start-dfs.sh去启动hdfs,默认会启动zkfc的,其实就是一个自动故障转移的进程,会在你的namenode存在的两台机器上有这么一个节点。
等到完全启动了之后,就可以kill掉active的namenode,你就会发现stanby的机器变成active,然后再去启动那台被你kill掉的namenode(启动起来是stanby的状态),然后你再去kill掉active,stanby的机器又会变成active,到此你的HA自动故障转移已经完成了。
这是官网的帮助文档:http://hadoop.apache.org/docs/r2.5.2/hadoop-project-dist/hadoop-hdfs/HDFSHighAvailabilityWithQJM.html
后话:其实也可以做resourcemanager的HA,但是其实你能搭出namenode的HA,对于你来说,resourcemanager的HA就很简单了。
====================分割线===========================
然后我们再来看下resourcemanager的HA官网文档:http://hadoop.apache.org/docs/r2.5.2/hadoop-yarn/hadoop-yarn-site/ResourceManagerHA.html
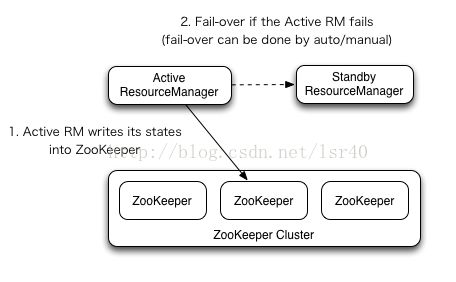
所以当看到如上的图时,应该想到resourcemanager的HA也是要依赖zookeeper的
集群规划
其实就跟上面一样,只是我在第三台机器上也启动一个resourcemanager的备用节点
配置:
修改yarn-site.xml文件
yarn.resourcemanager.ha.enabled
true
yarn.resourcemanager.cluster-id
rmcluster
yarn.resourcemanager.ha.rm-ids
rm1,rm2
yarn.resourcemanager.hostname.rm1
bigdata-02
yarn.resourcemanager.hostname.rm2
bigdata-03
yarn.resourcemanager.zk-address
bigdata-01:2181,bigdata-02:2181,bigdata-03:2181
yarn.resourcemanager.recovery.enabled
true
yarn.resourcemanager.store.class
org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore
将yarn-site.xml文件分发到其他主机上
$ scp yarn-site.xml bigdata-02:/opt/modules/hadoop-2.5.0/etc/hadoop/
$ scp yarn-site.xml bigdata-03:/opt/modules/hadoop-2.5.0/etc/hadoop/
启动ResourceManager
在bigdata-02上:sbin/start-yarn.sh
在bigdata-03上:
sbin/yarn-daemon.sh start resourcemanager
bigdata-01:
14168 DataNode
14338 JournalNode
15276 Jps
15241 NodeManager
14071 NameNode
12151 QuorumPeerMain
14485 DFSZKFailoverController
bigdata-02:
10094 ResourceManager
10183 NodeManager
10213 Jps
9212 DataNode
9279 JournalNode
9143 NameNode
8136 QuorumPeerMain
bigdata-03:
7177 Jps
6449 DataNode
5935 QuorumPeerMain
7147 ResourceManager
6512 JournalNode
7020 NodeManager
观察web 8088端口
当PC02的ResourceManager是Active状态的时候,访问PC03的ResourceManager会自动跳转到PC02的web页面
测试HA的可用性
./yarn rmadmin -getServiceState rm1 ##查看rm1的状态
./yarn rmadmin -getServiceState rm2 ##查看rm2的状态
然后你可以提交一个job到yarn上面,当job执行一半(比如map执行了100%),然后kill -9 掉active的rm
这时候如果job还能够正常执行完,结果也是正确的,证明你rm自动切换成功了,并且不影响你的job运行!!!
结束。。。。。。。。
后话:
其实正常情况下,主节点是不会直接坏掉的(除非机器坏掉,那我无话可说),往往是比如某个进程占用cpu或者内存极大,有可能被linux直接kill掉
这种时候,ha并没有那么灵敏,就是说,不一定能马上切换过去,可能有几分钟延迟,所以我们应该做的是避免一些主节点挂掉的情况。
所以可以使用spark或者storm做预警系统,当hadoop的日志文件里面出现warning的时候,能够实时报警(比如向维护人员发短信,发邮件之类的功能)
在事故发生之前,处理可能发生的故障!
再次声明,如果本文有什么说的不对之处,希望大神们可以指出!!谢谢各位~