Druid 消费一个 kafka topic 发送到不同数据源
文章目录
- 背景
- 解决办法
- 一. 过滤标识在消息体中
- 二. 过滤标识在 header 中
- 源码修改逻辑
背景
数据采集时,为了避免在 kafka 中创建大量的 Topic ,采集时会将小的数据源写入一个共享 Topic 中,以某个字段作为标识。这里有两种方式:
- 直接将标识写入消息体中
- 将标识写入 record header 中 (kafka 0.11版本后支持)
Druid 使用 druid-kafka-indexing-service 消费该 Topic 时如何根据 code 写入不同的 druid 数据源中?
本文基于 druid-0.14.0-incubating 版本实现。
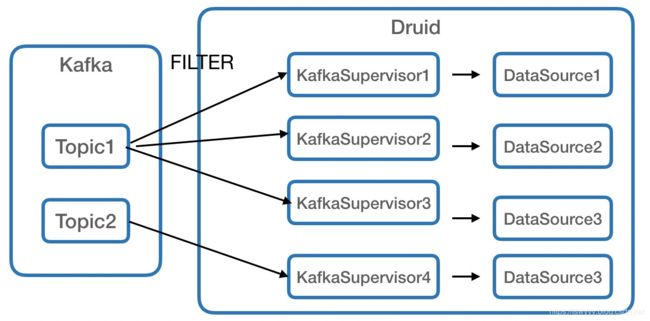
解决办法
一. 过滤标识在消息体中
这种方式 kafka-index-server 支持原始解析,在数据导入时使用 JSON Flatten Spec 对嵌套 Json 进行转换,使用 Transform Specs 对字段进行过滤即可。
消息体:其中 code 字段为标识符,msg 为真正的消息体
{
"DL_CODE": "code1",
"msg": {
"ts": "1554345838000",
"value": "v1"
}
}
任务描述: 将 DL_CODE = code1 过滤出来并打平 msg 字段,ts字段 作为时间戳,value 字段作为维度值。
{
"type": "kafka",
"dataSchema": {
"dataSource": "share_code1",
"parser": {
"type": "string",
"parseSpec": {
"format": "json",
"flattenSpec": {
"fields": [{
"type": "path",
"name": "ts",
"expr": "$.msg.ts"
},
{
"type": "path",
"name": "value",
"expr": "$.msg.value"
}
]
},
"timestampSpec": {
"column": "ts",
"format": "auto"
},
"dimensionsSpec": {
"dimensions": ["value"]
}
}
},
"transformSpec": {
"filter": {
"type": "selector",
"dimension": "code",
"value": "code1"
}
},
"granularitySpec": {
"type": "uniform",
"segmentGranularity": "hour",
"queryGranularity": "none"
}
},
"ioConfig": {
"topic": "metrics",
"consumerProperties": {
"bootstrap.servers": "dp88:9092",
"group.id": "kafka-indexing-service"
},
"taskCount": 1,
"replicas": 1,
"taskDuration": "PT1H"
}
}
二. 过滤标识在 header 中
将过滤标识记录在 record header 中可以避免对消息体本身进行入侵,不过 kafka-index-server 本身并不支持对 header 的过滤,可以通过修改 druid 源码的方式实现
消息体本身:
{
"ts": "1554345838000",
"value": "v1"
}
为消息体增加额外 header 信息, “DL_CODE”
new RecordHeader("DL_CODE", "code2".getBytes())
源码修改逻辑
- 修改 kafka-indexing-service pom.xml ,将 kafka 依赖版本提高到 1.0 (默认为 0.10,在 0.11 后才支持 record header 功能)
- 定义 header 过滤参数格式,消费时增加一段逻辑判断,增加参数的方式有不少,下面说两种
- 较为正规的方式是修改 KafkaSupervisorSpec 的内容,扩展新的参数信息,不过该方式改动代码量较大
- 该改动合进社区的可能性不大,因此可以只需要修改
KafkaRecordSupplier一个文件,通过在ioConfig.consumerProperties增加相应字段,并在poll方法中实现相应过滤逻辑即可(这种方式实现并不优雅,胜在修改代码量较少,实现方便)
例如增加了 header.filter.* 字段,运行时会首先检测是否包含相应配置,如果没有则走默认的消费逻辑,其中 header.filter.key 为过滤字段,header.filter.value 为过滤值。
"ioConfig": {
"topic": "metrics",
"consumerProperties": {
"bootstrap.servers": "...",
"group.id": "kafka-indexing-service",
"header.filter.key":"DL_CODE",
"header.filter.value":"code1"
}
从 web console 上可以看到,已经根据不同的 header 信息,写入了不同的 resource
