centos6.5搭建Hadoop集群
centos6.5搭建Hadoop集群
准备工作
CentOS-6.5-x86_64-bin-DVD1.iso
下载地址:http://vault.centos.org/6.5/isos/x86_64/
linux编译后的Hadoop安装包: hadoop-2.7.4.tar.gz
链接:https://pan.baidu.com/s/1SxV9aG6Njknw4IM-ZdmDGw 提取码:34np
jdk: jdk-8u65-linux-x64.tar.gz
链接:https://pan.baidu.com/s/1Okg_edKw3KuMOhIFRF2zeg 提取码:cy4k
创建三个虚拟机
通过ifconfig | more 命令查看各个虚拟机的ip地址
ifconfig | more
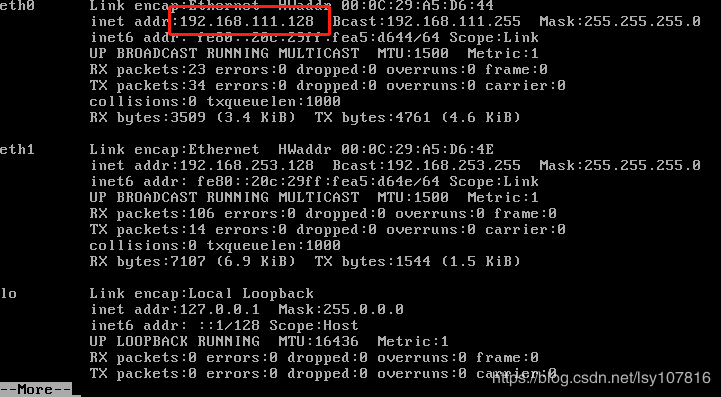
修改主机名和IP的映射关系
在三台虚拟机上都修改hosts文件
vi /etc/hosts
192.168.111.128 node-1
192.168.111.129 node-2
192.168.111.130 node-3
关闭各个虚拟机的防火墙
#查看防火墙状态
service iptables status
#关闭防火墙
service iptables stop
#查看防火墙开机启动状态
chkconfig iptables --list
#关闭防火墙开机启动
chkconfig iptables off
配置ssh免登陆
在node-1虚拟机上输入如下命令
#生成ssh免登陆密钥
ssh-keygen -t rsa (回车)
#将公钥拷贝到要免密登陆的目标机器上(包括本机)
ssh-copy-id node-1
ssh-copy-id node-2
ssh-copy-id node-3
同步集群时间
常用的手动进行时间的同步
date -s "2017-03-03 03:03:03"
或者网络同步:
yum install ntpdate
ntpdate cn.pool.ntp.org
安装步骤
只需要在node-1上安装,然后发到其他的机器上即可
安装jdk1.8
#先卸载open-jdk
java -version
rpm -qa | grep java
rpm -e --nodeps java-1.7.0-openjdk-1.7.0.45-2.4.3.3.el6.x86_64
rpm -e --nodeps java-1.6.0-openjdk-1.6.0.0-1.66.1.13.0.el6.x86_64
#上传、解压tar包
tar -zxvf jdk-8u65-linux-x64.tar.gz
#配置环境变量
vi /etc/profile
#结尾添加
export JAVA_HOME=/root/apps/jdk1.8.0_65 #jdk的安装目录
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
#刷新配置
source /etc/profile
#检查是否安装成功
java -version

安装hadoop2.7.4
#上传编译的Hadoop安装包
tar -zxvf hadoop-2.7.4.tar.gz
修改配置
配置Hadoop文件
hadoop2.x的配置文件目录:$HADOOP_HOME/etc/hadoop
修改hadoop-env.sh
vi hadoop-env.sh
#写入jdk的安装位置
export JAVA_HOME=/root/apps/jdk1.8.0_65
修改core-site.xml
vi core-site.xml
#在中加入如下配置
fs.defaultFS
hdfs://node-1:9000
hadoop.tmp.dir
/opt/data/Hdata
运行产生文件只需要在namenode,也就是master上配置,不需要创建出Hdata文件夹,在初始化Hadoop时会自动创建出来
修改hdfs-site.xml
vi hdfs-site.xml
#在中加入如下配置
dfs.replication
2
dfs.namenode.secondary.http-address
node-2:50090
修改mapred-site.xml
#先将mapred-site.xml.template重命名
mv mapred-site.xml.template mapred-site.xml
vi mapred-site.xml
#在中加入如下配置
mapreduce.framework.name
yarn
修改yarn-site.xml
vi yarn-site.xml
#在中加入如下配置
yarn.resourcemanager.hostname
node-1
yarn.nodemanager.aux-services
mapreduce_shuffle
修改slaves
vi slaves
#先删除原来的localhost 再添加三台机器的主机名
node-1
node-2
node-3
将hadoop添加到环境变量
vim /etc/proflie
export HADOOP_HOME=/root/apps/hadoop-2.7.4 #hadoop的安装目录
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile
将jdk hadoop 环境配置文件发送到其他机器
scp -r /root/apps//root/apps/jdk1.8.0_65/ root@node-2:/root/apps/
scp -r /root/apps//root/apps/jdk1.8.0_65/ root@node-3:/root/apps/
scp -r /root/apps/hadoop-2.7.4/ root@node-2:/root/apps/
scp -r /root/apps/hadoop-2.7.4/ root@node-3:/root/apps/
scp -r /etc/profile/ root@node-2:/etc/
scp -r /etc/profile/ root@node-3:/etc/
#所有机器刷新环境配置
source /etc/profile/
格式化namenode
只需要在master机器上进行格式化!!!!!!
hdfs namenode -format 或者 hadoop namenode -format
如果出错需要查看错误并对照如上的配置进行修改,再进行格式化
启动hadoop并测试
#hadoop2.x的启动文件目录:$HADOOP_HOME/sbin/
#先启动HDFS
start-dfs.sh
#再启动YARN
start-yarn.sh
或者
start-all.sh
stop-all.sh
同时还需要启动历史服务
mr-jobhistory-daemon.sh start historyserver
验证是否安装成功
#输入jps命令 查看node-1
jps
27408 NameNode
28218 Jps
27643 SecondaryNameNode
28066 NodeManager
27803 ResourceManager
27512 DataNode
管理页面(使用node-1的地址访问)
http://192.168.111.128:50070 (HDFS管理界面)
http://192.168.111.128:8088 (MR管理界面)
运行Hadoop 自带的mapreduce 程序example
cd hadoop-2.7.4/share/hadoop/mapreduce/
#使用如下命令运行计算得出圆周率
hadoop jar hadoop-mapreduce-examples-2.7.4.jar pi 20 50