基于域名的恶意网站检测
基于域名的恶意网站检测
- 0x00. 数据来源
- 0x01. 基于网页内容的判别方法
- 0x02. 基于域名数据的判别方法
- 0x03. 参考文献
0x00. 数据来源
根据老师给的 300w 域名列表爬到的相应 DNS 响应数据。
0x01. 基于网页内容的判别方法
-
数据获取
考虑到爬取执行的时间,首先对300w个域名进行数据清洗。
去掉重复的请求以及一些不指向具体网页的域名, 这类域名在请求中频繁出现, 包括网易的DNS检测域名xx.netease.com, 艾瑞数据在视频等网站中记录用户行为使用的域名xx.irs01.com, 即时通讯软件向服务器拉取数据使用的域名xx.imtmp.net, 反向PTR查询使用的域名xx.in-addr.arpa等;
去掉一些知名域的子域名, 如xx.qq.com, xx.gov.cn等.
然后通过爬虫爬取剩余网站列表的内容,在爬取时,对http和https都无法访问的网站(包括浏览器不能建立连接/404error/无文本内容等情况),尝试访问该请求的CNAME记录,也就是别名; 若仍无法访问再请求该域名的上层次级域, 尽量爬取到内容。
获取网页源代码后遍历其标签树, 得到其中所有 和 标签之间的文本信息, 使用结巴分词模块把文本切分成词语, 同时去除空格/换行符/数字/标点符号和停用词. -
根据之前项目得到一个赌博/色情网站的常用关键词列表。

-
用脚本和人工的方法筛选出部分赌博/色情网站页面, 作为训练数据

-
特征提取
常见的提取文本特征的方法有one-hot和TF-IDF两种, 与将词频计算在内的TF-IDF方法相比, one-hot只考虑了词语的出现与否(本项目采用one-hot编码)
在我们的项目中已经生成关键词列表(设长度为n), 对于每一个网页生成一个长度为n的数组, 遍历其词语列表, 若与关键词列表中的项匹配, 则将该关键词对应的位置1 -
模型建立
使用基于tensorflow的keras建立全连接神经网络, 其结构如下: -
模型训练
采用k折训练方法, 因为训练样本太少, k折验证可以提升小训练集在神经网络中的表达能力 -
计算模型结果
根据上一步的模型训练结果对爬取到的网页数据进行判断, 并将分类结果写入结果文件。
0x02. 基于域名数据的判别方法
参考两篇论文中对域名数据特征的选择, 可以分为两个方面, 一方面是词法特征, 另一个方面是网络属性, 以下先对所有的属性进行汇总:

以下是对两篇论文中域名数据的汇总和筛选:

提取基于网页内容的判别结果中的数据作为黑名单, 以及在判别结果中出现的部分alextop域名作为白名单, 进行以上特征的统计分析:
第一个是域名长度的统计, 可以看出与正常域名相比, 赌博色情域名的长度曲线更尖锐, 往往集中于10到15的长度

第二个是对分隔符’.'的出现次数统计, 可以看出赌博色情网站比正常网站的分隔符略多

第三个是对特殊字符的出现频率检测, 在这一项上两者没有表现出特别大的区别
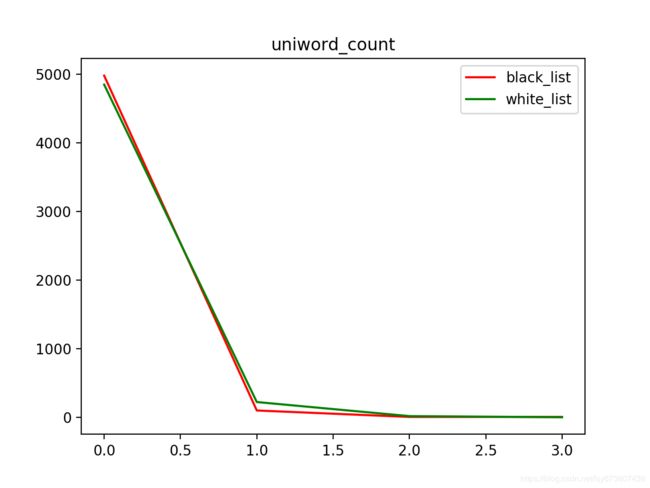
第四个是数字占域名总长度比例的统计, 对正常域名来说, 数字的比例几乎都小于0.1, 而赌博色情网站的比例则分布的比较平均
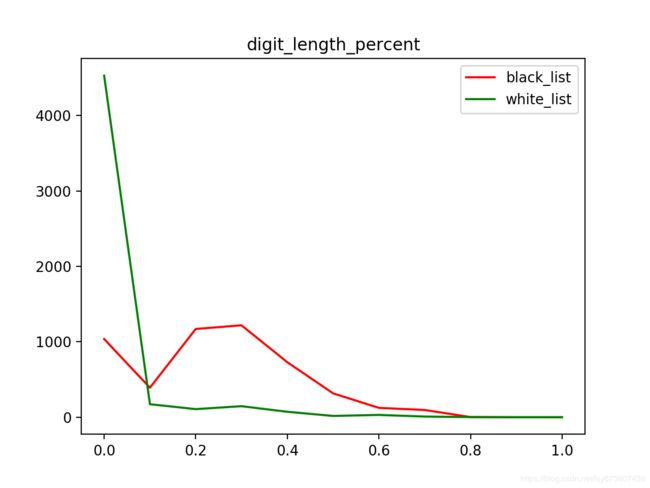
第五个是分隔符内数字个数的最大值, 它与上一项的主要差别在于与总长度无关, 同样的, 对正常域名来说, 很少出现大于2个的数字, 而赌博色情域名则较长出现多个数字
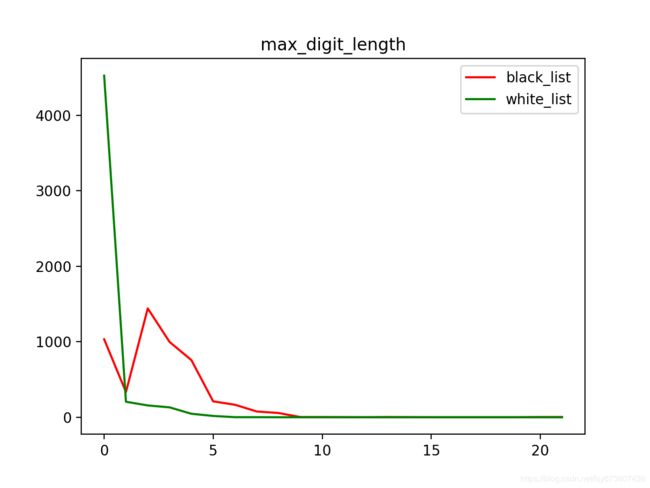
第六个是分隔符间的最大长度, 结果与域名总长度类似

第七个是数字字母的转换频率, 如a11b的转换频率就是2, 这一项正常域名和赌博色情域名的差别也比较大, 正常域名的切换频率普遍都比较小,而赌博色情域名则大多有1-3次的转换频率

从以上结果可以看出, 在长度、字母/数字数量和出现频率等方面, 正常域名和赌博色情域名均表现出了差别。
再从网络特征方面来看, 对白名单和黑名单中的域名进行进一步的请求探测(使用dnspython库, 最新stable版本1.15.0 更新于sep 2016):
dnspython的resolver模块提供了dns查询的借口—query方法, 可以指定查询类型, 如A, CNAME, AAAA等, 查询结果可能为NoAnswer(无响应), NXDOMAIN(域名不存在), TimeOut(请求超时)等。我们对黑名单和白名单中的所有域名进行了请求, 得到了它们特征之间的对比图像:
首先是TTL值, 前一张图片是重新请求的黑名单与白名单的TTL值, 可以看出黑名单的值明显较为分散

但是对于五个月前的请求值, 又发现白名单的请求值较为分散(因此这个特征有待商榷):

而对于请求类型来说, 明显可以看出白名单中域名的类型分布更加分散, 这是因为公司和机构有更多的资金去进行优化, 而赌博色情网站大多为了盈利, 而且域名时常有变动, 不会进行较全面的映射。

0x03. 参考文献
1. Identifying Gambling and Porn Websites with Image Recognition
这篇文章里中用截图的方式对整个网页的内容进行抓取(截图的代码可以参考:https://blog.csdn.net/qiqiyingse/article/details/62896264)
然后使用SURF算法提取特征点(SURF算法:https://blog.csdn.net/tengfei461807914/article/details/79177897)
特征点聚类后建立BoW词袋模型(这是一个通过BoW搜索同类图像的代码:http://yongyuan.name/blog/CBIR-BoW-for-image-retrieval-and-practice.html)
最后用SVM(支持向量机)做监督学习
2. An efficient scheme for automatic web pages categorization using the support vector machine(New Review of Hypermedia & Multimedia,2016)
首先对先前的分类方法进行了评估,提出在小训练集上svm的表现比贝叶斯好
然后提出在html5出现之后,之前的基于网页标签的特征提取需要进行改进,并提出了新的方法
最后用svm对网页进行分类,并做出评估
3. LWCS: a large-scale web page classification system based on anchor graph hashing
文章介绍了LWCS这个大规模网页分类系统的组成和工作原理
第一步是网页爬虫,使用heritrix这个基于Java的开源爬虫,改为数据库初始化,增加了筛选重复网页的过滤器,重写了工作队列
第二步是对爬下来的原始数据去噪, 然后使用NLPIR将文本内容分割为短语
第三步是特征选择,采用tf-idf方法(https://blog.csdn.net/allenshi_szl/article/details/6283375) 选择每个类别的前500个词语
第四步是锚点图哈希, 用K均值聚类方法生成锚点, 以及最后的哈希码
第五步是使用KNN分类器计算每个需要判别的网页与训练集中网页的相似度, 并把它归为相似度最大的一类
4. Building a Dynamic Reputation System for DNS
基于被动DNS信息搜集的DNS信誉评判系统, 可以生成一个动态的域名黑名单, 可检测出最新生成的恶意域名
其数据来自美国两个州的骨干网DNS…
以上整理并转自我的个人 GitHub 账号,如需转载请注明出处,谢谢 !