私有容器云与devops流水线
容器云与DevOps流水线
- 1.龙腾出行的IT系统架构演变历程
- 2.利用kubernetes搭建容器云平台
- 3.开发框架的变迁
- 4.devops流水线设计
- 5.运维监控平台
- 6.平台整体架构
1.龙腾出行的IT系统架构演变历程

2016年之前,我们有3种开发平台,java .net php,java和.net所占业务系统几乎各占一半,但.net平台在服务端架构方案比较欠缺,虽早已使用WCF进行分布式开发,但并不能跨平台,微软的闭源政策导致很多新技术不能友好兼容,在15年虽已实行开源政策,但时间还是太晚,且国内市场主流还是java系,因此决定全部转型java。
在dubbo时代,虽然开发业务效率有一定提升,但跟WCF一样,服务对平台敏感,难以简单复用,在提供对外服务时,都会以REST的方式提供出去,另外框架对服务侵入性较大,不能很好的支撑后续技术发展,期间我们也有根据thrift+zookeeper自研rpc框架,并且考虑支持多语言平台,但难度较高,团队规模也不允许,所以早早放弃,尽量使用开源平台,此时我们对docker、kubernetes进行调研,因此打开了另一扇大门,Kubernetes的功能足够炫!
2.利用kubernetes搭建容器云平台
kubernetes-容器编排的王者,容器云的首选方案,对虚拟化平台的革新功能:
- 资源调度
- 弹性伸缩、自动扩展
- 资源高利用率
- 负载均衡
- 资源基本监控
- 容灾备份
- 滚动更新
- 日志访问
- 自检和自愈
等等以上功能是在虚拟化平台中缺失或需要花时间实现的功能,但作为kubernetes平台的基础功能,大大简化了构建工作,提升开发运维效率,kubernetes各组件功能如图:
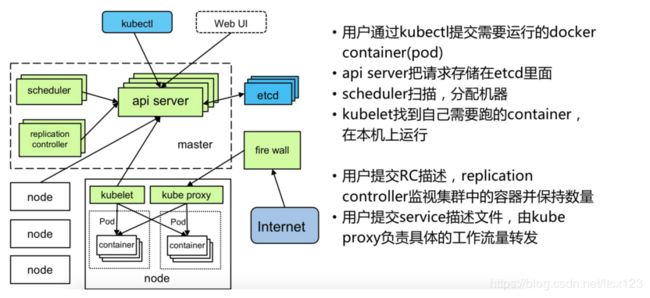
2017-2018年间IaaS/PaaS、docker、微服务、互联网架构等等各种概念侵袭,收到一波波的洗礼,我们完成了k8s从无到有并应用至生产,SOA/微服务的业务边界划分,并推行了前后端分离开发,奠定业务与人员架构基础,使前后端可并行开发,更好的支撑后续业务、技术发展,人员更精于自身专业方向。
目前我们的服务器在IDC环境中,已有VMware虚拟化平台,因此在虚拟机上搭建私有容器云是首选方案。
kubernetes 高可用采用官方推荐方案,整体搭建采用Keepalived+Nginx+Kubernetes+Calico,基于Kubeadm方式安装1.11.1版本,3Master+3Etcd+12Node节点,整体流程图:

高可用集群采用1主2热备,将keepalived 的VIP绑定到VM网卡上,当Master因故障宕机,另外两个master会根据keepalived配置的优先级接管VIP,从而起到灾备作用,另外将kube-proxy的serverIP换成Keepalived生成的VIP和自定义端口号,通过nginx转发至3个kube-apiserver,实现3master参与负载。
kubeadm-ha已经完全可以在生产环境使用,当master故障无法恢复时,可以快速加入一个新master节点,保障集群可靠性。
Etcd采用集群内3节点方案,kubeadm新版本可以友好支持Etcd-SSL的操作,当etcd故障时,通过kubeadm可以快速将新节点加入集群。
平台经过多次灾备演练,目前稳定可靠,如图大家应该比较熟悉:
我们采用ingress-nginx来取代VM上面的nginx,服务内部通讯采用k8s推荐的coredns,通过configmap方式配置DNS域名解析,取代原来挂载宿主机/etc/hosts方式。
外网访问,内网集群将Service以NodePort方式暴露端口,通过负载均衡器进行转发。
3.开发框架的变迁
根据kubernetes优秀的设计思想,开发也有相应的调整,新业务统一采用React+Spring Boot进行开发,因此我们的开发平台如下:
-
nodejs负责Web/H5前端
-
Android 、Ios 移动端
-
Java/Spring Boot 负责后端业务开发
一张图看懂开发架构:
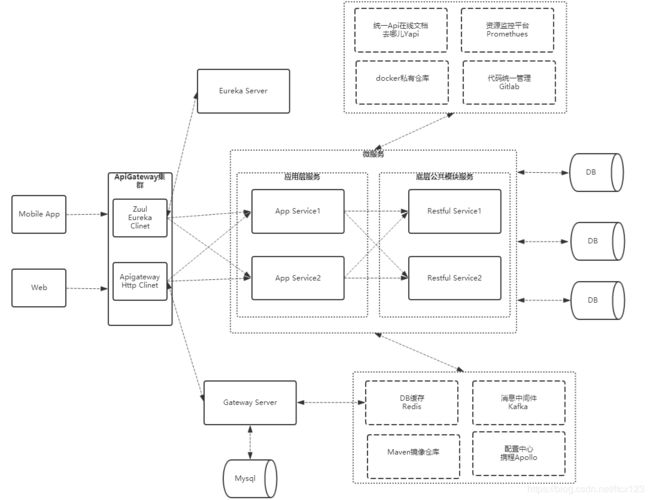
在应用Spring Cloud Netflix套件时,Eureka安装在集群外的VM上,服务注册Eureka默认读取的是hostIP,在k8s上pod被分配的虚拟IP在集群外部无法访问,我们尝试过多种解决方案,例如挂载Volume方式,写入宿主机IP到容器内的env变量,最终还是统一将注册Eureka Clinet方法重写,将注册服务地址改为ingress配置的coredns域名,集群外部访问成功
在分布式微服务中,各服务都有一套独立的配置,Spring框架尤以面向接口编程思想贯穿整个项目工程,配置项众多,我们选用携程Apollo配置中心来替代properties,多个服务可共享一个namespace配置,解决复杂而繁琐的配置问题,配置中心已经上升到整个架构层面的作用
API统一接口文档采用去哪儿开源的Yapi,可私有部署,功能齐全,QA也可做接口自动化测试,测试集脚本语言支持Pre-Script,遵循javascript语法,如图:

4.devops流水线设计
根据上面的介绍,经过一定积累和沉淀后,我们开始设计CI(持续集成),CD(自动化部署),CI/CD的优势显而易见
解放了重复性劳动:
自动化部署工作可以解放集成、测试、部署等重复性劳动,而机器集成的频率明显比手工高很多。
更快地修复问题:
持续集成更早的获取变更,更早的进入测试,更早的发现问题,解决问题的成本显著下降。
更快的交付成果:
更早发现错误减少解决错误所需的工作量。集成服务器在构建环节发现错误可以及时通知开发人员修复。集成服务器在部署环节发现错误可以回退到上一版本,服务器始终有一个可用的版本。
减少手工的错误:
在重复性动作上,人容易犯错,而机器犯错的几率几乎为零。
减少了等待时间:
缩短了从开发、集成、测试、部署各个环节的时间,从而也就缩短了中间可以出现的等待时机。持续集成,意味着开发、集成、测试、部署也得以持续。
代码管理工具我们一直在用gitlab,经过研究,gitlab在8.0+版本就已经集成了CI/CD,可以帮助我们快速实施自动化,相比jenkins,gitlab-ci更加轻便,只需要在项目工程根目录创建.gitlab-ci.yml文件,写好job脚本即可,在服务器安装gitlab-runner工具,帮助执行job,一张图看懂我们基于k8s的CI/CD Pipeline

借助gitlab-runner,我们已实现多个devops流程,包括NodeJs、Spring Mvc,以及在VM虚拟机上的CI/CD

如部署遇到问题,可快速手工触发CI/CD,回滚上一个版本,保障线上始终有一个版本可用。
CI/CD 流程代码示例
stages :
- build_test #测试CI
- deploy_k8s_test #测试CD
- build_prod #生产CI
- deploy_k8s_prod #生产CD
#测试CI
build_test_job:
stage : build_test
script:
- mvn clean install
- cd target
- docker build -f classes/app.dockerfile -t registry/maven-project:$CI_COMMIT_SHA .
artifacts :
paths :
- target/classes/deploy.k8s.yaml
tags :
- runnerHost
only :
- master
#测试CD
deploy_k8s_test_job:
stage : deploy_k8s_test
before_script :
- docker push registry/maven-project:$CI_COMMIT_SHA
script: |
kubectl apply -f deploy.k8s.yaml
kubectl describe -f deploy.k8s.yaml
after_script :
- pwd
tags :
- runnerHost
only :
- master
5.运维监控平台
k8s在1.13+版本中已经剔除了heapster+influxdb作为默认监控工具,主推promerthues,promerthues可以做到代码级的监控,我们在各虚机、中间件、应用程序中使用工具收集资源消耗信息
grafana可作为大数据展示平台,实时查看各项资源运营情况

Prometheus也提供java开发包,可以做到代码级统计,当服务响应报错或时间过长,可触发告警,通知相关开发人员查看原因

6.平台整体架构
私有容器云和devops主流程已经实现,配合promethues监控,基础设施层形成闭环,这是从无到有的过程,整体架构一张图可以看懂:
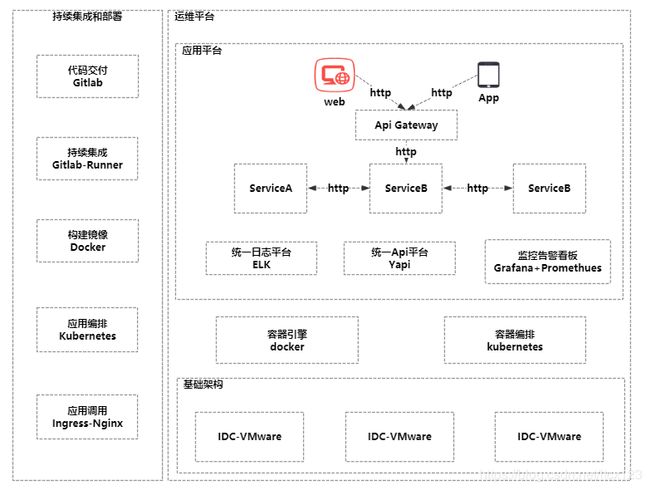
总结:目前的框架都是原生应用,利用了各家的优秀特性,我们并没有针对性改造框架,原生功能足够满足团队业务需求;有许多地方还需要深入研究和应用,完善基础设施层,例如监控目标、告警规则、Service Mesh如何将服务间请求下放到基础设施层、CI/CD的持续完善,金丝雀发布等等