Java源码分析2-LinkedList
以下内容基于JDK1.8
以下内容将分为如下几个章节
- 概述
- 继承关系图
- 相关成员变量
- 内部静态类
- 构造函数
- 常用方法
- 优缺点
概述
- List和Deque接口的双链表实现
- 实现了所有
List相关的操作 - 接收所有类型元素,包括Null
- 对于双向链表,所有操作都是可以预期的
- 索引到列表中的操作将从开头或结尾遍历列表,以较接近指定索引为准
- 非线程安全
继承关系图
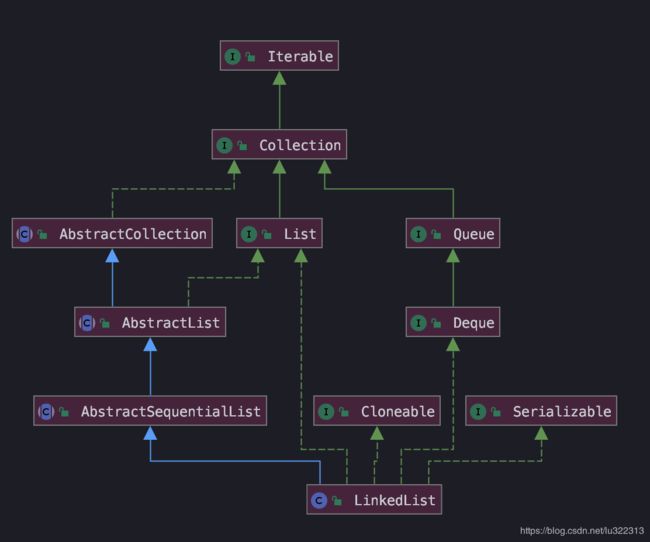
相关成员变量
//记录元素个数
transient int size = 0;
/**
* 记录链表第一个元素
*/
transient Node<E> first;
/**
* 记录链表最后一个元素
*/
transient Node<E> last;
内部静态类
Node的用途有两个
- 存储元素
- 记录元素的上一个和下一个元素
private static class Node<E> {
//当前节点存储元素
E item;
//下一个节点元素
Node<E> next;
//上一个节点元素
Node<E> prev;
//构造函数入参为上一个节点,当前节点,下一个节点
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
构造函数
- 无参构造函数
public LinkedList() {}
- 传入参数为
Collection子类的构造函数
public LinkedList(Collection<? extends E> c) {
this();
addAll(c);
}
- 2.1
addAll(Collection c)方法- size表示元素个数,结合下文可知此时为插入列表索引
public boolean addAll(Collection<? extends E> c) {
//size为列表元素个数,
return addAll(size, c);
}
- 2.2 通过索引新增元素
addAll(int index, Collection c)方法
public boolean addAll(int index, Collection<? extends E> c) {
//校验索引是否越界
//判断index >= 0 && index <= size,若为false,则抛出IndexOutOfBoundsException
checkPositionIndex(index);
//将传入集合转为数组
Object[] a = c.toArray();
int numNew = a.length;
//判断数组长度是否为0
if (numNew == 0)
return false;
//分别记录上一个和索引所在的节点
Node<E> pred, succ;
//判断传入索引是否与列表长度一致
if (index == size) {
//一致说明在列表末尾添加元素
succ = null;
//最后一个节点就变成了新插入元素的上一个节点
pred = last;
} else {
//通过索引找出对应节点,相当在pred和succ间插入元素
succ = node(index);
//那么当前上一个节点为索引对应节点的上一个
pred = succ.prev;
}
//迭代数组,
//在pred后不断的新新增元素,
//pred的下一个节点为插入的第一个节点,插入的第一个节点的上一个节点为pred
//第一个节点的下一个节点为插入的第二个节点,插入的第二个节点的上一个节点为插入的第一个节点
//以此类推.....
for (Object o : a) {
//根据List存储的类型对数组中的元素进行强制类型转换,此处可能会报错ClassCastException
@SuppressWarnings("unchecked") E e = (E) o;
//构造一个新节点
Node<E> newNode = new Node<>(pred, e, null);
//如果上一个节点为空,及list为空
if (pred == null){
//第一个元素为当前的新节点
first = newNode;
}else{
//上一个元素的下一个元素为新节点
pred.next = newNode;
}
//最后上一个元素为新节点
pred = newNode;
}
//此判断等价于index == size
if (succ == null) {
//最后一个元素为上述for循环完成后的最后一个新节点
last = pred;
} else {
//相当在pred和succ间插入元素,所以最后一个元素为上述for循环完成后的最后一个新节点的下一个元节点succ
//succ的上一个节点为最后一个新节点
pred.next = succ;
succ.prev = pred;
}
//元素个数=当前元素个数+数组长度
size += numNew;
//操作次数+1,相当于版本号
modCount++;
return true;
}
- 2.3 通过索引找出对应的节点
Node方法node(int index)
Node<E> node(int index) {
// assert isElementIndex(index);
//判断索引是否小于size>>1,及size/2
if (index < (size >> 1)) {
//若索引小于size/2,则通过向后查找的方式查找对应索引的节点
Node<E> x = first;
//从列表的一个位置开始查找元素
for (int i = 0; i < index; i++){
x = x.next;
}
return x;
} else {
//若索引大于size/2,则通过向前查找的方式查找对应索引的节点
Node<E> x = last;
for (int i = size - 1; i > index; i--){
x = x.prev;
}
return x;
}
}
通过该构造函数可知,LinkedList是以链表的方式存储数据,导致通过索引添加元素的效率极低
常用方法
- 在列表末尾添加单个元素
add(E e)方法
public boolean add(E e) {
//在列表末尾添加元素
linkLast(e);
return true;
}
- 1.1 在列表末尾添加元素
linkLast(E e)方法
void linkLast(E e) {
//取到列表末尾节点引用
final Node<E> l = last;
//创建上一个节点为列表末尾节点,置为传入值的新节点
final Node<E> newNode = new Node<>(l, e, null);
//修改列表末尾为新节点
last = newNode;
//判断末尾节点是否为空
if (l == null){
//末尾节点为空,则说明列表为空,新节点也是列表首节点
first = newNode;
}else{
//末尾节点不为空,则修改末尾节点的下一个节点为新节点
l.next = newNode;
}
size++;
modCount++;
}
分析完以上代码后,可总结出一个规律,LinkedList新增元素时,需要经过如下步骤
- 创建一个新节点,并指明其上一个节点
- 修改上一个节点的下一个节点
- 若在列表头,则需要修改头节点
- 若在尾,则需要修改尾节点
另外,LinkedList也存在线程安全的问题,并发操作时也会发生相互覆盖导致数据丢失的问题
- 在列表指定位置添加单个元素
add(E e)方法
public void add(int index, E element) {
//判断索引是否越界
checkPositionIndex(index);
if (index == size){
//当索引值等于size,即在列表尾插入元素
linkLast(element);
}else{
//当索引值不等于size,表示在列表前部插入元素
//在调用linkBefore之前,先调用node方法,找出索引对应的节点
linkBefore(element, node(index));
}
}
- 2.1 在指定节点前部插入元素
linkBefore(E e, Node方法succ)
void linkBefore(E e, Node<E> succ) {
//相当于在succ.prev()和succ间插入节点
//那么新节点的prev=succ.prev(),新节点的next()=succ
//获取到指定节点的上一个元素
final Node<E> pred = succ.prev;
//声明新节点的上一个节点为pred,下一个节点为succ,置为e
final Node<E> newNode = new Node<>(pred, e, succ);
//修改succ的上一节点为新节点
succ.prev = newNode;
if (pred == null){
//若指定节点的上一个节点为空,则说明指点节点为头节点,插入新节点后新节点变为对手
first = newNode;
}else{
//修改指定节点的上一节点的下一个节点为新节点
pred.next = newNode;
}
size++;
modCount++;
}
- 删除头节点
remove()方法
public E remove() {
return removeFirst();
}
- 3.1 删除头节点
removeFirst()方法
public E removeFirst() {
//获取头节点
final Node<E> f = first;
if (f == null){
//头节点为空,则抛出异常
throw new NoSuchElementException();
}
//解除头节点连接
return unlinkFirst(f);
}
- 3.2 解除头节点连接
unlinkFirst(Node方法f)
private E unlinkFirst(Node<E> f) {
// assert f == first && f != null;
//取出头节点存储值
final E element = f.item;
//获取头节点的下一个节点
final Node<E> next = f.next;
//将头节点的值置为空
f.item = null;
//将头节点置为空
f.next = null; // help GC
//将头节点的下一个节点置为头节点
first = next;
if (next == null){
//新头节点为空,则尾结点也为空
last = null;
}else{
//新头节点前一节点也置为空
next.prev = null;
}
size--;
modCount++;
return element;
}
- 删除尾节点```removeLast()````方法
public E removeLast() {
final Node<E> l = last;
//判断尾结点是否为空
if (l == null){
//尾结点为空则抛出异常
throw new NoSuchElementException();
}
//解除尾节点相关连接
return unlinkLast(l);
}
- 4.1 解除尾节点相关连接
unlinkLast(Node方法l)
private E unlinkLast(Node<E> l) {
//取出尾结点对应值
final E element = l.item;
//取出尾结点的前一节点
final Node<E> prev = l.prev;
//将尾结点的存储值置为空
l.item = null;
//将尾结点的前一节点置为空
l.prev = null; // help GC
//将列表的尾结点设置为前一节点---删除尾结点的关系链
last = prev;
if (prev == null){
//若上一节点为空,则说明头节点也为空
first = null;
}else{
//将新尾结点的下一节点置为空
prev.next = null;
}
size--;
modCount++;
return element;
}
- 根据值删除节点
remove(Object o)方法
public boolean remove(Object o) {
//判断值是否为空
if (o == null) {
//若为空,则从头结点开始迭代下一节点
for (Node<E> x = first; x != null; x = x.next) {
//判断节点值是否为空
if (x.item == null) {
//值为空则解除对应节点链接
unlink(x);
return true;
}
}
} else {
//若不为空,则从头结点开始迭代下一节点
for (Node<E> x = first; x != null; x = x.next) {
//判断节点值是否与传入值一致
if (o.equals(x.item)) {
//值一致则解除对应节点链接
unlink(x);
return true;
}
}
}
return false;
}
- 5.1 根据节点解除链接
E unlink(Node方法x)
E unlink(Node<E> x) {
//取出节点存储值
final E element = x.item;
//取出节点的下一节点
final Node<E> next = x.next;
//取出节点的上一节点
final Node<E> prev = x.prev;
//判断上一节点是否为空
if (prev == null) {
//若上一节点为空,则说明头节点也为空
first = next;
} else {
//将上一节点的下一节点跳过传入节点,指向其下一节点
prev.next = next;
//将传入节点的上一节点置为空
x.prev = null;
}
//判断下一节点是否为空
if (next == null) {
//若下一节点为空,则说明尾节点也为空
last = prev;
} else {
//将传入节点的上一节点跳过传入节点,指向其上一节点
next.prev = prev;
//将传入节点的下一节点置为空
x.next = null;
}
//将传入节点的值置为空
x.item = null;
size--;
modCount++;
return element;
}
综上,
LinkedList的优点- 插入和删除较快
- 缺点
- 非线程安全
- 根据索引查询,节点越多,效率越多