有状态容器实践:k8s集成ceph分布式存储
网易公开课,开课啦!
主讲内容:docker/kubernetes 云原生技术,大数据架构,分布式微服务,自动化测试、运维。
腾讯课堂:点击进入
网易课堂:点击进入
7月1号-7月29号 8折优惠!!!
7月1号-7月29号 8折优惠!!!
7月1号-7月29号 8折优惠!!!
全栈工程师开发手册 (作者:栾鹏)
架构系列文章
先格式化一块硬盘并设置开机自动挂载
mkfs.ext4 -f /dev/sdc
创建挂载点以及配置开机自动挂载:
方法一:
mkdir /data1;
修改fstab文件,添加如下行:
{data-disk-partition} /data1 ext4 defaults 0 2
例如(注意的是:defaults, 而不是default):
/dev/sdc /data1 ext4 defaults 0 2
Ceph安装原理
Ceph分布式存储集群由若干组件组成,包括:Ceph Monitor、Ceph OSD和Ceph MDS,其中如果你仅使用对象存储和块存储时,MDS不是必须的(本次我们也不需要安装MDS),仅当你要用到Cephfs时,MDS才是需要安装的。
Ceph的安装模型与k8s有些类似,也是通过一个deploy node远程操作其他Node以create、prepare和activate各个Node上的Ceph组件,官方手册中给出的示意图如下:
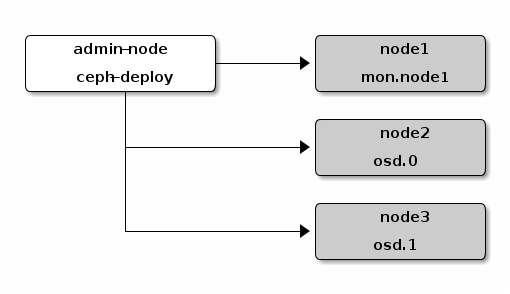
映射到我们实际的环境中,我的安装设计是这样的:
admin-node, deploy-node(ceph-deploy):10.47.136.60 iZ25cn4xxnvZ
mon.node1,(mds.node1): 10.47.136.60 iZ25cn4xxnvZ
osd.0: 10.47.136.60 iZ25cn4xxnvZ
osd.1: 10.46.181.146 iZ25mjza4msZ
实际上就是两个Aliyun ECS节点承担以上多种角色。不过像iZ25cn4xxnvZ这样的host name太反人类,长远考虑还是换成node1、node2这样的简单名字更好。通过编辑各个ECS上的/etc/hostname, /etc/hosts,我们将iZ25cn4xxnvZ换成node1,将iZ25mjza4msZ换成node2:
可以参考https://blog.csdn.net/luanpeng825485697/article/details/85017004
10.47.136.60 (node1):
# cat /etc/hostname
node1
# cat /etc/hosts
127.0.0.1 localhost
127.0.1.1 localhost.localdomain localhost
# The following lines are desirable for IPv6 capable hosts
::1 localhost ip6-localhost ip6-loopback
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
10.47.136.60 admin
10.47.136.60 node1
10.47.136.60 iZ25cn4xxnvZ
10.46.181.146 node2
----------------------------------
10.46.181.146 (node2):
# cat /etc/hostname
node2
# cat /etc/hosts
127.0.0.1 localhost
127.0.1.1 localhost.localdomain localhost
# The following lines are desirable for IPv6 capable hosts
::1 localhost ip6-localhost ip6-loopback
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
10.46.181.146 node2
10.46.181.146 iZ25mjza4msZ
10.47.136.60 node1
于是上面的环境设计就变成了:
admin-node, deploy-node(ceph-deploy):node1 10.47.136.60
mon.node1, (mds.node1) : node1 10.47.136.60
osd.0: node1 10.47.136.60
osd.1: node2 10.46.181.146
Ceph安装步骤
1、安装ceph-deploy
Ceph提供了一键式安装工具ceph-deploy来协助Ceph集群的安装,在deploy node上,我们首先要来安装的就是ceph-deploy,安装最新的ceph-deploy:
# wget -q -O- 'https://download.ceph.com/keys/release.asc' | sudo apt-key add -
# echo deb https://download.ceph.com/debian-jewel/ $(lsb_release -sc) main | sudo tee /etc/apt/sources.list.d/ceph.list
#apt-get update
... ...
# apt-get install ceph-deploy
注意:ceph-deploy只需要在admin/deploy node上安装即可。
2、前置设置
和安装k8s一样,在ceph-deploy真正执行安装之前,需要确保所有Ceph node都要开启NTP,同时建议在每个node节点上为安装过程创建一个安装账号,即ceph-deploy在ssh登录到每个Node时所用的账号。这个账号有两个约束:
- 具有sudo权限;
- 执行sudo命令时,无需输入密码。
我们将这一账号命名为cephd,我们需要在每个ceph node上(包括admin node/deploy node)都建立一个cephd用户,并加入到sudo组中。
以下命令在每个Node上都要执行:
useradd -d /home/cephd -m cephd
passwd cephd # 设置cephd的用户密码
添加sudo权限:
echo "cephd ALL = (root) NOPASSWD:ALL" | sudo tee /etc/sudoers.d/cephd
sudo chmod 0440 /etc/sudoers.d/cephd
最好直接在/etc/sudoers中添加
cephd ALL = (root) NOPASSWD:ALL
在admin node(deploy node)上,登入cephd账号,创建该账号下deploy node到其他各个Node的ssh免密登录设置,密码留空:
后面的教程都是在各个节点上使用cephd用户登录,在/home/cephd目录下执行
在deploy node上执行:
$ ssh-keygen 一路回车默认
将deploy node的公钥copy到其他节点上去:
$ ssh-copy-id cephd@node1
同样,执行 ssh-copy-id cephd@node2,完成后,测试一下免密登录。
$ ssh node1
最后,在Deploy node上创建并编辑~/.ssh/config,这是Ceph官方doc推荐的步骤,这样做的目的是可以避免每次执行ceph-deploy时都要去指定 –username {username} 参数。
$ cat ~/.ssh/config
Host node1
Hostname node1
User cephd
Host node2
Hostname node2
User cephd
$ chmod 600 config
3、安装ceph
这个环节参考的是Ceph官方doc手工部署一节。
如果之前安装过ceph,每个节点可以先执行如下命令以获得一个干净的环境:
$ sudo ceph-deploy forgetkeys
$ sudo ceph-deploy purge node1 node2
$ sudo ceph-deploy purgedata node1 node2
接下来我们就可以来全新安装Ceph了。在deploy node上,建立cephinstall目录,然后进入cephinstall目录执行相关步骤。
我们首先来创建一个ceph cluster,这个环节需要通过执行ceph-deploy new {initial-monitor-node(s)}命令。按照上面的安装设计,我们的ceph monitor node就是node1,因此我们执行下面命令来创建一个名为ceph的ceph cluster:
$ cd ~
$ mkdir cephinstall
$ cd cephinstall
$ sudo ceph-deploy new node1
[ceph_deploy.conf][DEBUG ] found configuration file at: /home/cephd/.cephdeploy.conf
[ceph_deploy.cli][INFO ] Invoked (1.5.35): /usr/bin/ceph-deploy new node1
[ceph_deploy.cli][INFO ] ceph-deploy options:
[ceph_deploy.cli][INFO ] username : None
[ceph_deploy.cli][INFO ] func :
[ceph_deploy.cli][INFO ] verbose : False
[ceph_deploy.cli][INFO ] overwrite_conf : False
[ceph_deploy.cli][INFO ] quiet : False
[ceph_deploy.cli][INFO ] cd_conf :
[ceph_deploy.cli][INFO ] cluster : ceph
[ceph_deploy.cli][INFO ] ssh_copykey : True
[ceph_deploy.cli][INFO ] mon : ['node1']
[ceph_deploy.cli][INFO ] public_network : None
[ceph_deploy.cli][INFO ] ceph_conf : None
[ceph_deploy.cli][INFO ] cluster_network : None
[ceph_deploy.cli][INFO ] default_release : False
[ceph_deploy.cli][INFO ] fsid : None
[ceph_deploy.new][DEBUG ] Creating new cluster named ceph
[ceph_deploy.new][INFO ] making sure passwordless SSH succeeds
[node1][DEBUG ] connection detected need for sudo
[node1][DEBUG ] connected to host: node1
[node1][DEBUG ] detect platform information from remote host
[node1][DEBUG ] detect machine type
[node1][DEBUG ] find the location of an executable
[node1][INFO ] Running command: sudo /sbin/initctl version
[node1][DEBUG ] find the location of an executable
[node1][INFO ] Running command: sudo /bin/ip link show
[node1][INFO ] Running command: sudo /bin/ip addr show
[node1][DEBUG ] IP addresses found: [u'101.201.78.51', u'192.168.16.1', u'10.47.136.60', u'172.16.99.0', u'172.16.99.1']
[ceph_deploy.new][DEBUG ] Resolving host node1
[ceph_deploy.new][DEBUG ] Monitor node1 at 10.47.136.60
[ceph_deploy.new][DEBUG ] Monitor initial members are ['node1']
[ceph_deploy.new][DEBUG ] Monitor addrs are ['10.47.136.60']
[ceph_deploy.new][DEBUG ] Creating a random mon key...
[ceph_deploy.new][DEBUG ] Writing monitor keyring to ceph.mon.keyring...
[ceph_deploy.new][DEBUG ] Writing initial config to ceph.conf...
new命令执行完后,ceph-deploy会在当前目录下创建一些辅助文件:
$ ls
ceph.conf ceph-deploy-ceph.log ceph.mon.keyring
$ cat ceph.conf
[global]
fsid = f5166c78-e3b6-4fef-b9e7-1ecf7382fd93
mon_initial_members = node1
mon_host = 10.47.136.60
auth_service_required = cephx
auth_client_required = cephx
auth_cluster_required = cephx
auth相关的配置,一般配置为none,即不使用认证,这样能适当加快ceph集群访问速度;
由于我们仅有两个OSD节点,因此我们在进一步安装之前,需要先对ceph.conf文件做一些配置调整:
修改配置以进行后续安装:
可以做一下修改
在[global]标签下,添加或修改
osd_pool_default_size = 2 存储文件的总副本数
osd_pool_default_min_size = 1 正常工作的最小副本数
osd_pool_default_pg_num = 64 分片数目
osd_pool_default_pgp_num = 64
可以修改的参数
[global]
osd_pool_default_size = 3(存储文件的总副本数,默认保留3个副本,实验环境可以修改为2个副本)
osd_pool_default_min_size = 1
osd_journal_size = 1024
osd_pool_default_pg_num = 133 (推荐每个osd节点使用100个pg,计算方法:4x100/3(副本数))
osd_pool_default_pgp_num = 133
public_network = 10.9.32.0/24 (如果有多块网卡的话,需要指定对外服务的公共网络,CIDR格式,例如:10.9.32.0/24,没有的话可以省略;
cluster_network = 10.80.20.0/24 (单网卡情形下,cluster_network可以忽略不设)
[mon]
mon_clock_drift_allowed = .15 (mon管理节点时间同步允许误差)
mon_clock_drift_warn_backoff = 30
[client]
rbd cache = true
rbd cache writethrough until flush = true
ceph.conf保存退出。接下来,我们执行下面命令在node1和node2上安装ceph运行所需的各个binary包:
$ sudo ceph-deploy install node1 node2
.... ...
[node2][INFO ] Running command: sudo ceph --version
[node2][DEBUG ] ceph version 12.2.7 (3ec878d1e53e1aeb47a9f619c49d9e7c0aa384d5) luminous (stable)
这一过程ceph-deploy会SSH登录到各个node上去,执行apt-get update, 并install ceph的各种组件包,这个环节耗时可能会长一些(依网络情况不同而不同),请耐心等待。如果网络不好,可以多尝试几遍。
4、初始化ceph monitor node
有了ceph启动的各个程序后,我们首先来初始化ceph cluster的monitor node。在deploy node的工作目录cephinstall下,执行:
$ cd cephinstall
$ sudo ceph-deploy mon create-initial
[ceph_deploy.conf][DEBUG ] found configuration file at: /root/.cephdeploy.conf
[ceph_deploy.cli][INFO ] Invoked (1.5.35): /usr/bin/ceph-deploy mon create-initial
[ceph_deploy.cli][INFO ] ceph-deploy options:
[ceph_deploy.cli][INFO ] username : None
[ceph_deploy.cli][INFO ] verbose : False
[ceph_deploy.cli][INFO ] overwrite_conf : False
[ceph_deploy.cli][INFO ] subcommand : create-initial
[ceph_deploy.cli][INFO ] quiet : False
[ceph_deploy.cli][INFO ] cd_conf :
[ceph_deploy.cli][INFO ] cluster : ceph
[ceph_deploy.cli][INFO ] func :
[ceph_deploy.cli][INFO ] ceph_conf : None
[ceph_deploy.cli][INFO ] default_release : False
[ceph_deploy.cli][INFO ] keyrings : None
[ceph_deploy.mon][DEBUG ] Deploying mon, cluster ceph hosts node1
[ceph_deploy.mon][DEBUG ] detecting platform for host node1...
[node1][DEBUG ] connected to host: node1
[node1][DEBUG ] detect platform information from remote host
[node1][DEBUG ] detect machine type
....
[iZ25cn4xxnvZ][INFO ] Running command: ceph --cluster=ceph --admin-daemon /var/run/ceph/ceph-mon.iZ25cn4xxnvZ.asok mon_status
[ceph_deploy.mon][INFO ] mon.iZ25cn4xxnvZ monitor has reached quorum!
[ceph_deploy.mon][INFO ] all initial monitors are running and have formed quorum
[ceph_deploy.mon][INFO ] Running gatherkeys...
[ceph_deploy.gatherkeys][INFO ] Storing keys in temp directory /tmp/tmpP_SmXX
[iZ25cn4xxnvZ][DEBUG ] connected to host: iZ25cn4xxnvZ
[iZ25cn4xxnvZ][DEBUG ] detect platform information from remote host
[iZ25cn4xxnvZ][DEBUG ] detect machine type
[iZ25cn4xxnvZ][DEBUG ] find the location of an executable
[iZ25cn4xxnvZ][INFO ] Running command: /sbin/initctl version
[iZ25cn4xxnvZ][DEBUG ] get remote short hostname
[iZ25cn4xxnvZ][DEBUG ] fetch remote file
[iZ25cn4xxnvZ][INFO ] Running command: /usr/bin/ceph --connect-timeout=25 --cluster=ceph --admin-daemon=/var/run/ceph/ceph-mon.iZ25cn4xxnvZ.asok mon_status
[iZ25cn4xxnvZ][INFO ] Running command: /usr/bin/ceph --connect-timeout=25 --cluster=ceph --name mon. --keyring=/var/lib/ceph/mon/ceph-iZ25cn4xxnvZ/keyring auth get-or-create client.admin osd allow * mds allow * mon allow *
[iZ25cn4xxnvZ][INFO ] Running command: /usr/bin/ceph --connect-timeout=25 --cluster=ceph --name mon. --keyring=/var/lib/ceph/mon/ceph-iZ25cn4xxnvZ/keyring auth get-or-create client.bootstrap-mds mon allow profile bootstrap-mds
[iZ25cn4xxnvZ][INFO ] Running command: /usr/bin/ceph --connect-timeout=25 --cluster=ceph --name mon. --keyring=/var/lib/ceph/mon/ceph-iZ25cn4xxnvZ/keyring auth get-or-create client.bootstrap-osd mon allow profile bootstrap-osd
[iZ25cn4xxnvZ][INFO ] Running command: /usr/bin/ceph --connect-timeout=25 --cluster=ceph --name mon. --keyring=/var/lib/ceph/mon/ceph-iZ25cn4xxnvZ/keyring auth get-or-create client.bootstrap-rgw mon allow profile bootstrap-rgw
... ...
[ceph_deploy.gatherkeys][INFO ] Storing ceph.client.admin.keyring
[ceph_deploy.gatherkeys][INFO ] Storing ceph.bootstrap-mds.keyring
[ceph_deploy.gatherkeys][INFO ] keyring 'ceph.mon.keyring' already exists
[ceph_deploy.gatherkeys][INFO ] Storing ceph.bootstrap-osd.keyring
[ceph_deploy.gatherkeys][INFO ] Storing ceph.bootstrap-rgw.keyring
[ceph_deploy.gatherkeys][INFO ] Destroy temp directory /tmp/tmpP_SmXX
这一过程很顺利。命令执行完成后我们能看到一些变化:
在当前目录下,出现了若干*.keyring,这是Ceph组件间进行安全访问时所需要的:
$ ls -l
total 216
-rw------- 1 root root 71 Nov 3 17:24 ceph.bootstrap-mds.keyring
-rw------- 1 root root 71 Nov 3 17:25 ceph.bootstrap-osd.keyring
-rw------- 1 root root 71 Nov 3 17:25 ceph.bootstrap-rgw.keyring
-rw------- 1 root root 63 Nov 3 17:24 ceph.client.admin.keyring
-rw-r--r-- 1 root root 242 Nov 3 16:40 ceph.conf
-rw-r--r-- 1 root root 192336 Nov 3 17:25 ceph-deploy-ceph.log
-rw------- 1 root root 73 Nov 3 16:28 ceph.mon.keyring
-rw-r--r-- 1 root root 1645 Oct 16 2015 release.asc
在node1(monitor node)上,我们看到ceph-mon已经运行起来了:
cephd@node1:~/cephinstall$ ps -ef|grep ceph
ceph 32326 1 0 14:19 ? 00:00:00 /usr/bin/ceph-mon --cluster=ceph -i node1 -f --setuser ceph --setgroup ceph
如果要手工停止ceph-mon,可以使用stop ceph-mon-all 命令。
5、prepare ceph OSD node
至此,ceph-mon组件程序已经成功启动了,剩下的只有OSD这一关了。启动OSD node分为两步:prepare 和 activate。OSD node是真正存储数据的节点,我们需要为ceph-osd提供独立存储空间,一般是一个独立的disk。但我们环境不具备这个条件,于是在本地盘上创建了个目录,提供给OSD。
在deploy node上执行:
ssh node1
sudo mkdir /var/local/osd0
sudo chmod -R 777 /var/local/osd0
exit
ssh node2
sudo mkdir /var/local/osd1
sudo chmod -R 777 /var/local/osd1
exit
在重装之前记得要重新格式化分区
sudo umount /data1
sudo mkfs.ext4 /dev/vdc
sudo mount /dev/vdc /data1
sudo chmod -R 777 /data1
接下来,我们就可以执行prepare操作了,prepare操作会在上述的两个osd0和osd1目录下创建一些后续activate激活以及osd运行时所需要的文件:
cephd@node1:~/cephinstall$ sudo ceph-deploy osd prepare node1:/var/local/osd0 node2:/var/local/osd1
[ceph_deploy.conf][DEBUG ] found configuration file at: /home/cephd/.cephdeploy.conf
[ceph_deploy.cli][INFO ] Invoked (1.5.35): /usr/bin/ceph-deploy osd prepare node1:/var/local/osd0 node2:/var/local/osd1
[ceph_deploy.cli][INFO ] ceph-deploy options:
[ceph_deploy.cli][INFO ] username : None
[ceph_deploy.cli][INFO ] disk : [('node1', '/var/local/osd0', None), ('node2', '/var/local/osd1', None)]
[ceph_deploy.cli][INFO ] dmcrypt : False
[ceph_deploy.cli][INFO ] verbose : False
[ceph_deploy.cli][INFO ] bluestore : None
[ceph_deploy.cli][INFO ] overwrite_conf : False
[ceph_deploy.cli][INFO ] subcommand : prepare
[ceph_deploy.cli][INFO ] dmcrypt_key_dir : /etc/ceph/dmcrypt-keys
[ceph_deploy.cli][INFO ] quiet : False
[ceph_deploy.cli][INFO ] cd_conf :
[ceph_deploy.cli][INFO ] cluster : ceph
[ceph_deploy.cli][INFO ] fs_type : xfs
[ceph_deploy.cli][INFO ] func :
[ceph_deploy.cli][INFO ] ceph_conf : None
[ceph_deploy.cli][INFO ] default_release : False
[ceph_deploy.cli][INFO ] zap_disk : False
[ceph_deploy.osd][DEBUG ] Preparing cluster ceph disks node1:/var/local/osd0: node2:/var/local/osd1:
[node1][DEBUG ] connection detected need for sudo
[node1][DEBUG ] connected to host: node1
[node1][DEBUG ] detect platform information from remote host
[node1][DEBUG ] detect machine type
[node1][DEBUG ] find the location of an executable
[node1][INFO ] Running command: sudo /sbin/initctl version
[node1][DEBUG ] find the location of an executable
[ceph_deploy.osd][INFO ] Distro info: Ubuntu 14.04 trusty
[ceph_deploy.osd][DEBUG ] Deploying osd to node1
[node1][DEBUG ] write cluster configuration to /etc/ceph/{cluster}.conf
[ceph_deploy.osd][DEBUG ] Preparing host node1 disk /var/local/osd0 journal None activate False
[node1][DEBUG ] find the location of an executable
[node1][INFO ] Running command: sudo /usr/sbin/ceph-disk -v prepare --cluster ceph --fs-type xfs -- /var/local/osd0
[node1][WARNIN] command: Running command: /usr/bin/ceph-osd --cluster=ceph --show-config-value=fsid
[node1][WARNIN] command: Running command: /usr/bin/ceph-osd --check-allows-journal -i 0 --cluster ceph
[node1][WARNIN] command: Running command: /usr/bin/ceph-osd --check-wants-journal -i 0 --cluster ceph
[node1][WARNIN] command: Running command: /usr/bin/ceph-osd --check-needs-journal -i 0 --cluster ceph
[node1][WARNIN] command: Running command: /usr/bin/ceph-osd --cluster=ceph --show-config-value=osd_journal_size
[node1][WARNIN] populate_data_path: Preparing osd data dir /var/local/osd0
[node1][WARNIN] command: Running command: /bin/chown -R ceph:ceph /var/local/osd0/ceph_fsid.782.tmp
[node1][WARNIN] command: Running command: /bin/chown -R ceph:ceph /var/local/osd0/fsid.782.tmp
[node1][WARNIN] command: Running command: /bin/chown -R ceph:ceph /var/local/osd0/magic.782.tmp
[node1][INFO ] checking OSD status...
[node1][DEBUG ] find the location of an executable
[node1][INFO ] Running command: sudo /usr/bin/ceph --cluster=ceph osd stat --format=json
[
ceph_deploy.osd][DEBUG ] Host node1 is now ready for osd use.
[node2][DEBUG ] connection detected need for sudo
[node2][DEBUG ] connected to host: node2
... ...
[node2][INFO ] Running command: sudo /usr/bin/ceph --cluster=ceph osd stat --format=json
[ceph_deploy.osd][DEBUG ] Host node2 is now ready for osd use.
prepare并不会启动ceph osd,那是activate的职责。
6、激活ceph OSD node
接下来,我们来激活各个OSD node:
修改完权限后,我们再来执行activate:
$ sudo ceph-deploy osd activate node1:/var/local/osd0 node2:/var/local/osd1
如果报fsid不一致,就要重新清理,重新装了。
如果没有错误报出!但OSD真的运行起来了吗?我们还需要再确认一下。
我们先通过ceph admin命令将各个.keyring同步到各个Node上,以便可以在各个Node上使用ceph命令连接到monitor:
注意:执行ceph admin前,需要在deploy-node的/etc/hosts中添加:
10.47.136.60 admin # 其中10.47.136.60是admin节点的ip
执行ceph admin:
$ sudo ceph-deploy admin admin node1 node2
$ sudo chmod +r /etc/ceph/ceph.client.admin.keyring
接下来,查看一下ceph集群中的OSD节点状态:
$ ceph osd tree
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-1 0.07660 root default
-2 0.03830 host node1
0 0.03830 osd.0 up 1.00000 1.00000
-3 0.03830 host iZ25mjza4msZ
1 0.03830 osd.1 up 1.00000 1.00000
$ceph -s
cluster f5166c78-e3b6-4fef-b9e7-1ecf7382fd93
health HEALTH_OK
monmap e1: 1 mons at {node1=10.47.136.60:6789/0}
election epoch 3, quorum 0 node1
osdmap e11: 2 osds: 2 up, 2 in
flags sortbitwise
pgmap v29: 64 pgs, 1 pools, 0 bytes data, 0 objects
37834 MB used, 38412 MB / 80374 MB avail
64 active+clean
可以看到ceph osd节点上的ceph-osd启动正常,cluster 状态为active+clean,至此,Ceph Cluster集群安装ok(我们暂不需要Ceph MDS组件)。
参考:https://tonybai.com/2016/11/07/integrate-kubernetes-with-ceph-rbd/
四、创建一个使用Ceph RBD作为后端Volume的Pod
我们来创建ceph-secret这个k8s secret对象,这个secret对象用于k8s volume插件访问ceph集群:
获取client.admin的keyring值,并用base64编码:
# ceph auth get-key client.admin
AQBiKBxYuPXiJRAAsupnTBsURoWzb0k00oM3iQ==
# echo "AQBiKBxYuPXiJRAAsupnTBsURoWzb0k00oM3iQ=="|base64
QVFCaUtCeFl1UFhpSlJBQXN1cG5UQnNVUm9XemIwazAwb00zaVE9PQo=
创建个命名空间
apiVersion: v1
kind: Namespace
metadata:
name: cloudai-2
labels:
name: cloudai-2
创建秘钥
apiVersion: v1
kind: Secret
metadata:
name: cephfs-secret
namespace: cloudai-2
type: kubernetes.io/rbd
data:
key: QVFCaUtCeFl1UFhpSlJBQXN1cG5UQnNVUm9XemIwazAwb00zaVE9PQo=
创建pv
apiVersion: v1
kind: PersistentVolume # 创建pv,数据存储
metadata:
name: cloudai2-code-pv
namespace: cloudai-2
labels:
cloudai2-pvname: pv-cloudai2
spec:
capacity:
storage: 1Gi # 设置大小
accessModes:
- ReadWriteMany
cephfs:
monitors:
- 10.47.136.60:6789
user: admin # 修改用户
path: /cloudai2/ # 存储的路径。是k8s中配置的pv根目录下的路径
secretRef:
name: cephfs-secret # 配置访问秘钥
readOnly: false
persistentVolumeReclaimPolicy: Retain # 保留所有的数据资源
创建pvc绑定到pv
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: cloudai-code-pvc
namespace: cloudai-2
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 1Gi # 设置需要的存储大小
selector:
matchLabels:
cloudai2-pvname: pv-cloudai2 # 匹配pv
centos安装ceph
安装准备(所有节点)
在各个node节点创建ceph用户,并将它添加至sudo用户组,并修改各主机名
在各个node节点上安装openssh-server
在ceph-deploy节点上,生成ssh密钥,并将公钥发送至所有的node节点,使它可以免密码ssh登陆
在4个节点中添加ceph的安装源
[ceph-noarch]
name=Cephnoarch packages
baseurl=http://ceph.com/rpm-infernalis/el7/noarch
enabled=1
gpgcheck=0
type=rpm-md
gpgkey=https://ceph.com/git/?p=ceph.git;a=blob_plain;f=keys/release.asc
在4个节点中修改 /etc/hosts
10.15.15.60ceph-60
10.15.15.61ceph-61
10.15.15.62ceph-62
10.15.15.63ceph-63
生成ssh密钥,并将公钥发送至所有的node节点,可以使用ssh-keygen与 ssh-copy-id工具。让deploy节点与其它节点建立互信,是为了减少在安装过程中密码的输入。
安装ceph:
-
安装 ceph-deploy: yum update && yum install ceph-deploy
-
创建ceph的cluster, 并设置ceph-61为ceph的 monitor: sudoceph-deploy new ceph-61
-
修改ceph.conf文件,添加clueter network与public network
cluster network =10.16.16.0/24
public network =10.15.15.0/24
- 在60上生成一个 ~/.ssh/config文件,内容如下
Host ceph-61
Hostname ceph-61
User ceph
Host ceph-62
Hostname ceph-62
User ceph
Host ceph-63
Hostname ceph-63
User ceph
- 在60上为61,62,63安装cpeh
sudoceph-deploy install ceph-61 ceph-62 ceph-63
- 在60上执行cephmon的初始化,并设置61为cephmonitor节点
ceph-deploy --overwrite-confmon create-initial
sudoceph-deploy admin ceph-61
创建OSD节点
- 在三个节点上分别创建目录,例如在61上创建两个目录: sudomkdir -p /opt/ceph/osd61-1 /opt/ceph/osd61-2,三节点两个两个目录,总共创建6个目录
2.为这些目录设置所有权,所有权归 ceph:ceph: chown -R ceph:ceph /opt/ceph/osd61-1 /opt/ceph/osd61-23.创建osd: sudo ceph-deploy osdprepare ceph-61:/opt/ceph/osd61-1 ceph-61:/opt/ceph/osd61-24.激活osd: sudo ceph-deploy osdactivate ceph-61:/opt/ceph/osd61-1 ceph-61:/opt/ceph/osd61-25.查看 ceph的状态
上图中是我们安装好之后,运行cephosddump显示的结果。
可以看出,我们一共创建了6个osd,每个osd的权重都是一样的。
上面可以看到,我们的ceph状态是正常的,有6个osd,6个都是启用的,处于pg中。这样,我们的ceph块存储就安装好了。
我们总共有三个节点,我在每个节点上创建了两个目录作为osd的数据存储目录,共有6个osd。
ceph中因为有了ceph-deploy这个工具,安装起来还是很轻松的。
https://blog.csdn.net/zcc_heu/article/details/79017624