Spark SQL数据源操作
概述:本文介绍Spark SQL操作parquet、hive及mysql的方法,并实现Hive和MySql两种不同数据源的连接查询
1、操作parquet
(1)编程实现
#启动spark-shell
./app/spark-2.4.2-bin-hadoop2.6/bin/spark-shell --master local[2] --jars /root/software/mysql-connector-java-5.1.47-bin.jar
#创建DataFrame
object ParqueApp {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().appName("DataSetApp").master("local[2]").getOrCreate()
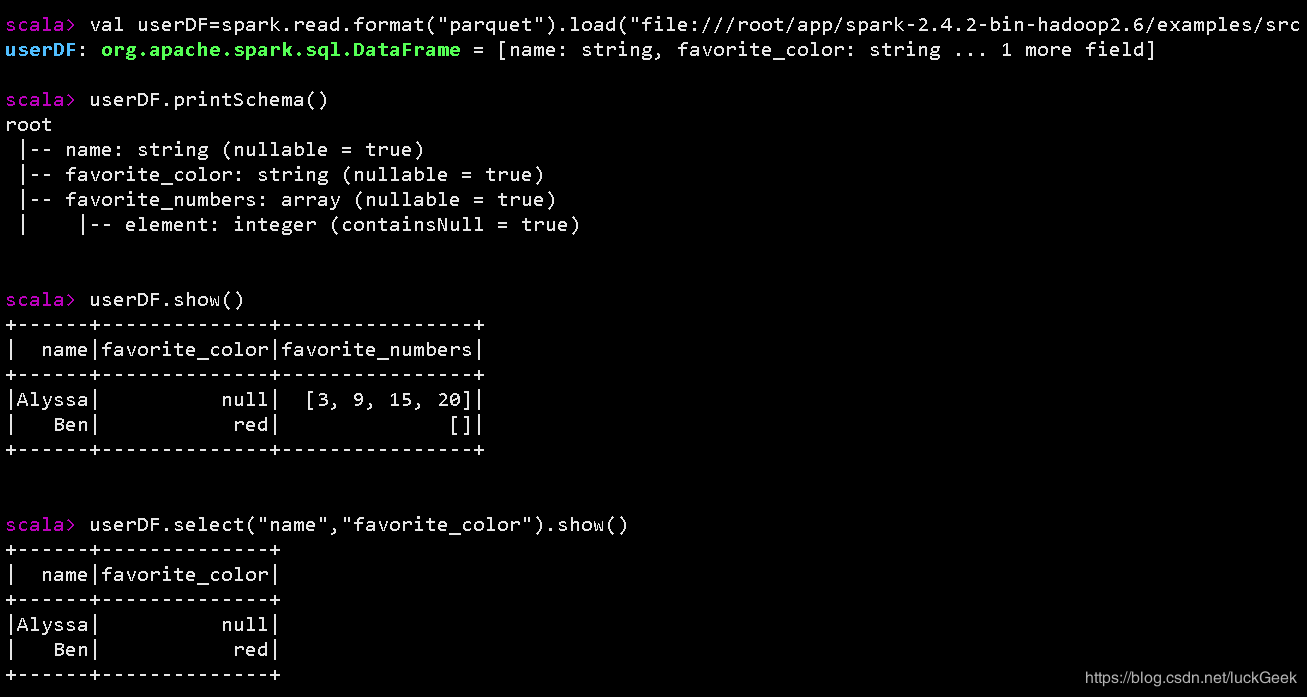
val userDF = spark.read.format("parquet").load("file:///root/app/spark-2.4.2-bin-hadoop2.6/examples/src/main/resources/users.parquet")
userDF.printSchema()
userDF.show()
userDF.select("name", "favorite_color").show()
//将查询结果写入json文件
userDF.select("name", "favorite_color").write.format("json").save("file:///root/app/tmp/jsonout")
//自定义分区数 默认200
spark.sqlContext.setConf("spark.sql.shuffle.partitions", "10")
//spark sql默认读取parquet文件,故可以简写如下
spark.read.load("file:///root/app/spark-2.4.2-bin-hadoop2.6/examples/src/main/resources/users.parquet").show()
spark.read.option("path", "file:///root/app/spark-2.4.2-bin-hadoop2.6/examples/src/main/resources/users.parquet").load().show()
spark.stop()
}
}部分执行结果如图:
2)spark sql方式
#启动spark-sql
./app/spark-2.4.2-bin-hadoop2.6/bin/spark-sql --master local[2] --jars /root/software/mysql-connector-java-5.1.47-bin.jar
#创建临时表
CREATE TEMPORARY VIEW parquetTable
USING org.apache.spark.sql.parquet
OPTIONS (
path "/root/app/spark-2.4.2-bin-hadoop2.6/examples/src/main/resources/users.parquet"
);
#查寻结果
SELECT * FROM parquetTable2、操作Hive表数据
#启动spark-shell
./app/spark-2.4.2-bin-hadoop2.6/bin/spark-shell --master local[2] --jars /root/software/mysql-connector-java-5.1.47-bin.jar
#查看所有表
spark.sql("show tables").show
#查询记录
spark.sql("select deptno,count(1) from emp group by deptno").filter("deptno is not null").show
#保存结果
spark.sql("select deptno,count(1) as total from emp group by deptno").filter("deptno is not null").write.saveAsTable("hive_table_tmp")
#自定义分区数 默认分区数为200
spark.sqlContext.setConf("spark.sql.shuffle.partitions","10")注意:org.apache.spark.sql.AnalysisException: Attribute name "count(1)" contains invalid character(s) among " ,;{}()\n\t=". Please use alias to rename it.
count(1)需要使用别名
Spark shell application UI结果如下:
3、操作MySql数据库
(1)spark-shell方式
#方式一 注意驱动 url从hive的hive-site.xml中获取
val jdbcDF = spark.read.format("jdbc").option("url","jdbc:mysql://localhost:3306").option("dbtable","sparksql.TBLS").option("user", "root").option("password", "root").option("driver","com.mysql.jdbc.Driver").load()
jdbcDF.printSchema
jdbcDF.show
jdbcDF.select("SD_ID","TBL_NAME").show
#方式二
import java.util.Properties
val connectionProperties = new Properties()
connectionProperties.put("user", "root")
connectionProperties.put("password", "root")
connectionProperties.put("driver", "com.mysql.jdbc.Driver")
val jdbcDF2 = spark.read.jdbc("jdbc:mysql://localhost:3306", "sparksql.TBLS", connectionProperties)
#余下操作同方式一(2)spark-sql方式
#启动spark-sql
CREATE TEMPORARY VIEW jdbcTable
USING org.apache.spark.sql.jdbc
OPTIONS (
url "jdbc:mysql://localhost:3306",
dbtable "sparksql.TBLS",
user 'root',
password 'root',
driver 'com.mysql.jdbc.Driver'
);
SELECT * FROM jdbcTable;执行结果如下:

4、Hive与MySql综合案例
#mysql下创建数据库和表
CREATE DATABASE mySpark;
USE mySpark;
CREATE TABLE DEPT(
DEPTNO INT(2) PRIMARY KEY,
DNAME VARCHAR(20),
LOC VARCHAR(20)
);
INSERT INTO DEPT values(10,'ACCOUNTIN','NEW YORK'),(20,'RESEARCH','DALLAS'),(30,'SALES','CHICAGO'),(40,'OPERATIONS','BOSTON');实现代码:
object HiveWithMysqlApp {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().appName("HiveWithMysqlApp").master("local[2]").getOrCreate()
//加载Hive表数据
val HiveData = spark.table("emp")
//加载MySQL表数据
val mysqlData = spark.read.format("jdbc").option("url", "jdbc:mysql://localhost:3306").option("dbtable", "mySpark.DEPT").option("user", "root").option("password", "root").option("driver", "com.mysql.jdbc.Driver").load()
//连接查询
val resultJoinData = HiveData.join(mysqlData, HiveData("deptno") === mysqlData("DEPTNO"))
resultJoinData.printSchema()
resultJoinData.show()
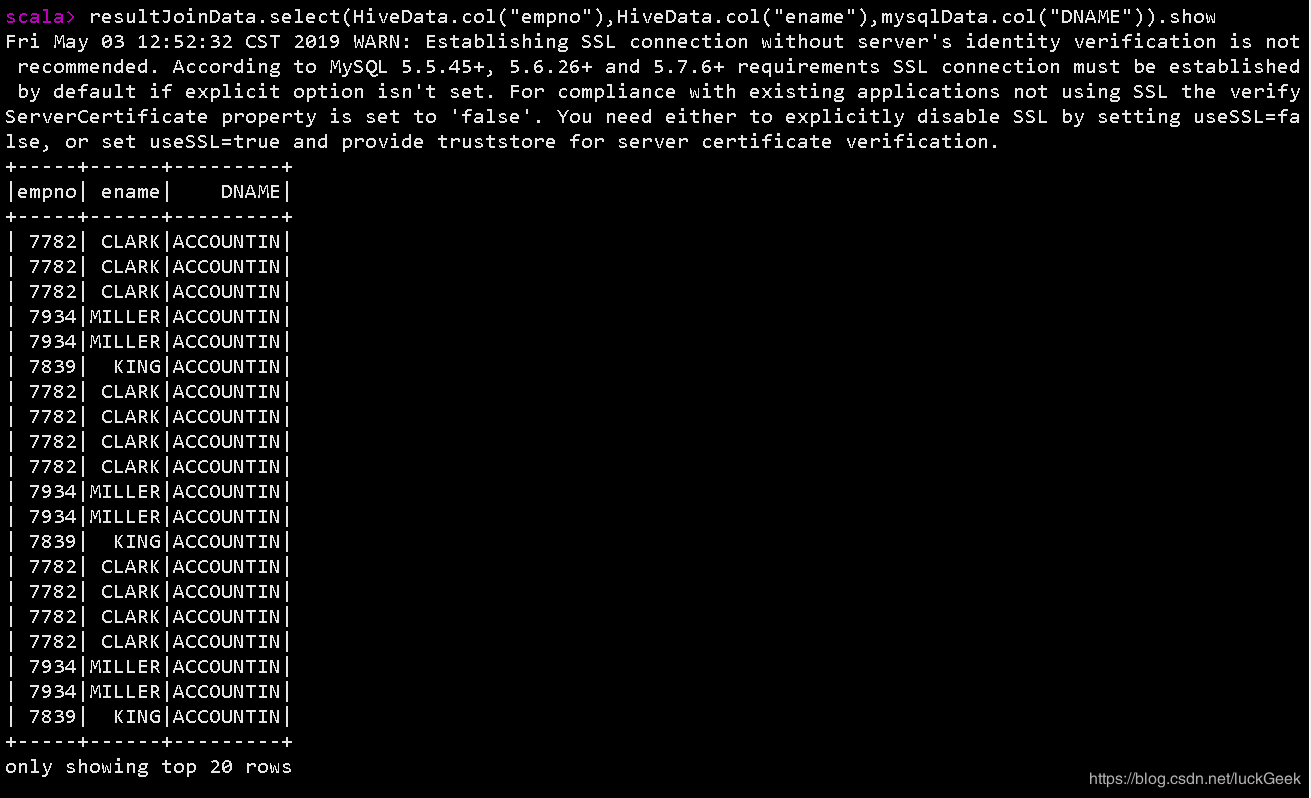
resultJoinData.select(HiveData.col("empno"), HiveData.col("ename"), mysqlData.col("DNAME")).show
spark.stop()
}
}部分执行结果如下: