论文笔记3 --(ReID)In Defense of the Triplet Loss for Person Re-Identification
《In Defense of the Triplet Loss for Person Re-Identification》
论文:https://arxiv.org/abs/1703.07737
GitHub:https://github.com/VisualComputingInstitute/triplet-reid
deep metric learning – 深度度量学习,也就是相似度学习
Classification Loss – 当目标很大时,会严重增加网络参数,而训练结束后很多参数都会被摒弃。
Verification Loss – 只能成对的判断两张图片的相似度,因此很难应用到目标聚类和检索上去。因为一对一对比太慢。
Triplet loss – 端到端,简单直接; 自带聚类属性; 特征高度嵌入,但是不好训练。
Triplet loss最早来源于Google的FaceNet,Triplet loss的想法很简单:类内距离趋小,类间距离趋大。是当前应用很广泛的一种损失函数。在FaceNet中,通过构建embedding方式,将人脸图像直接映射到欧式空间,而优化这种embedding的方法可以概括为,构建许多组三元组(Anchor,Positive,Negative),其中Anchor与Positive同label,Anchor与Negative不同label(在人脸识别里面,即就是Anchor,Positive是同一个个体,而与Negative是不同个体),通过学习优化这embedding,使得欧式空间内的Anchor与Positive 的距离比与Negative的距离要近。
Triplet loss通常能比classification得到更好的feature。还有一个优点就是Triplet loss可以卡阈值,Triplet loss训练的时候需要设置一个margin,这个margin可以控制正负样本的距离,当feature 进行normalization后,可以更加方便的卡个阈值来判断是不是同一个ID。当然Triplet loss也有缺点,就是收敛慢,而且比classification更容overfitting。
Triplet loss的主要应用就是face identification、person re-identification、vehicle re-identification等。
传统的Triplet loss训练需要一个三元组,achor(a)、positive(p)、negative(n)。
Triplet loss的缺点在于随机从训练集中挑选三张图片,那么可能挑选出来的可能是很简单的样本组合,即很像的正样本和很不像的负样本。作者认为,让网络一直学习简单的样本,会限制网络的泛化能力。因此,作者提出了一种在线batch hard sample mining的改进版Triplet loss,大量实验表明,这种改进版的方法效果非常好。
论文贡献:
(1) 设计了新的Triplet Loss,并和其它变种进行了对比;
(2) 对于是否需要pre-trained模型,进行了实验对比分析。
Abstract
过去几年,在过去几年中,计算机视觉领域经历了一场革命,主要是由于大型数据集的出现以及采用深度卷积神经网络进行端到端学习。 行人重识别领域也不例外。 不幸的是,社区中的普遍看法是triplet loss不如surrogate losses (classification, verification),然后是单独的度量学习步骤。作者证明了,对于从头开始训练的模型以及预训练的模型,使用改进的triplet loss来进行端到端深度量度学习,大大超过了大多数其他已发布的方法。
1. Introduction
近年来,行人重识别(person re-identification (ReID))在计算机视觉社区中引起了极大的关注。特别是随着深度学习的兴起,已经提出了许多新的方法来实现这一任务。在很多方面,行人重识别类似于图像检索。然后提到了FaceNet,其关键组成部分是使用triplet loss来训练卷积神经网络作为embedding嵌入函数,triplet loss优化了嵌入空间,使得具有相同特征的数据点比具有不同特征的数据点更接近。
一些行人重识别的方法已经使用了triplet loss的一些变体来训练他们的模型,取得了一定的成功。最近最成功的行人重识别方法认为,classification loss(可能和verification loss相结合)要优于任务A Multi-task Deep Network for Person Re-identification. Deep Transfer Learning for Person Re-identification. Person Re-identification: Past, Present and Future.等。通常,这些方法使用这些surrogate losses中的一个或多个来训练深度CNN,并且随后使用网络的一部分作为特征提取器,将其与度量学习方法组合以生成最终嵌入(to generate final embeddings)。但是,这两种损失都存在问题。随着特征数量的增加,classification loss需要越来越多的可学习参数,其中大部分将在训练后被丢弃。另一方面,许多用验证损失(verification loss)训练的网络必须用于交叉图像表示模式,只能回答“这两个图像有多相似?”的问题。这使得将它们用于任何其他任务(例如群集或检索)代价非常大,因为每个检测器必须通过网络与每个图库图像去配对。
在这篇论文中,作者表明与目前的观点相反,认为具有triplet loss的简单CNN在CUHK03、Market-1501、MARS数据集上优于当前最先进的方法。triplet loss允许我们在输入图像和期望的嵌入空间之间进行端到端的学习。这意味着我们可以直接针对最终任务去优化网络,这也使得额外的度量学习步骤变得过时。相反,我们可以通过计算嵌入embeddings的欧式距离来简单的比较行人。
triplet loss不受欢迎的一个可能的原因是,在使用时经常会产生令人失望的结果。使用triplet loss去学习的一个必要的步骤是mining hard triplets,没有hard mining会导致训练将很快停滞不前,选择过难的hard又会导致训练变得不稳定收敛变难。然而,挖掘这种hard triplets是比较耗时的,而且也没有清楚的定义什么是“good” hard triplets。作者展示了如何缓解这个问题,从而加快训练速度,提高性能。作者系统地分析了triplet losses的设计空间(design space),并且评估了哪一个最适合行人重识别。具体会在第2节讨论。
另一个明显的趋势似乎是使用预训练模型,比如GoogleNet或ResNet-50。事实上,预训练模型通常会为行人重识别获得很好的分数,而表现最佳的方法则是使用从头训练的网络。一些作者甚至认为从头开始训练是不好的。但是,使用预训练也会导致设计锁定,并且不允许探索新的深度学习进展或不同的体系结构。作者表明,当遵循深度学习的最佳实践时,从头开始训练的网络可以让行人重识别更有竞争力。此外,论文中不依赖于专门针对行人重识别定制的网络组件,而是训练普通的前馈CNN,这与许多其它从头开始训练的方法不同。实际上,作者使用预训练权重的网络获得了最佳结果,在小型架构上获得了可观的分数,为需要在资源受限的硬件(如嵌入式设备)上运行行人重识别提供了可行的替代方案。
总之,论文的贡献主要有来两个方面:
(1)设计了新的triplet loss,并和其它的变体做了系统地评估。
(2)对于是否需要pre-trained模型,进行了实验对比分析。
论文使用triplet loss并且没有特殊的层,通过预训练的CNN和从头开始训练的模型获得了最先进的结果。
2. Learning Metric Embeddings, the Triplet Loss, and the Importance of Mining
这一小节主要介绍了几种Triplet Loss的变种
度量嵌入(metric embedding)学习的目标是学习函数:
![]()
其将来自RF中的数据流形的语义相似点映射到RD中的度量接近点。类似地,fθ应该将RF中的语义上不同的点映射到RD中的度量远点。函数fθ由θ参数化,可以是从线性变换到通常由深度神经网络表示的复杂非线性映射的任何范围。令D(x,y):RD×RD→R是测量嵌入空间中的距离的度量函数。为清楚起见,我们使用快捷符号Di,j=D(fθ(xi),fθ(xj)),其中我们省略了Di,j对参数θ的间接依赖性。通常的做法是,所有损失项除以一个batch中summand的数量(the number of summands in a batch);为了简明,在以下等式中省略了这个术语。
Large Margin Nearest Neighbor loss
Distance Metric Learning for Large Margin Nearest Neighbor Classification.
比较早的Triplet形式。
Weinberger和Saul探讨了这一主题,明确的目标是在学习的嵌入空间中执行k-最近邻分类,并提出“大边缘最近邻损失(Large Margin Nearest Neighbor loss)”来优化函数fθ:
![]()
它包括一个拉近项(pull-term),拉近属于同一目标的样本;以及一个推远项(push-term),推远不同目标的的样本:
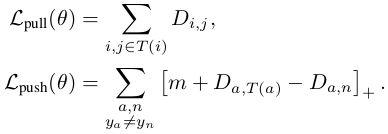
因为是最近邻分类,所以同一类中可能有多个群集clusters,而且固定的集群中心也比较难以确定。
由于此属性对于面部和行人重识别等检索任务是不利的,因此FaceNet提出了对LLMNN(θ)的修改,称为“Triplet loss”:
FaceNet Triplet Loss
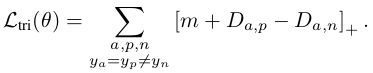
Google的人脸认证模型FaceNet, 不要求同一类的所有点都形成一个集群,只要类内距离大于类间距离就可以。完美的契合人脸认证的思想。
triplet loss一个重要的问题是,随着数据集变大,triplets可能的数量会立即增长,使得足够长的训练变得不切实际。
更糟糕的是,fθ相对快速地学会正确映射大多数琐碎的triplet,使得所有triplet的大部分无法提供信息。因此,挖掘hard triplets对学习至关重要。
穿着不同颜色衣服的人是不同的人;
hard negatives – 相似但不同的人;
hard positives – 同一个人但完全不同的姿势。
通过这些,极大地帮助理解“同一个人”的概念。
仅使用最难的triplets将经常不成比例地选择数据中的异常值并使fθ无法学习“正常”关联。因此,通常只采用中度的negatives 和/或 positives。无论采用何种类型的挖掘mining,它都是与训练分开的步骤,并且增加了相当大的开销,因为它需要使用最新的fθ嵌入大部分数据并计算这些数据点之间的所有成对距离。
FaceNet Triplet Loss训练时,一旦选择特定的B triplets集合,数据就会按顺序排好的3个一组3个一组。那么batch_size=3B,这些3B个图像实际上有多达6B^2−4B种有效的triplets组合,仅仅使用B种就很浪费。
Batch Hard Triplet Loss
所以我们可以首先改变一下数据的组织方式,即随机抽样P类(P个人),每个人随机地选K张图片,从而产生一个PKbatch的图片即batch size=P×K。现在,对于batch中的每个样本,可以在生成triplets来计算loss时选择batch中最难的positive和negative,称之为Batch Hard: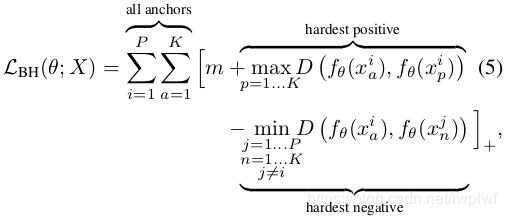
这是为mini-batch X定义的,其中xij表示第i个人的第j张图片。
被选定的triplets可以认为是中度的triplets,因为它们是数据的一小部分中最难的,这对于学习triplet loss是最好的。
Batch All Triplet Loss
这种新的抽样方法总共会有PK(PK-K)(K-1)种组合,称之为Batch All。

Batch All Triplet Loss看起来一次可以处理非常多的三元组,但是有一点很尴尬:数据集非常大时训练将会非常耗时,同时随着训练深入很多三元组因为很容易被分对而变成了“无用的”三元组。
Lifted Embedding Loss
Deep Metric Learning via Lifted Structured Feature Embedding.
针对3个一组3个一组排列的batch,提出了一种新的Loss:将anchor-positive pair之外的所有样本作为negative,然后优化Loss的平滑边界。
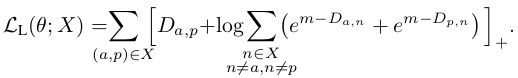
文章针对 batch size=P×K的形式对上式稍作改进:

Distance Measure
很多相关工作中,都使用平方欧式距离 D(a,b)=|a−b|22 作为度量函数。作者虽然没有系统对比过其它度量函数,但是在实验中发现非平方欧氏距离更稳定。同时,使用非平方欧氏距离使得margin这个参数更具有可读性。
Soft-margin
之前的很多Triplet Loss都采用了截断处理,即如果Triplet三元组关系正确则Loss直接为0。 作者发现,对于行人重识别来说,有必要不断地拉近同类目标的距离。因此,作者设计了下面的soft-margin函数:
![]()
3. Experiments
实验主要包含3个部分:
– 多种Triplet Loss性能对比;
– 选择好Triplet Loss,在CUHK03,Market-1501和MARS测试集上,测试预训练网络和从头训练网络的性能;
– 讨论从头开始训练模型在实际用例中的优势。
(1)多种Triplet Loss性能对比
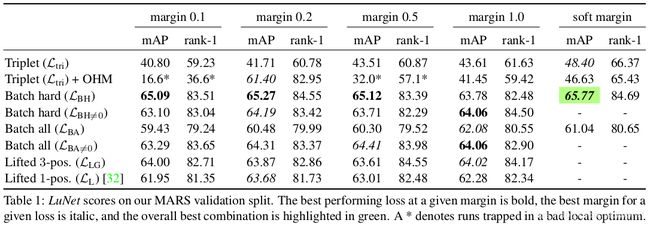
- 没有Hard Mining的Ltri往往模型效果不好,如果加上简单的
offline hard-mining(OHM),则效果很不稳定,有时候很好有时候完全崩掉。 - Batch Hard形式的LBH整体表现好于Batch All形式的LBA。作者猜测,训练后期很多三元组loss都是0,然后平均处理时会把仅剩的有用的信息给稀释掉。为了证明该猜想,作者计算平均loss时只考虑那些不为0的,用
LBA≠0表示,发现效果确实会变好。 - 在作者的行人重识别实验中,
Batch Hard + soft-margin的效果最好,但是不能保证在其他任务中这种组合依然是最好的,这需要更多的实验验证。
(2)To Pretrain or not to Pretrain?
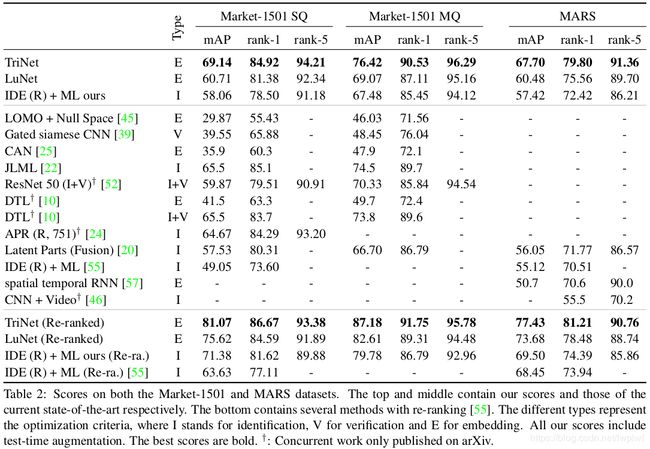
TriNet表示来自pre-trained model,LuNet是作者自己设计的一个普通网络,从头开始训练。
从上面的表格来看,利用pre-trained model确实可以获得更好一点的效果,但是从头开始训练的网络也不会太差。
特别的,pre-trained model往往体积较大模式固定,不如自己设计网络来的灵活。同时,pre-trained model往往有其自己的固定输入,我们如果修改其输入很可能会得到相反的效果。如下表:
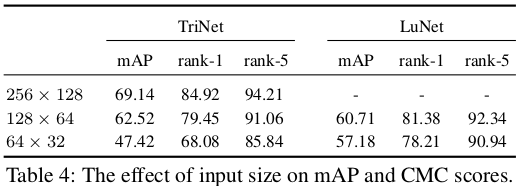
Trick
(1) 没有必要对输出特征进行归一化;
(2) 如果使用了hard mining,单纯的看loss变化往往不能正确把握训练的进程。作者推荐观察一个batch中的有效三元组个数,或者所有pair间的距离;
(3) 初始margin不宜过大。
LuNet网络结构

Reference
https://blog.csdn.net/qq_21190081/article/details/78417215
https://blog.csdn.net/xuluohongshang/article/details/78965580