OkHttp3错误异常: java.net.ProtocolException: unexpected end of stream 源码分析
之前在项目中调试部分上传附件的接口时会遇到unexpected end of stream错误,在项目所使用的网络框架是我基于OkGo封装的一个网络请求库,而OkGo内部则其实是基于OkHttp封装的。网上查阅了一下发现遇到这个问题的人挺多,导致这个异常的原因可能不止一种,本文主要针对我遇到的这种情况下导致这个问题的原因分析,做个记录。
首先看一下错误日志:

看到这个错误的原因,起初我有点担心可能是我封装库或者OkGo库的原因,会不会是封装的过程有什么问题?因为在项目中使用的请求代码都是高度封装过的,为了排除这个担忧,我将请求代码换成原生的OkHttp的方式进行请求:
public void add(final String action) {
showProgressDialog(action);
RequestParams params = getParams(action);
String url = mApi.getApiByName(action);
File file = mFileList.get(0);
OkHttpClient okHttpClient = new OkHttpClient();
MultipartBody.Builder builder = new MultipartBody.Builder();
builder.setType(MultipartBody.FORM);
StringHashMap paramStrs = params.getAllParamStrs();
for (String key : paramStrs.getKeyList()) {
builder.addFormDataPart(key, paramStrs.get(key));
}
RequestBody fileBody = RequestBody.create(MediaType.parse("image/jpeg"), file);
builder.addFormDataPart("attachFiles", file.getName(), fileBody);
RequestBody requestBody = builder.build();
Request request = new Request.Builder()
.url(url)
.post(requestBody)
.build();
okHttpClient.newCall(request).enqueue(new okhttp3.Callback(){
@Override
public void onFailure(Call call, IOException e) {
TQLog.e("OkHttp", "onFailure: "+e.toString());
}
@Override
public void onResponse(Call call, Response response) throws IOException {
ResponseBody body = response.body();
if (body != null) {
TQLog.e("OkHttp", "onResponse: " + body.string());
} else {
TQLog.e("OkHttp", "onResponse: null");
}
}
});
}
我原来的请求方式是这样的(封装后的):
HttpRequest request = new BaseHttpRequest(url, params, callback, tag)
HttpClient.getInstance().post(request );
原生的OkHttp请求方式还是很麻烦的,要写一大坨代码,封装后的方式使用比较简单,这里先不管这个,在换成原生的OkHttp请求方式后还是会报同样的错误,这下排除了封装库的原因,确定了这个问题是由OkHttp产生的。
直接去看OkHttp源码(所用的版本为3.8.1),错误发生在Http1Codec这个类的第387行:
可以看到是在内部类FixedLengthSource当中,387这一行有个注释:The server didn’t supply the promised content length. 意思是说服务器没有返回承诺的content length(看到这句话其实能大概知道原因了跟content-length有关系)。继续看,这里的if判断source.read(sink, Math.min(bytesRemaining, byteCount))如果这个方法返回的值为-1就会直接抛出ProtocolException异常,异常的描述就是我们看到的那句"unexpected end of stream",因此去看一下source.read这个方法是干嘛的,source这个对象是BufferedSource接口类型,而BufferedSource则继承了Source接口,在Source接口可以看到这个方法的注释:

意思是从当前Source中读取byteCount个字节到第一个参数Buffer当中,返回值是读取的字节数,如果返回-1则表示Source已经没有东西可以读取了。
这个看上去跟平时用的InputStrem.read差不多,其实,这个Source接口以及还有一个Sink接口都来自Okio库,Okio同样是square公司开源的一个独立的开源库,同时它被用作OkHttp底层的IO读写库,Okio主要封装了对应java的InputStrem和OutputStream的读写功能,而Source和Sink则分别对应输入流和输出流,提供了更加易用高效的处理方式,是一个非常牛bility的IO库(官方是这样描述的…)。
这里暂时先不去深入研究Okio,已经知道read返回-1的含义了,再回到调用source.read的地方,source.read方法第二个参数Math.min(bytesRemaining, byteCount)取了两者的最小值,bytesRemaining这个对象是什么意思呢,可以看到它是在FixedLengthSource的构造函数中被赋值的,继续在Http1Codec中搜索创建FixedLengthSource的地方:

找到一个newFixedLengthSource方法,继续:

可以看到最终是在openResponseBody方法中调用的getTransferStream方法中调用了这个newFixedLengthSource方法,而参数值则是从Response对象中取的响应头Header里的ContentLength字段。因此bytesRemaining变量的初始值就是ContentLength,再回到原来报错的387行,source.read方法第二个参数Math.min(bytesRemaining, byteCount)这个bytesRemaining已经清楚了,那这个byteCount是什么呢,它是由read方法传进来的,我们回到开头看错误日志栈的第二行定位是在RealBufferedSource类的67行:

从错误栈可以推测这个地方的source对象一定是跟Http1Codec类中的FixedLengthSource是相同类型,这个后面再分析,先看这里67行第二个参数为Segment.SIZE,Segment.SIZE这个值的大小为8192(也就是8k):

Segment也是Okio库中的东西,
看到这里,就不难理解开头Http1Codec类报错的第387行了,bytesRemaining的初始大小值是ContentLength, 每次将以bytesRemaining和8192这两个值中较小的那个数值作为会从source中读取的字节数,如果读取没有报错则会从bytesRemaining中减去已读取的长度,当下一次再调用这个方法时bytesRemaining就是body中剩余正文的字节长度。如果读取报错返回-1则直接抛出unexpected end of stream异常。那为什么会返回-1呢,肯定是在某一次读取的时候,bytesRemaining还有值但是source已经读到流的末尾没有东西可读了,也就是source资源已经枯竭,如source.read方法所注释的:Returns the number of bytes read, or -1 if this source is exhausted
因此,在项目中出现这个错误的原因肯定是跟服务器返回值的响应头中Content-Length的长度有关,为了验证这个问题,我将报错接口的返数据通过抓包出来分析了一下:
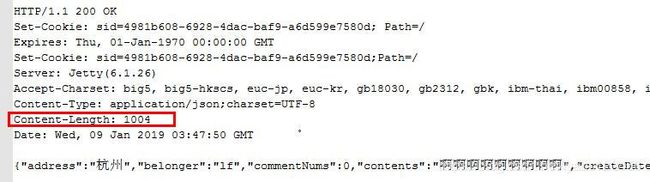
可以看到响应头中返回的Content-Length的大小是1004,charset是UTF-8,那么正常情况下响应正文也就是body中的字符串按照UTF-8编码的字节长度应该等于Content-Length的大小1004,于是,我写了一下代码把正文按照UTF-8编码的字节长度打印出来,打印代码很简单,就一句话:
TQLog.e(TAG, "length = " + str.getBytes(StandardCharsets.UTF_8).length);
果然,打印出的长度值为length = 992,居然跟响应头中的Content-Length的值不一样!这就有问题了啊,按照OkHttp中Http1Codec类报错的方法的逻辑,source.read(sink, Math.min(bytesRemaining, byteCount))这里第二个参数,将会在1004和8k之间取最小值为1004,也就是说会直接从body的输入源对象source读取1004个字节的长度,然而实际响应正文返回字符串的长度不足1004只有992。最终source必然会不够读取返回-1,从而报错。
当然实际debug发现过程跟这个有点出入,但是差别不大,实际当bytesRemaining比byteCount小时,source.read读取时不是一次性把source读完的,这主要是有个方法导致的,但是总的bytesRemaining跟Content-Length是一致的。
问题是清楚了,最后,把完整的流程梳理一遍,看一下整个过程是怎样的
首先看下Http1Codec这个类是在哪里创建的, 搜索有两个地方,一个是创建https tunnel的地方,目前接口不是https的, 所以排除,就剩下RealConnection类中的:
public HttpCodec newCodec(
OkHttpClient client, StreamAllocation streamAllocation) throws SocketException {
if (http2Connection != null) {
return new Http2Codec(client, streamAllocation, http2Connection);
} else {
socket.setSoTimeout(client.readTimeoutMillis());
source.timeout().timeout(client.readTimeoutMillis(), MILLISECONDS);
sink.timeout().timeout(client.writeTimeoutMillis(), MILLISECONDS);
return new Http1Codec(client, streamAllocation, source, sink);
}
}
这个方法是在StreamAllocation类中的newStream方法调用的:
public HttpCodec newStream(OkHttpClient client, boolean doExtensiveHealthChecks) {
int connectTimeout = client.connectTimeoutMillis();
int readTimeout = client.readTimeoutMillis();
int writeTimeout = client.writeTimeoutMillis();
boolean connectionRetryEnabled = client.retryOnConnectionFailure();
try {
RealConnection resultConnection = findHealthyConnection(connectTimeout, readTimeout,
writeTimeout, connectionRetryEnabled, doExtensiveHealthChecks);
HttpCodec resultCodec = resultConnection.newCodec(client, this);
synchronized (connectionPool) {
codec = resultCodec;
return resultCodec;
}
} catch (IOException e) {
throw new RouteException(e);
}
}
而这个方法又是在ConnectInterceptor中的intercept方法调用的:
@Override
public Response intercept(Chain chain) throws IOException {
RealInterceptorChain realChain = (RealInterceptorChain) chain;
Request request = realChain.request();
StreamAllocation streamAllocation = realChain.streamAllocation();
// We need the network to satisfy this request. Possibly for validating a conditional GET.
boolean doExtensiveHealthChecks = !request.method().equals("GET");
HttpCodec httpCodec = streamAllocation.newStream(client, doExtensiveHealthChecks);
RealConnection connection = streamAllocation.connection();
return realChain.proceed(request, streamAllocation, httpCodec, connection);
}
这个就是拦截器了,可以看到httpCodec最终被传到了RealInterceptorChain 对象中
我们在使用okHttpClient.newCall(request)时创建了一个RealCall对象:
/**
* Prepares the {@code request} to be executed at some point in the future.
*/
@Override
public Call newCall(Request request) {
return new RealCall(this, request, false /* for web socket */);
}
在RealCall类中:
@Override
protected void execute() {
boolean signalledCallback = false;
try {
Response response = getResponseWithInterceptorChain();
if (retryAndFollowUpInterceptor.isCanceled()) {
signalledCallback = true;
responseCallback.onFailure(RealCall.this, new IOException("Canceled"));
} else {
signalledCallback = true;
responseCallback.onResponse(RealCall.this, response);
}
} catch (IOException e) {
if (signalledCallback) {
// Do not signal the callback twice!
Platform.get().log(INFO, "Callback failure for " + toLoggableString(), e);
} else {
responseCallback.onFailure(RealCall.this, e);
}
} finally {
client.dispatcher().finished(this);
}
}
}
execute()方法中调用了getResponseWithInterceptorChain()方法:
Response getResponseWithInterceptorChain() throws IOException {
// Build a full stack of interceptors.
List<Interceptor> interceptors = new ArrayList<>();
interceptors.addAll(client.interceptors());
interceptors.add(retryAndFollowUpInterceptor);
interceptors.add(new BridgeInterceptor(client.cookieJar()));
interceptors.add(new CacheInterceptor(client.internalCache()));
interceptors.add(new ConnectInterceptor(client));
if (!forWebSocket) {
interceptors.addAll(client.networkInterceptors());
}
interceptors.add(new CallServerInterceptor(forWebSocket));
Interceptor.Chain chain = new RealInterceptorChain(
interceptors, null, null, null, 0, originalRequest);
return chain.proceed(originalRequest);
}
在这里除了用户添加的拦截器以外,OKHttp内部添加了5个拦截器,这5个拦截器最终会被添加到一个RealInterceptorChain对象中,在实际请求过程中会依次调用每个拦截器的intercept方法,并在该方法中调用chain.proceed方法,而在RealInterceptorChain类的proceed方法中会调用下一个拦截器的intercept方法:
// Call the next interceptor in the chain.
RealInterceptorChain next = new RealInterceptorChain(
interceptors, streamAllocation, httpCodec, connection, index + 1, request);
Interceptor interceptor = interceptors.get(index);
Response response = interceptor.intercept(next);
所以,httpCodec对象从ConnectInterceptor开始会被带到最终的拦截器CallServerInterceptor当中,CallServerInterceptor是干嘛的呢:

注释说这个是拦截器链当中的最后一个拦截器了,用来向服务器发起一个network请求
因此我们代码在请求的回调中:
okHttpClient.newCall(request).enqueue(new okhttp3.Callback(){
@Override
public void onFailure(Call call, IOException e) {
TQLog.e("OkHttp", "onFailure: "+e.toString());
}
@Override
public void onResponse(Call call, Response response) throws IOException {
ResponseBody body = response.body();
if (body != null) {
String string = body.string();
TQLog.e("OkHttp", "onResponse: " + string);
} else {
TQLog.e("OkHttp", "onResponse: null");
}
}
});
这里onResponse方法中的body.string(),这个body就是从最后一个拦截器CallServerInterceptor返回的Response中获取的:
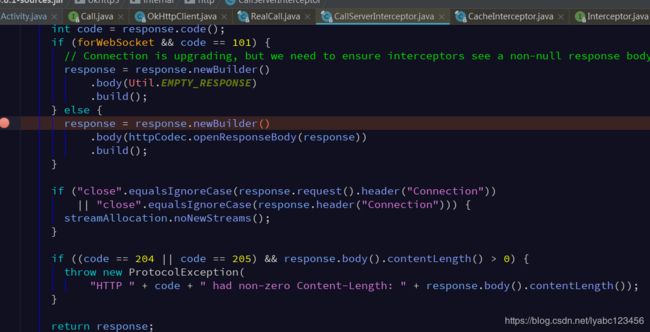
可以看到CallServerInterceptor中的Response对象的body正是从httpCodec的openResponseBody获取的,而httpCodec就是从chain中获取的:

所以我们代码onResponse回调中拿到的body其实就是Http1Codec类返回的openResponseBody返回的对象:
@Override public ResponseBody openResponseBody(Response response) throws IOException {
Source source = getTransferStream(response);
return new RealResponseBody(response.headers(), Okio.buffer(source));
}
private Source getTransferStream(Response response) throws IOException {
if (!HttpHeaders.hasBody(response)) {
return newFixedLengthSource(0);
}
if ("chunked".equalsIgnoreCase(response.header("Transfer-Encoding"))) {
return newChunkedSource(response.request().url());
}
long contentLength = HttpHeaders.contentLength(response);
if (contentLength != -1) {
return newFixedLengthSource(contentLength);
}
// Wrap the input stream from the connection (rather than just returning
// "socketIn" directly here), so that we can control its use after the
// reference escapes.
return newUnknownLengthSource();
}
public Source newFixedLengthSource(long length) throws IOException {
if (state != STATE_OPEN_RESPONSE_BODY) throw new IllegalStateException("state: " + state);
state = STATE_READING_RESPONSE_BODY;
return new FixedLengthSource(length);
}
在openResponseBody方法中先调用getTransferStream方法生成了一个Source对象,而这个方法中其实就是调用newFixedLengthSource方法直接new了一个FixedLengthSource对象,FixedLengthSource构造函数中传入的参数正是在文章开头分析的bytesRemaining的值,没错,它就是header中的contentLength。
然后在openResponseBody方法中将生成的这个Source对象经过Okio.buffer(source)封装之后传递给了RealResponseBody并返回该对象(也就是说onResponse回调中的body其实就是它),来看一下Okio.buffer(source)干了什么:
public static BufferedSource buffer(Source source) {
return new RealBufferedSource(source);
}
这里直接根据传入的FixedLengthSource对象new了一个RealBufferedSource对象,再看RealBufferedSource类:
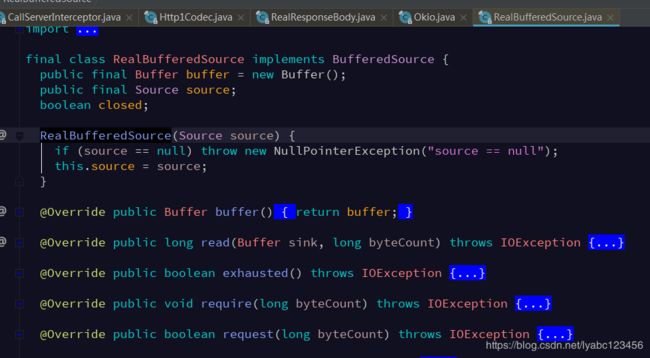
可以看出这是一个装饰者对象,对读写操作进行了包装
到这里基本串起来了,再回去看onResponse回调中的body.string():
public final String string() throws IOException {
BufferedSource source = source();
try {
Charset charset = Util.bomAwareCharset(source, charset());
return source.readString(charset);
} finally {
Util.closeQuietly(source);
}
}
string()方法的第一行source(),其实就是包装了FixedLengthSource对象的RealBufferedSource对象,我们看一下Util.bomAwareCharset方法:
public static Charset bomAwareCharset(BufferedSource source, Charset charset) throws IOException {
if (source.rangeEquals(0, UTF_8_BOM)) {
source.skip(UTF_8_BOM.size());
return UTF_8;
}
if (source.rangeEquals(0, UTF_16_BE_BOM)) {
source.skip(UTF_16_BE_BOM.size());
return UTF_16_BE;
}
if (source.rangeEquals(0, UTF_16_LE_BOM)) {
source.skip(UTF_16_LE_BOM.size());
return UTF_16_LE;
}
if (source.rangeEquals(0, UTF_32_BE_BOM)) {
source.skip(UTF_32_BE_BOM.size());
return UTF_32_BE;
}
if (source.rangeEquals(0, UTF_32_LE_BOM)) {
source.skip(UTF_32_LE_BOM.size());
return UTF_32_LE;
}
return charset;
}
这个方法的代码大概是判断UTF字符编码集的作用,里面会调用到source.rangeEquals,于是去看一下RealBufferedSource的rangeEquals方法:
@Override public boolean rangeEquals(long offset, ByteString bytes) throws IOException {
return rangeEquals(offset, bytes, 0, bytes.size());
}
@Override
public boolean rangeEquals(long offset, ByteString bytes, int bytesOffset, int byteCount)
throws IOException {
if (closed) throw new IllegalStateException("closed");
if (offset < 0
|| bytesOffset < 0
|| byteCount < 0
|| bytes.size() - bytesOffset < byteCount) {
return false;
}
for (int i = 0; i < byteCount; i++) {
long bufferOffset = offset + i;
if (!request(bufferOffset + 1)) return false;
if (buffer.getByte(bufferOffset) != bytes.getByte(bytesOffset + i)) return false;
}
return true;
}
在for循环里最终会调用一个request方法:
@Override
public boolean request(long byteCount) throws IOException {
if (byteCount < 0) throw new IllegalArgumentException("byteCount < 0: " + byteCount);
if (closed) throw new IllegalStateException("closed");
while (buffer.size < byteCount) {
if (source.read(buffer, Segment.SIZE) == -1) return false;
}
return true;
}
这个request方法也正是我们开头错误日志栈中的第二行所处的方法,正如前面分析的,我们知道此时的这个RealBufferedSource对象包装的source对象正是FixedLengthSource对象,因此这个地方就会调用到FixedLengthSource的read方法:
@Override
public long read(Buffer sink, long byteCount) throws IOException {
if (byteCount < 0) throw new IllegalArgumentException("byteCount < 0: " + byteCount);
if (closed) throw new IllegalStateException("closed");
if (bytesRemaining == 0) return -1;
long read = source.read(sink, Math.min(bytesRemaining, byteCount));
if (read == -1) {
endOfInput(false); // The server didn't supply the promised content length.
throw new ProtocolException("unexpected end of stream");
}
bytesRemaining -= read;
if (bytesRemaining == 0) {
endOfInput(true);
}
return read;
}
所以到这我们知道onResponse回调中的body.string()内部在判断UTF字符集编码的时候就会首先调用一次FixedLengthSource的read方法(实测中UTF-8编码的这里只会调用一次,经过这次read之后bytesRemaining会减去读到的字节数)。再回到body.string()方法中看一下source.readString(charset)的实现(在RealBufferedSource中):
@Override
public String readString(Charset charset) throws IOException {
if (charset == null) throw new IllegalArgumentException("charset == null");
buffer.writeAll(source);
return buffer.readString(charset);
}
再看buffer.writeAll(source):
@Override
public long writeAll(Source source) throws IOException {
if (source == null) throw new IllegalArgumentException("source == null");
long totalBytesRead = 0;
for (long readCount; (readCount = source.read(this, Segment.SIZE)) != -1; ) {
totalBytesRead += readCount;
}
return totalBytesRead;
}
so…这里又会调用到FixedLengthSource的read方法,而且这里会循环读,直到度完为止,经过这一步之后在执行readString方法中的最后一行时,其实buffer中已经有字符串数据了,里面的代码就是new了String对象而已,就不看了。
所以,总结一下,onResponse中body.string()会先调用一次FixedLengthSource的read方法,这是由于Util.bomAwareCharset方法中判断UTF字符集的过程中会调用FixedLengthSource的read方法,之后就是for循环读取了,每次读取bytesRemaining和8k之间较小的那个字节数。
在实测中,测试了一个返回4000多个字节(UTF-8)的接口,分两次读取完毕,第一次读取了1000多字节,第二次读取了3000多字节,假如你的返回数据超过8k, 则会按照读取8k大小来。
假设服务端返回的Content-Length为13000,但是实际返回的正文长度只有11000,那么这样会有什么后果呢:
(1)初始化FixedLengthSource,bytesRemaining = Content-Length = 13000
(2)首先,Util.bomAwareCharset方法可能会读取一部分(暂时不知道读取的确切的数量,假设是1000),那么bytesRemaining = 13000 - 1000 = 12000
(3)循环中读取剩余的字节,每次读bytesRemaining和8192最少的那个字节数,所以这一步的结果是bytesRemaining = 12000 - 8192 = 3808
(注意,到这一步已读:1000+8192 = 9192,实际长度11000,也就是实际还剩:11000-9192 = 1808)
(4)循环中再一次读取,读取3808 和8192最少的那个字节数,也就是准备从source中读3808个字节,但实际只剩下1808了,因此只能读取到1808个字节,这一步读取之后source中就没有东西了,因此这一步的结果是bytesRemaining = 3808 - 1808 = 2000
(5)由于bytesRemaining 还是大于0的,所以循环读取还会继续,读取2000和和8192最少的那个字节数,也就是准备读2000个字节,但是这一次由于source已经枯竭,read只会返回-1,因此触发了开始的错误异常条件。
所以,此问题要想解决必须在服务器端修正响应头中的Content-Length字段,Content-Length必须严格等于响应正文【按照响应头中返回的charset编码】的字节数,或者不用Content-Length字段(如使用Transfer-Encoding:chunked)。
以上,FixedLengthSource中的read方法中调用的source对象的read方法没有进去详细看,其实它实现是在Okio类的source(final InputStream in, final Timeout timeout)方法中实现的,这个方法是对socket返回的输入流InputStream对象进行读取,详细的可以自己看看。