PIX2PIXHD改进
新目标函数以及新颖的多尺度生成器和鉴别器
例如样式转移[13],修复[41],着色[58]和恢复[14]。但是,大多数这些工作缺少用户调整当前结果或探索输出空间的界面。为了解决这个问题,朱等人。 [64]开发了一种优化方法,用于根据GAN学习的先验来编辑对象外观。最近的作品[21,46,59]还提供了用户界面,用于从低级线索(如颜色和草图)创建新颖的图像
我们的界面受到先前数据驱动图形系统的启发[6,23,29]。但是我们的系统允许更灵活的操作并实时产生高分辨率结果。
coarse-to-fine G
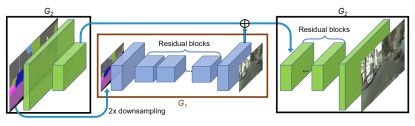
两个子网:G1和G2。我们将G1称为全局生成器网络,将G2称为本地增强器网络。
我们的全局G建立在所提出的架构之上约翰逊等人(参考)。 [22],已证明成功用于高达512×512的图像上的神经样式传递。它由3个分量组成:concolutional fron-end G1(F),a set of residual blocksG1(R)[18],和transposed convolutional back-endG1(B)。
在训练过程中,我们首先训练全局G,然后按照它们的分辨率训练本地增强器。 然后,我们联合微调所有网络。 我们使用此G设计有效地聚合图像合成任务的全局和本地信息。 我们注意到,这种多分辨率流水线在计算机视觉中是一种成熟的实践[4],并且双尺度通常就足够了[3]。 在最近的无条件GAN [9,19]和条件图像生成[5,57]中可以找到类似的想法但不同的架构(参考)。
Multi-scale D
multi-scale D。我们使用3个具有相同网络结构但在不同图像scale下工作的鉴别器。我们将鉴别器称为D1,D2和D3。具体来说,我们将真实和合成的高分辨率图像下采样2倍和4倍,以创建3个尺度的图像金字塔。然后训练D,D1,D2和D3以分别在3个不同的scale上区分真实和合成图像
然后成为一个多任务学习问题Multi-task:目标函数:
在无条件的GAN中已经提出了使用相同图像尺度的多个GAN鉴别器[12]。 Iizuka等。(参考) [20]将全局图像分类器添加到条CGAN以合成用于修复的全局相干内容。在这里,我们将设计扩展到不同图像尺度的多个鉴别器,以便对高分辨率图像进行建模。
改善对抗性损失
我们改善了方程式中的GAN损失。结合基于鉴别器的特征匹配损失。具体,我们从鉴别器的多个层中提取特征,并学习如何匹配来自真实和合成图像的这些中间表示。为了便于呈现,我们将鉴别器Dk的第i层特征提取器表示为D(i)(从输入到Dk的第i层)。然后将特征匹配损失LFM(G,Dk)计算为:
其中T是层的总数,Ni表示每层中的单元数。我们的GAN鉴别器特征匹配损失与感知损失有关[11,13,22],已经证明它对图像超分辨率[32]和样式转移[22]有用。在我们的实验中,我们讨论了鉴别器特征匹配损失和感知损失如何共同用于进一步改善性能。我们注意到在VAE-GAN中使用了类似的损失[30]。
我们的完整目标将GAN损失和特征匹配损失结合起来:
其中λ控制着两个术语的重要性。请注意,对于特征匹配损失LFM,Dk仅用作特征提取器,并且不会使丢失LFM最大化
3.3Using Instance Maps
现有的图像合成方法仅利用语义标签图[5,21,25],。此map不区分同一类别的对象,另一方面,实例级语义标签映射包含每个单独对象的唯一对象ID。我们认为实例映射提供的最重要的信息(在语义标签映射中不可用)是对象边界。 首先计算实例边界图(图4b)(1boundary map 获得)如果实例边界映射中的像素的对象ID与其任何4个邻居不同,则该实例边界映射中的像素为1,否则为0。(2过程)然后将instance boundary map与semantic label map的one-hot vector表示连接,并馈送到G中。类似地,D的input是instance boundary map,semantic label map和真实/合成图像的通道顺序连接。图5b显示了通过使用对象边界来演示改进的示例。我们的用户研究在Sec。图4还示出了使用实例边界图训练的模型呈现更多照片般逼真的对象边界。
3.4Learning an Instance-level Feature Embedding
为了生成不同的图像并允许实例级控制,添加额外的低维特征通道作为生G的输入。请注意,由于特征通道是连续的数量,因此我们的模型原则上能够生成无限多的图像。
生成低维特征
训练编码器网络E以找到每个实例的地面实况目标的低维特征向量。我们的特征编码器架构是标准的编码器 - 解码器网络
为了确保每个实例中的特征一致,我们在编码器的输出中添加一个instance-wise average pooling layer,以计算对象实例的平均特征。然后将平均特征广播到实例的所有像素位置。图6显示了编码特征的示例。
我们用方程式中的G(s,E(x))代替G(s)。 (5)并与G和D一起训练encoder。 在训练encoder之后,我们在训练图像中的所有实例上运行它并记录所获得的特征。 然后,我们针对每个语义类别对这些功能执行K-means聚类。 因此,每个群集编码特定样式的特征,例如道路的沥青或鹅卵石纹理。 在推理时,我们随机选择一个聚类中心并将其用作编码特征。 这些功能与标签贴图连接在一起,并用作生成器的输入。 我们试图在特征空间上强制执行Kullback-Leibler损失[28],以便在最近的工作[66]中使用更好的测试时间采样,但发现用户可以直接调整每个对象的潜在向量。 相反,对于每个对象实例,我们提供K模式供用户选择。