调用链监控的基础原理
在介绍调用链监控工具之前,我们首先需要知道在微服务架构系统中经常会遇到两个问题:
- 跨微服务的API调用发生异常,要求快速定位(比如5分钟以内)出问题出在哪里,该怎么办?
- 跨微服务的API调用发生性 能瓶颈,要求迅速定位(比如5分钟以内)出系统瓶颈,该怎么办?
一般来说要解决这两个问题或者与之类似的问题,就需要用到调用链监控工具。那么调用链监控工具是怎么实现问题的快速定位的呢?这就需要我们理解调用链监控的基础实现原理,我们来看一张图:
图中有两个微服务分别是内容中心和用户中心,其中内容中心的/shares/1接口会调用用户中心的/users/1接口,这里就产生了一个调用链。我们可以将调用的过程分为四个阶段或者说状态,当内容中心发送调用请求时处于“client send”状态,用户中心接收到调用请求时处于“server receive”状态,用户中心处理完请求并返回结果时处于“server send”状态,最后内容中心接收到响应结果时处于“client receive”状态。
假设,调用链流转每个状态时都会向一张数据表里插入一些数据,如下图所示:
表字段说明:
- id:自增id
- span_id:唯一id
- pspan_id:父级span_id
- service_name:服务名称
- api:api路径
- stage:阶段/状态
- timestamp:插入数据时的时间戳
这是一张典型的自表一对多的表结构,根据这张表的数据,就可以实现对以上所提到的两个问题进行快速定位。首先对于第一个问题,可以通过查询表内的数据行数,判断调用链在哪个阶段中断了。例如表中只有uuid1和uuid2两条数据,就可以判断出是user-center的接口出现了问题,没有正常返回结果。再如表中只有uuid1、uuid2及uuid3这三条数据,就可以判断出content-center没有正常接收到user-center返回的结果,以此类推。如此一来,就可以通过表中的数据快速定位出跨微服务的API调用是在哪个阶段发生了异常。
对于第二个问题,可以通过计算timestamp分析哪个调用比较耗时。例如上图中的t2 - t1可以得出请求的发送到请求的接收所消耗的时间,再如t3 - t2可以得出/users/1这个接口的调用耗时,而t4 - t1则可以得出整个调用链的耗时,以此类推。所以当跨微服务的API调用发生性能瓶颈时,就可以通过分析各个调用接口的耗时,快速定位出是哪个微服务接口拖慢了整个调用链耗时。
以上举例简述了实现调用链监控的基础原理,虽然未必所有的调用链监控工具都是这么实现的,但基本都异曲同工,或在其之上进行了一些拓展。所以只要理解了这一部分,在学习各种调用链监控工具时就会比较快上手。
Spring Cloud Sleuth简介
Spring Cloud Sleuth实现了一种分布式的服务链路跟踪解决方案,通过使用Sleuth可以让我们快速定位某个服务的问题。简单来说,Sleuth相当于调用链监控工具的客户端,集成在各个微服务上,负责产生调用链监控数据。
官方文档地址如下:
http://cloud.spring.io/spring-cloud-static/spring-cloud-sleuth/2.0.1.RELEASE/single/spring-cloud-sleuth.html
一些概念:
-
Span(跨度):Span是基本的工作单元。Span包括一个64位的唯一ID,一个64位trace码,描述信息,时间戳事件,key-value 注解(tags),span处理者的ID(通常为IP)。
最开始的初始Span称为根span,此span中span id和 trace id值相同。 -
Trance(跟踪):包含一系列的span,它们组成了一个树型结构
- Annotation(标注):用于及时记录存在的事件。常用的Annotation如下:
- CS(Client Sent 客户端发送):客户端发送一个请求,表示span的开始
- SR(Server Received 服务端接收):服务端接收请求并开始处理它。(SR - CS)等于网络的延迟
- SS(Server Sent 服务端发送):服务端处理请求完成,开始返回结束给服务端。(SR - SS)表示服务端处理请求的时间
- CR(Client Received 客户端接收):客户端完成接受返回结果,此时span结束。(CR - CS)表示客户端接收服务端数据的时间
如果一个服务的调用关系如下: 
那么此时将Span和Trace在一个系统中使用Zipkin注解的过程图形化如下: 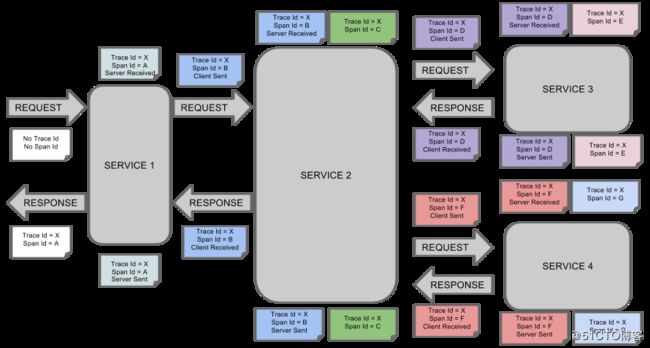
每个颜色的表明一个span(总计7个spans,从A到G),每个span有类似的信息
Trace Id = X
Span Id = D
Client Sent此span表示span的Trance Id是X,Span Id是D,同时它发送一个Client Sent事件
spans 的parent/child关系图形化如下: 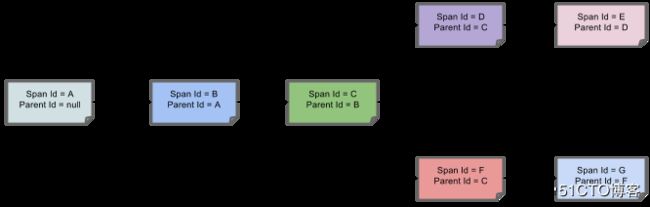
整合Spring Cloud Sleuth
了解完基本的一些概念后,我们来在订单服务和商品服务中,集成spring cloud sleuth以及zipkin。在两个服务的pom.xml文件中,增加如下依赖:
org.springframework.cloud
spring-cloud-starter-sleuth
为了更详细的查看服务通信时的日志信息,我们可以将Feign和Sleuth的日志级别设置为debug。在两个项目的配置文件中,加入如下内容即可:
logging:
level:
org.springframework.cloud.openfeign: debug
org.springframework.cloud.sleuth: debug启动订单、商品服务项目,然后访问创建订单的接口,订单服务的控制台会输出一段这样的信息:
[order,6c8ecdeefb0fc723,cc4109a6e8e56d1c,false]商品服务的控制台也会输出类似的信息,如下:
[product,6c8ecdeefb0fc723,40cdc34e745d59e7,false]说明:
- product: 看也知道是服务名称
- 6c8ecdeefb0fc723: 是TranceId,一条链路中,只有一个TranceId
- 40cdc34e745d59e7:则是spanId,链路中的基本工作单元id
- false:表示是否将数据输出到其他服务,true则会把信息输出到其他可视化的服务上观察
Zipkin搭建与整合
通过Sleuth产生的调用链监控信息,让我们可以得知微服务之间的调用链路,但是监控信息只输出到控制台始终不太方便查看。所以我们需要一个图形化的工具,这时候就轮到zipkin出场了。Zipkin是Twitter开源的分布式跟踪系统,主要用来收集系统的时序数据,从而追踪系统的调用问题。zipkin官网地址如下:
https://zipkin.io/
zipkin结构图: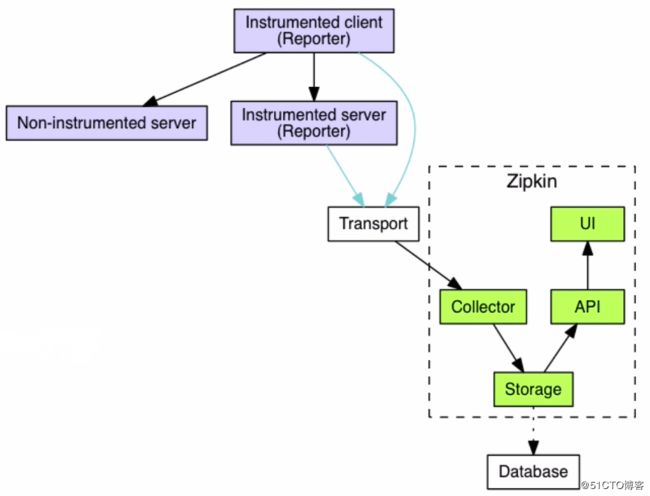
接下来我们搭建一个zipkin服务器。
方式1,使用Zipkin官方的Shell下载,使用如下命令可下载最新版本:
[root@01server ~]# curl -sSL https://zipkin.io/quickstart.sh | bash -s下载下来的文件名为 zipkin.jar
方式2,到Maven中央仓库下载,使用浏览器访问如下地址即可:
https://search.maven.org/remote_content?g=io.zipkin.java&a=zipkin-server&v=LATEST&c=exec
下载下来的文件名为 zipkin-server-{版本号}-exec.jar
由于Zipkin实际是一个Spring Boot项目,所以使用以上两种方式下载的jar包,可以直接使用如下命令启动:
java jar {zipkin jar包路径}方式3,通过docker安装,命令如下:
[root@01server ~]# docker run -d -p 9411:9411 openzipkin/zipkin安装好后,使用浏览器访问9411端口,主页面如下所示:
然后在订单服务中将之前的sleuth依赖替换成如下依赖:
org.springframework.cloud
spring-cloud-starter-zipkin
在配置文件中,增加zipkin相关的配置项。如下:
spring:
...
zipkin:
base-url: http://127.0.0.1:9411/ # zipkin服务器的地址
# 关闭服务发现,否则Spring Cloud会把zipkin的url当做服务名称
discoveryClientEnabled: false
sender:
type: web # 设置使用http的方式传输数据
sleuth:
sampler:
probability: 1 # 设置抽样采集率为100%,默认为0.1,即10% 配置好后重启项目,并访问创建订单接口。下单成功后,到zipkin页面上就可以查看到order服务的链路信息了: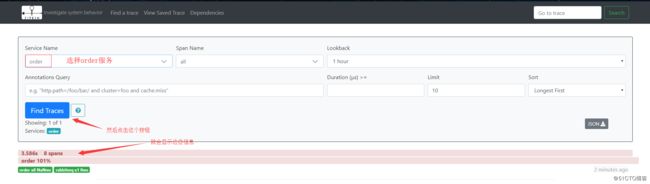
会有红色的信息表示有错误,点击上图中的红色信息后,可以进入到服务链路的查看页面,在这里可以看到整条服务链路,并且可以看到每一个服务调用的耗时,也可以看到是哪一步调用发生了错误:
点击每一行信息都可以查看其详情信息,例如我点击耗时46.236ms的那行信息,其详细信息如下:
Zipkin数据持久化
Zipkin默认是将监控数据存储在内存的,如果Zipkin挂掉或重启的话,那么监控数据就会丢失。所以如果想要搭建生产可用的Zipkin,就需要实现监控数据的持久化。而想要实现数据持久化,自然就是得将数据存储至数据库。好在Zipkin支持将数据存储至:
- 内存(默认)
- MySQL
- Elasticsearch
- Cassandra
Zipkin数据持久化相关的官方文档地址如下:
https://github.com/openzipkin/zipkin#storage-component
Zipkin支持的这几种存储方式中,内存显然是不适用于生产的,这一点开始也说了。而使用MySQL的话,当数据量大时,查询较为缓慢,也不建议使用。Twitter官方使用的是Cassandra作为Zipkin的存储数据库,但国内大规模用Cassandra的公司较少,而且Cassandra相关文档也不多。
综上,故采用Elasticsearch是个比较好的选择,关于使用Elasticsearch作为Zipkin的存储数据库的官方文档如下:
- elasticsearch-storage
- zipkin-storage/elasticsearch
既然选择Elasticsearch作为Zipkin的存储数据库,那么自然首先需要搭建一个Elasticsearch服务,单节点搭建比较简单,直接到官网下载压缩包,然后使用如下命令解压并启动即可(关于ES的版本选择需参考官方文档,目前Zipkin支持5.x、6.x及7.x):
[root@01server ~]# tar -zxvf elasticsearch-6.5.3-linux-x86_64.tar.gz # 解压
[root@01server ~]# cd elasticsearch-6.5.3/bin
[root@01server ~/elasticsearch-6.5.3/bin]# ./elasticsearch # 启动由于Elasticsearch不是本文的重点,这里不做不多的介绍,关于Elasticsearch的集群搭建可以参考如下文章:
- 使用docker安装elasticsearch伪分布式集群以及安装ik中文分词插件
- 搭建ELK日志分析平台(上)—— ELK介绍及搭建 Elasticsearch 分布式集群
- CentOS7 下安装 ElasticSearch 5.x 及填坑
搭建好Elasticsearch后,使用如下命令启动Zipkin,Zipkin就会切换存储类型为Elasticsearch,然后根据指定的连接地址连接Elasticsearch并存储数据:
STORAGE_TYPE=elasticsearch ES_HOSTS=localhost:9200 java -jar zipkin-server-2.11.3-exec.jarTips:
- 其中,
STORAGE_TYPE和ES_HOSTS是环境变量,STORAGE_TYPE用于指定Zipkin的存储类型是啥;而ES_HOSTS则用于指定Elasticsearch地址列表,有多个节点时使用逗号(,)分隔。
除此之外,还可以指定其他环境变量,参考下表:
关于其他环境变量,可参考官方文档:
- environment-variables
最后可以根据以下测试步骤,自行测试一下Zipkin是否能正常将监控数据持久化存储:
- 往Zipkin中存储一些数据
- 停止Zipkin
- 再次启动Zipkin,查看之前存储的数据是否存在,如果存在说明数据已被持久化
关于依赖关系图的问题
在上一小节中,简单介绍了Zipkin的数据持久化,并整合了Elasticsearch作为Zipkin的存储数据库。但此时会有一个问题,就是Zipkin在整合Elasticsearch后会无法分析服务之间的依赖关系图,因为此时数据都存储到Elasticsearch中了,无法再像之前那样在内存中进行分析。
想要解决这个问题,需要下载并使用Zipkin的一个子项目:
- Zipkin Dependencies
方式1,使用官方的Shell下载,使用如下命令可下载最新版本:
[root@01server ~]# curl -sSL https://zipkin.io/quickstart.sh | bash -s io.zipkin.dependencies:zipkin-dependencies:LATEST zipkin-dependencies.jar下载下来的文件名为 zipkin-dependencies.jar
方式2,到Maven中央仓库下载,使用浏览器访问如下地址即可:
https://search.maven.org/remote_content?g=io.zipkin.dependencies&a=zipkin-dependencies&v=LATEST
下载下来的文件名为 zipkin-dependencies-{版本号}.jar
下载好后,使用如下命令运行这个jar包即可分析Elasticsearch中存储的数据:
[root@01server ~]# STORAGE_TYPE=elasticsearch ES_HOSTS=localhost:9200 java -jar zipkin-dependencies-2.3.2.jar该jar包运行结束后,到Zipkin的界面上点开“Dependencies”就可以正常查看到依赖关系图了。
方式3,通过docker下载并运行,命令如下:
[root@01server ~]# docker run --env STORAGE_TYPE=elasticsearch --env ES_HOSTS=192.168.190.129:9200 openzipkin/zipkin-dependenciesTips:
这个Zipkin Dependencies属于是一个job,不是服务,即不会持续运行,而是每运行一次才分析数据。若想持续运行的话,需要自己写个定时脚本来定时运行这个job
使用Elasticsearch时Zipkin Dependencies支持的环境变量: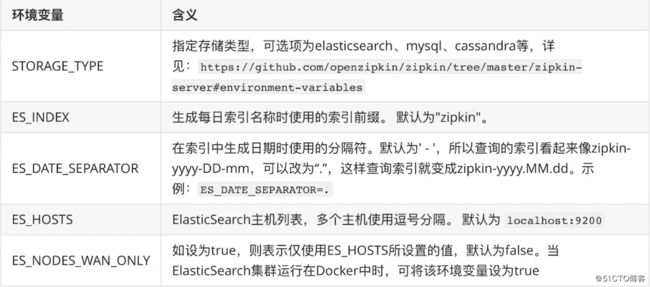
Zipkin Dependencies支持的其他环境变量:
- environment-variables
Zipkin Dependencies默认分析的是当天的数据,可以通过如下命令让Zipkin Dependencies分析指定日期的数据: