2018中国高校计算机大赛—大数据挑战赛(top2解题方案)
比赛链接:https://www.kesci.com/home/competition/5ab8c36a8643e33f5138cba4/leaderboard/1
相关链接:https://mp.weixin.qq.com/s/fSRB5T3himBEYrLwW9p62A
比赛介绍:https://mp.weixin.qq.com/s/vYtcnwLtHsb70viejBR3Rw
经过激烈的竞争,从俩千多人,一千二百多支队伍,从初赛到复赛再到决赛的答辩,最终拿到了第二的名次,虽然有点遗憾,但参加这个比赛收获了很多,对大数据领域又有了新的认识,在过程中,最重要的是坚持,有新的想法要敢于尝试。总结一下,个人觉得数据挖掘类的题目更多的应该先去了解数据,理解数据,对所涉及的业务场景有一定的了解,这样在特征工程的时候可以更合理的构造出强特出来,同时掌握一些必备的统计知识,用来构造基础特征也是必备的,除此之外,多学习一些经典算法,对构造特征也非常有用。以下分享一下该比赛的思路。
解题思路 :
题目是给定1-30天时间内的四个日志数据,通过这些数据来预测未来一段时间(即31-37天)活跃(即出现在以上四个日志中任意一个)的用户。经过分析,判定该问题是一个典型的二分类问题,也就是说给定一个用户id,让我们来预测这个用户是活跃或者不活跃。那么首先考虑如何构造出线上线下的训练集以及它的标签,还有线上线下测试集以及它的标签。
一、滑动窗口
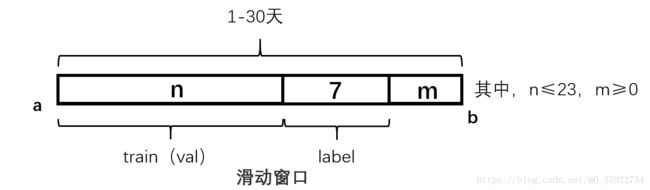
图(一)
如图一所示,我们采用滑动窗口的算法思想,给定a到b,也就是1-30天区间,我们定义n和m,其中n是构造训练集或验证集的区间,紧接着的后7天是构造标签的区间。其中,n小于等于23,m大于等于0。这样满足这种条件的我们可以滑动出很多个窗口,理论上讲这样我们训练集的样本可以构造出很多个,但是经过仔细分析与思考,我们总结了窗口必须满足以下两个条件
(1)保持线上与线下窗口间隔一致。
(2)满足数据分布的周期性。
我们看第一点,假如我们以构造训练集越多越好的原则去构造,那么变长窗口当然是1-2,1-3,1-4,一直到1-23,但是这样会出现一个问题,也就是线上和线下的窗口间隔不一致,这样会导致线上和线下构造的特征数据分布不一致,很容易出现过拟合现象。因此我们从后往前推,使得线上线下得窗口间隔一致,还是以构造训练集最多原则构造窗口,那么这样构造就是1-30,1-23,1-16,1-9,1-2(为什么间隔是7呢,因为这7天是用来构造label的,也就是线上和线下最小的间隔)。
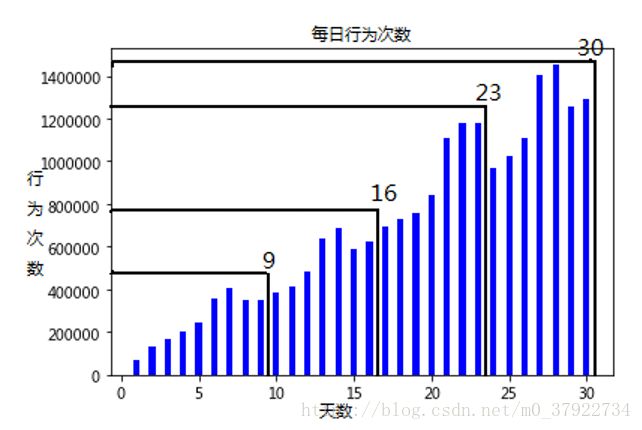
图(二)
第二个原则,我们是根据图二得出的规律,也就是窗口还需要满足数据分布的周期性,可以看出,每个窗口每天的行为次数都是周期性的增长,除了1-2这个窗口之外。因此1-2这个窗口就被去掉了,并且1-2这个数据窗口太小,信息量太小,显然也就舍去了。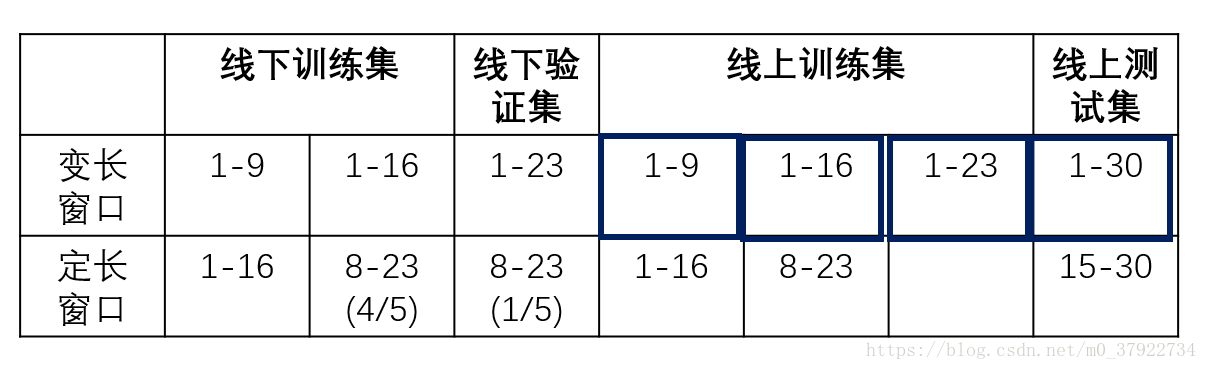
表(一)
同样的道理,所以最终我们构造出了两个可行的窗口,如表一所示,第一个是变长窗口,线下训练集是1-9,1-16,线下验证集是1-23。线上训练集是1-9,1-16,1-23,线上测试集就是1-30。另一个是定长窗口,线下训练集是1-16,8-23(4/5),验证集是8-23(1/5),线上训练集是1-16,8-23,线上测试集是15-30。
后来我们最终确定的窗口为变长窗口,主要有三个原因:
第一,这样我们可以预测全范围的用户,也就是注册表里所有的用户,而定长窗口不能。
第二,这样有利于线下验证集的构造,因为数据分布基本一致,保持线上线下一致,而相比定长窗口的切分窗口数据好。
第三,变长窗口构造的训练集相比较定长窗口多
二、用户分类
构造好了数据集的划分,我们再进一步对数据进行探索,因为是对用户进行是否活跃预测,那么我们研究的对象主体是用户,于是,我们就通过日志数据对用户类型进行分析。
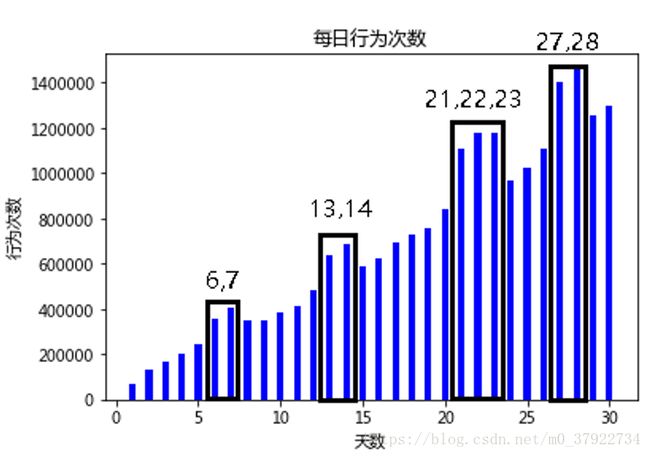
图(三)
如图三所示,我们发现每天的行为次数从第一天开始每隔五天就会有两天突增,我们猜测这两天应该是周末,说明有个用户群在周末这两天比较活跃,而在周内相对活跃次数较少。这部分用户也许是上班族等,他们得生活规律有周期性。21,22,23这三天也比较多我们猜测是节假日三天。
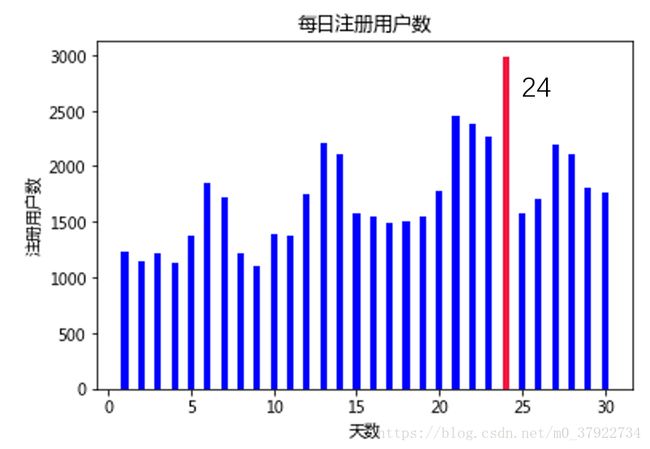
图(四)
从图四我们可以看出,每天的注册人数也是符合图一的规律,但是到了第24天,注册量出奇的高。于是我们单独拿出这一天注册日志的数据,分析发现,这些注册用户的设备类型和注册类型一模一样,于是我们就画出了如图五这样的图。

图(五)
横轴是注册类型和设备类型组合,纵轴是注册用户数量,发现确实有几种组合类型的注册数量很高,我们把这类用户定义为异常用户,这类用户有以下两个个特点:
(1)注册类型和设备类型一样,并且是一天之内注册数量相对正常注册量出奇的高(设定阈值γ,只要这种异常用户注册量大于γ就符合)。
(2)这些用户在随后的天数之内都没有活跃,只在当天活跃
我们推测这类用户是因为快手的某种活动引流进来的用户,并且这类用户是那种类似于黄牛的机器用户,最终我们根据这种规则找出了每天的异常用户。掌握了这些用户群的特点之后,这样更有利于我们进一步的特征构造与模型构建。
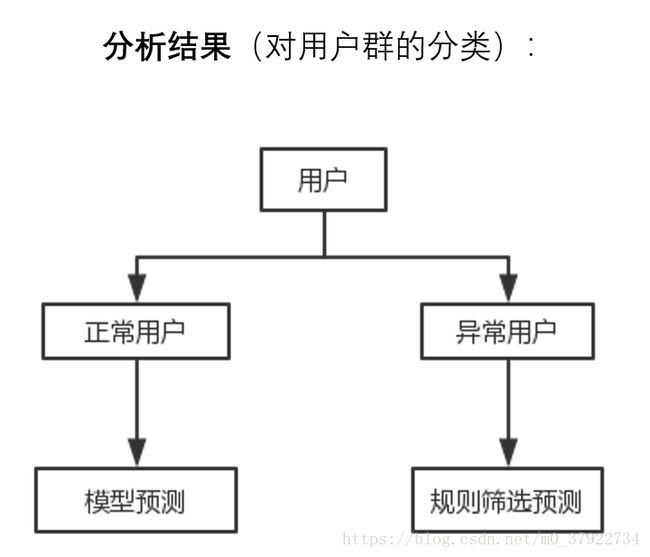
图(六)
于是根据上面数据的进一步探索,我们把用户分为两大类,如图六所示,第一类是正常用户,我们可以用模型去预测活跃的概率。第二类是异常用户,我们可以通过规则去筛选预测,也就是符合异常规则的用户我们把预测概率置为0。
总结起来,这样对用户划分主要有两大好处,第一就是使得预测异常用户更加准确。第二就是剔除之后,减少训练集噪声,增加正常用户模型预测准确率。
- 特征构造
现在我们数据集划分确定了,用户也基本分析清楚了,就开始根据变长窗口的特点以及用户群的特性构造特征。特征构造方面我们主要从‘时间’ 和‘空间’维度的层面构造。
时间维度基本侧重的是单个日志来提取的有关的时序特征,概括性的分类如图七所示。
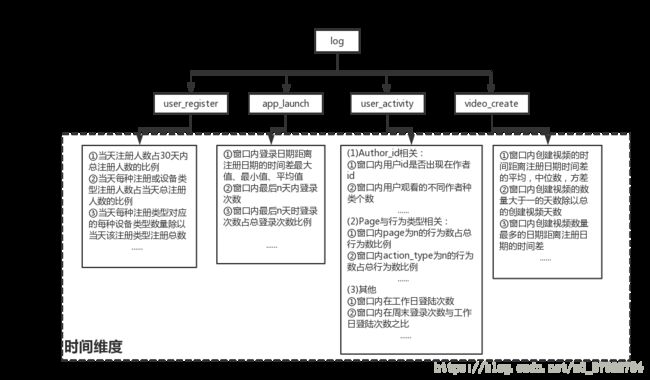
图(七)
空间维度就是题目中给的四类日志,它们从不同方面也就是不同的维度反映着用户的不同特征,比如用户的活动日志,从这方面提取的大部分特征是有关用户活动方面的特征,因此我们利用空间维度与维度之间的差异主要来构造出交叉特征。如图八所示
 图(八)
图(八)

- 模型构建
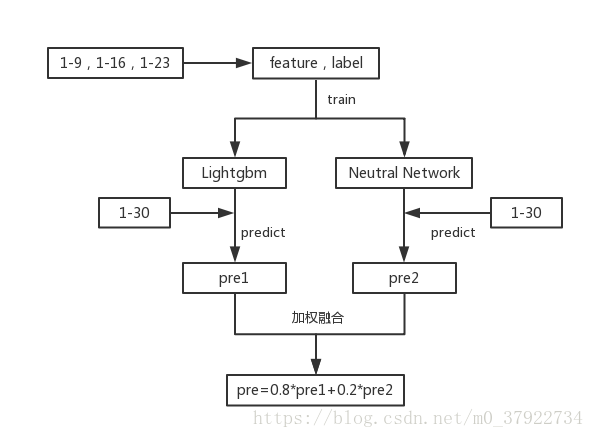
图(九)
模型方面,主要对两个单模型进行单独训练,然后对其预测结果进行加权融合。由于Lightgbm模型和神经网络模型差异性大,一个是boosting的集成思想,一个是采用神经元激活的思想的,因此我们对其两个模型预测的结果进行加权融合,提升的效果会好。
算法亮点:
TF-IDF特征的构造:
TF-IDF(term frequency–inverse document frequency)是一种用于资讯检索与资讯探勘的常用加权技术。TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。
这样我们把一个authorid比作一个字词,根据authorid在日志中出现的次数从大到小排列,取前n个作为语料库。这样与userid交互的有多个authorid,就能计算出对应的tf-idf值,我们取前m个,不够的补0,多的省去,这样就构成了m维特征。
这个特征就相当于对每一个用户在窗口内进行了编码,表征着这个用户与authorid的亲密程度,用于区分特定的用户群体。例如,一个人气高的作者一般是经常活跃的,用户与该作者交互次数越多,此用户对应该作者的tf-idf的值也越大,那么该用户活跃的概率也越大。
比赛感想:
此次比赛提供的数据为快手app真实数据的脱敏数据,更结合实际业务,使得我们更应该结合用户使用快手app的实际场景,从而对用户的特性有更深的了解以及用户群有更深更细的划分,使得特征的构造更加合理与有效。同时,在比赛过程中,竞争比较激烈,但是一定要坚持下去,不到最后一刻决不放弃,一定不能只停留在想象方面,有想法一定要及时去实现,也许那个点子就是提分的关键。