分布式系统限流策略/秒杀系统限流设计
目录
概述
限流算法
令牌桶算法
漏桶算法
应用级限流
限制总并发数/连接/请求数
限制接口的总并发/请求数
限流接口每秒的请求数
平滑限流接口的请求数
平滑突发限流(SmoothBursty)
平滑预热限流(SmoothWarmingUp)
应用接入层限流(Nginx/OpenResty)
Nginx
ngx_http_limit_conn_module
ngx_http_limit_req_module
OpenResty
lua-resty-limit-traffic
分布式应用限流
Redis+Lua的实现
概述
在开发高并发的系统时,有很多手段来保护系统,如缓存、降级、限流和熔断等。缓存可以提升系统的访问速度,降级可以暂时屏蔽掉非核心业务,使得核心业务不受影响。限流的目的通过对并发访问进行限速,一旦达到一定的速率就可以拒绝服务(定向到错误页或告知资源没有了)、排队等待(如秒杀、评论、下单等)、降级(直接返回兜底数据、如商品库存默认有货)。
常见的限流方式有:限制总并发数(数据库连接池、线程池)、限制瞬时并发数(如Nginx的limit_conn模块)、限制时间窗口的平均速率(如Guava的RateLimiter、Nginx的limit_req模块)、限制远程接口的调用速率、限制MQ的消费速率等。从应用的层面上来讲,又可以分为:接入层限流、应用层限流和分布式限流等。
限流算法
令牌桶算法
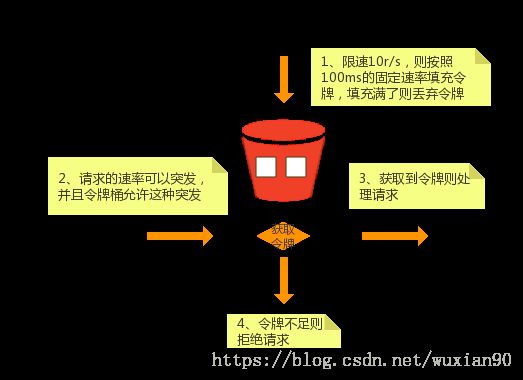
令牌桶算法是一个存放固定容量令牌的容器,按照固定速率添加令牌,算法描述如下:
假设限制2r/s,则按照500ms的固定速率添加令牌。
桶的总容量为N,当达到总容量时,新添加的令牌则被丢弃或拒绝。
当一个n个字节大小的数据包到达,则从桶中删除n个令牌,然后处理数据包。
如果桶中的令牌不足n个,则不会删除令牌,但是数据包将会被限流。
漏桶算法
漏桶可以用于流量整型和流量控制,算法描述如下:
一个固定容量的漏桶,会按照固定的速率流出水滴。
如果桶中无水,则不需要流出水滴。
可以以任意速率流入水滴。
如果流入的水滴超出了桶容量,则新添加的则会被丢弃。

综上可以看出,令牌桶允许一定程度的突发请求(有令牌就可以处理),漏桶的主要目的是来平滑流入的速率。
应用级限流
限制总并发数/连接/请求数
对于一个应用来说,总会有一个TPS/QPS的阀值,如果超过了阀值,则系统就会变得非常慢跟甚至无法响应。因此需要对系统进行过载保护,避免大量请求击垮系统。
如Tomcat的Connector中的以下几个参数:
- acceptCount:如果Tomcat的线程都忙于响应,新来的连接将会进入队列,如果超出队列大小,则会拒绝连接。
- maxConnections:瞬时最大连接数,超出的会排队等待。
- maxThreads:Tomcat能启动用来处理请求的最大线程数,如果请求处理量一直远远大于线程数,则会引起响应变慢甚至会僵死。
类似于Tomcat配置最大连接数等参数,Redis和MySQL也有相关的配置。
限制接口的总并发/请求数
在Java中可以用线程安全的AtomicLong或者Semaphore进行处理,如下使用了AtomicLong进行简单的统计:
try {
if (atomic.incrementAndSet() > 阀值) {
// 拒绝请求
}
// 处理请求
} finally {
atomic.decrementAndGet();
}这种方式实现起来比较简单暴力,没有平滑处理,这需要根据实际情况选择使用。
限流接口每秒的请求数
限制每秒的请求数,可以使用Guava的Cache来存储计数器,设置过期时间为2S(保证能记录1S内的计数)。下面代码使用当前时间戳的秒数作为key进行统计,这种限流的方式也比较简单。
LoadingCache counter =
CacheBuilder.newBuilder()
.expireAfterWrite(2, TimeUnit.SECONDS)
.build(new CacheLoader() {
@Override
public AtomicLong load(Long seconds) throws Exception {
return new AtomicLong(0);
}
});
long limit = 1000;
while (true) {
//得到当前秒
long currentSeconds = System.currentTimeMillis() / 1000;
if (counter.get(currentSeconds).incrementAndGet() > limit) {
System.out.println("限流了:" + currentSeconds);
continue;
}
//业务处理
} 上面介绍的2中限流方案都是对于单机接口的限流,当系统进行多机部署时,就无法实现整体对外功能的限流了。当然这也看具体的应用场景,如果平行的应用服务器需要共享限流阀值指标,可以使用Redis作为共享的计数器。
平滑限流接口的请求数
Guava的RateLimiter提供的令牌桶算法可以用于平滑突发限流(SmoothBursty)和平滑预热限流(SmoothWarmingUp)实现。
平滑突发限流(SmoothBursty)
平滑突发限流顾名思义,就是允许突发的流量进入,后面再慢慢的平稳限流。下面给出几个Demo
# 创建了容量为5的桶,并且每秒新增5个令牌,即每200ms新增一个令牌
RateLimiter limiter = RateLimiter.create(5);
while (true) {
// 获取令牌(可以指定一次获取的个数),获取后可以执行后续的业务逻辑
System.out.println(limiter.acquire());
}上面代码执行结果如下所示:
0.0
0.188216
0.191938
0.199089
0.19724
0.19997上面while循环中执行的limiter.acquire(),当没有令牌时,此方法会阻塞。实际应用当中应当使用tryAcquire()方法,如果获取不到就直接执行拒绝服务。
下面在介绍一下中途休眠的场景:
RateLimiter limiter = RateLimiter.create(2);
System.out.println(limiter.acquire());
Thread.sleep(1500L);
while (true) {
System.out.println(limiter.acquire());
}上面代码执行结果如下:
0.0
0.0
0.0
0.0
0.499794
0.492334从上面结果可以看出,当线程休眠时,会囤积令牌,以给后续的acquire()使用。但是上面的代码只能囤积1S的令牌(也就是2个),当睡眠时间超过1S时,执行结果还是相同的。
平滑预热限流(SmoothWarmingUp)
平滑突发限流有可能瞬间带来了很大的流量,如果系统扛不住的话,很容易造成系统挂掉。这时候,平滑预热限流便可以解决这个问题。创建方式:
// permitsPerSecond表示每秒钟新增的令牌数,warmupPeriod表示从冷启动速率过渡到平均速率所需要的时间间隔
RateLimiter.create(double permitsPerSecond, long warmupPeriod, TimeUnit unit)RateLimiter limiter = RateLimiter.create(5, 1000, TimeUnit.MILLISECONDS);
for (int i = 1; i < 5; i++) {
System.out.println(limiter.acquire());
}
Thread.sleep(1000L);
for (int i = 1; i < 50; i++) {
System.out.println(limiter.acquire());
}执行结果如下:
0.0
0.513566
0.353789
0.215167
0.0
0.519854
0.359071
0.219118
0.197874
0.197322
0.197083
0.196838上面结果可以看出来,平滑预热限流的耗时是慢慢趋近平均值的。
应用接入层限流(Nginx/OpenResty)
接入层通常是指流量的入口,主要的目的有:负载均衡、非法请求过滤、请求聚合、缓存、降级、限流、A/B测试、服务质量监控等。对于流量接入层所使用的中间件一般都是:Nginx(OpenResty)。下面将分别介绍一下如何进行限流操作。
Nginx
Nginx限流可以使用其自带的2个模块:连接数限流模块(ngx_http_limit_conn_module)和漏桶算法实现的请求限流模块(ngx_http_limit_req_module)。
ngx_http_limit_conn_module
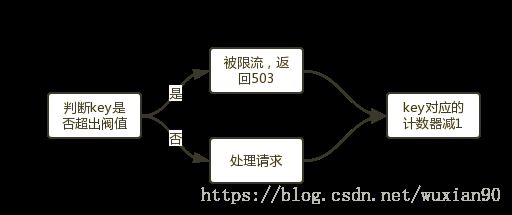
limit_conn是用来对某个key对应的总的网络连接数进行限流,可以按照IP、host维度进行限流。不是每个请求都会被计数器统计,只有被Nginx处理并且已经读取了整个请求头的连接才会被计数。下面给出一个Demo(按照IP限流):
http {
limit_conn_zone $binary_remote_addr zone=addr:10m; # 用来配置限流key及存放key对应信息的内存区域大小。此处的key是“$binary_remote_addr”,表示IP地址。也可以使用$server_name作为key
limit_conn_log_level error; # 被限流后的日志级别
limit_conn_status 503; # 被限流后返回的状态码
...
server {
...
location /limit {
limit_conn addr 1; # 要配置存放key和计数器的共享内存区域和指定key的最大连接数。此处表示Nginx最多同时并发处理1个连接
}
...
}
也可以按照host进行限流,Demo如下:
http {
limit_conn_zone $server_name zone zone=hostname:10m;
limit_conn_log_level error; # 被限流后的日志级别
limit_conn_status 503; # 被限流后返回的状态码
...
server {
...
location /limit {
limit_conn hostname 1;
}
...
}流程如下所示:
ngx_http_limit_req_module
limit_req是漏桶算法,对于指定key对应的请求进行限流。配置Demo如下:
http {
limit_req_zone $binary_remote_addr zone=one:10m rate=1r/s; # 配置限流key、存放key对应信息的共享内存区域大小、固定请求速率。此处的key是“$binary_remote_addr”(IP地址)。固定请求速率使用rate配置,支持10r/s和60r/m。
limit_conn_log_level error;
limit_conn_status 503;
...
server {
...
location /limit {
limit_req zone=one burst=5 nodelay; # 配置限流区域、桶容量(突发容量,默认为0)、是否延迟模式(默认延迟)
}
...
}
}
limit_req的主要执行过程如下:
- 请求进入后首先判断上一次请求时间相对于当前时间是否需要限流,如果需要则执行步骤2,否则执行步骤3.
- 如果没有配置桶容量(burst=0),按照固定速率处理请求。如果请求被限流了,直接返回503; 如果配置了桶容量(burst>0),及延迟模式(没有配置nodelay)。如果桶满了,则新进入的请求被限流。如果没有满,则会以固定速率被处理; 如果配置了桶容量(burst>0),及非延迟模式(配置了nodelay)。则不会按照固定速率处理请求,而是允许突发处理请求。如果桶满了,直接返回503.
- 如果没有被限流,则正常处理请求。
- Nginx会在响应时间选择一些(3个节点)限流key进行过期处理,进行内存回收。
OpenResty
Openresty提供了Lua限流模块lua-resty-limit-traffic,通过它可以按照更为复杂的业务逻辑进行动态限流处理。它也提供了limit.conn和limit.req的实现,算法与Nginx的limit_conn和limit_req是一样的。其下载地址为:lua-resty-limit-traffic,下载后,将其limit文件夹中的内容覆盖掉OpenResty安装目录中的resty中的limit文件夹即可。
lua-resty-limit-traffic
OpenResty中的限速,可以分为以下三种:limit_rate(限制响应速度)、limit_conn(限制连接数)、limit_req(限制请求数)。下面将分别介绍一下它们的用法。
limit_rate(限制响应速度)
Nginx有个$limit_rate,这个变量反映的是当前请求每秒能响应的字节数。该字节数默认为配置文件中 limit_rate指令的设值。 通过 OpenResty,我们可以直接在 Lua 代码中动态设置它。
access_by_lua_block {
-- 设定当前请求的响应上限是 每秒 300K 字节
ngx.var.limit_rate = "300K"
}limit_conn(限制连接数)
对于限制连接数,连接数限制并不是1S内的连接数限制,而是同一时刻的连接数限制。下面给出一个Demo:
nginx.conf
# nginx.conf
lua_code_cache on;
# 注意 limit_conn_store 的大小需要足够放置限流所需的键值。
# 每个 $binary_remote_addr 大小不会超过 16K,算上 lua_shared_dict 的节点大小,总共不到 64 字节。
# 100M 可以放 1.6M 个键值对
lua_shared_dict limit_conn_store 100M;
server {
listen 8080;
location /limit {
access_by_lua_file src/access.lua;
content_by_lua_file src/content.lua;
log_by_lua_file src/log.lua;
}
}然后封装一个队req.conn的工具:limit_conn.lua
-- utils/limit_conn.lua
local limit_conn = require "resty.limit.conn"
-- new 的第四个参数用于估算每个请求会维持多长时间,以便于应用漏桶算法
local limit, limit_err = limit_conn.new("limit_conn_store", 2, 2, 0.01)
if not limit then
error("failed to instantiate a resty.limit.conn object: ", limit_err)
end
local _M = {}
function _M.incoming()
local key = ngx.var.binary_remote_addr
local delay, err = limit:incoming(key, true)
if not delay then
if err == "rejected" then
return ngx.exit(503)
end
ngx.log(ngx.ERR, "failed to limit req: ", err)
return ngx.exit(500)
end
if limit:is_committed() then
local ctx = ngx.ctx
ctx.limit_conn_key = key
ctx.limit_conn_delay = delay
end
if delay >= 0.001 then
ngx.log(ngx.WARN, "delaying conn, excess ", delay,
"s per binary_remote_addr by limit_conn_store")
ngx.sleep(delay)
end
end
function _M.leaving()
local ctx = ngx.ctx
local key = ctx.limit_conn_key
if key then
local latency = tonumber(ngx.var.request_time) - ctx.limit_conn_delay
local conn, err = limit:leaving(key, latency)
if not conn then
ngx.log(ngx.ERR,
"failed to record the connection leaving ",
"request: ", err)
end
end
end
return _M然后是接收到请求时的处理代码:access.lua
-- src/access.lua
local limit_conn = require "utils.limit_conn"
-- 对于内部重定向或子请求,不进行限制。因为这些并不是真正对外的请求。
if ngx.req.is_internal() then
return
end
limit_conn.incoming()对于内容生成:content.lua,这里我们就简单的处理一下:
-- src/content.lua
ngx.say('content has generated!')
ngx.sleep(0.01) # 这里模拟一个0.01S的耗时,否则看不出效果然后是内容生成后的后置代码:log.lua
-- src/log.lua
local limit_conn = require "utils.limit_conn"
limit_conn.leaving()在MAC系统下使用webbench对接口进行测试,过程如下:
webbench -c 10 -t 10 http://localhost/limit
- 这里面-c表示10个并发,执行10S的压力测试。笔者从实验结果看来:
- 当设置limit_conn.new(“limit_conn_store”, 2, 2, 0.05)这个条件时,从第1S开始,200的响应结果为34个;后面的每一秒200的响应结果都维持在60个左右。
- 当设置limit_conn.new(“limit_conn_store”, 2, 2, 0.01)这个条件时,从第1S开始,200的响应结果为44个;后面的每一秒200的响应结果都维持在160个左右。
- 当设置limit_conn.new(“limit_conn_store”, 2, 2, 0.05)这个条件时,从第1S开始,200的响应结果为82个;后面的每一秒200的响应结果都维持在224个左右。
- 当设置limit_conn.new(“limit_conn_store”, 2, 2, 0.001)这个条件时,从第1S开始,200的响应结果为131个;后面的每一秒200的响应结果都维持在223个左右。
- 当设置limit_conn.new(“limit_conn_store”, 2, 2, 0.0001)这个条件时,从第1S开始,200的响应结果为171个;后面的每一秒200的响应结果都维持在300个左右。
从上面的结果看来,对于每个请求的执行时间预估越接近实际值或者时间略小于实际的平均值,最后榨取机器的剩余价值会越多。
limit_req(限制请求数)
对于限制请求数,下面给出一个Demo:
lua_shared_dict my_limit_req_store 100m;
location /limit {
access_by_lua_file src/utils/limit_req.lua;
content_by_lua_file src/content.lua;
}limit_req.lua的内容如下:
local limit_req = require "resty.limit.req"
-- 将请求限制在20请求/秒,突发10次/秒,
-- 也就是说,我们推迟了每秒30以下和20以上的请求,并拒绝超过30请求/秒的任何请求。
local lim, err = limit_req.new("my_limit_req_store", 20, 10)
if not lim then
ngx.log(ngx.ERR, "failed to instantiate a resty.limit.req object: ", err)
return ngx.exit(500)
end
local key = ngx.var.binary_remote_addr
local delay, err = lim:incoming(key, true)
if not delay then
if err == "rejected" then
return ngx.exit(503)
end
ngx.log(ngx.ERR, "failed to limit req: ", err)
return ngx.exit(500)
end
if delay >= 0.001 then
local excess = err
ngx.sleep(delay)
end使用如下命令进行测试:
webbench -c 50 -t 5 http://localhost/limit结果是每秒的200的结果为20个。
limit_traffic
limit_traffic可以聚合上面多种请求限流策略,这里不再说明。后续会在OpenResty的专题单独说明。
分布式应用限流
分布式应用限流指的是,在应用服务器上面进行限流操作,如Tomcat等。分布式限流最关键的是要将限流服务做成原子化,而解决方案可以使使用redis+lua进行实现,在Java开发语言中,Jedis可以支持原子性的Lua脚本。下面介绍一下Redis+Lua的实现。
Redis+Lua的实现
Lua脚本
local key = KEYS[1] --限流KEY(一秒一个)
local limit = tonumber(ARGV[1]) --限流大小
local current = tonumber(redis.call('get', key) or "0")
if current + 1 > limit then --如果超出限流大小
return 0
else --请求数+1,并设置2秒过期
redis.call("INCRBY", key,"1")
redis.call("expire", key,"2")
return 1
end
Java调用代码如下:
public static boolean acquire() throws Exception {
String luaScript = Files.toString(new File("limit.lua"), Charset.defaultCharset());
Jedis jedis = new Jedis("192.168.147.52", 6379);
String key = "ip:" + System.currentTimeMillis()/ 1000; //此处将当前时间戳取秒数
Stringlimit = "3"; //限流大小
return (Long)jedis.eval(luaScript,Lists.newArrayList(key), Lists.newArrayList(limit)) == 1;
}因为Redis的限制(Lua中有写操作不能使用带随机性质的读操作,如TIME)不能在Redis Lua中使用TIME获取时间戳,因此只好从应用获取然后传入,在某些极端情况下(机器时钟不准的情况下),限流会存在一些小问题。