scrapy可视化管理工具spiderkeeper使用笔记
spiderkeeper是一款开源的spider管理工具,可以方便的进行爬虫的启动,暂停,定时,同时可以查看分布式情况下所有爬虫日志,查看爬虫执行情况等功能。
#安装
安装环境
ubuntu16.04
python3.5
pip3 install scrapy
pip3 install scrapyd
pip3 install scrapyd-client
pip3 install scrapy-redis
pip3 install SpiderKeeper
部署爬虫
##1 进入到写好的scrapy项目路径中,启动scrapyd
python@ubuntu:~$ scrapyd
启动之后就可以打开本地运行的scrapyd,浏览器中访问本地6800端口可以查看scrapyd的监控界面

启动成功显示如下:
:0: UserWarning: You do not have a working installation of the service_identity module: 'cannot import name 'opentype''. Please install it from and make sure all of its dependencies are satisfied. Without the service_identity module, Twisted can perform only rudimentary TLS client hostname verification. Many valid certificate/hostname mappings may be rejected.
2018-08-18T18:55:20+0800 [-] Loading /usr/local/lib/python3.5/dist-packages/scrapyd/txapp.py...
2018-08-18T18:55:20+0800 [-] Scrapyd web console available at http://127.0.0.1:6800/
2018-08-18T18:55:20+0800 [-] Loaded.
2018-08-18T18:55:20+0800 [twisted.scripts._twistd_unix.UnixAppLogger#info] twistd 18.7.0 (/usr/bin/python3 3.5.2) starting up.
2018-08-18T18:55:20+0800 [twisted.scripts._twistd_unix.UnixAppLogger#info] reactor class: twisted.internet.epollreactor.EPollReactor.
2018-08-18T18:55:20+0800 [-] Site starting on 6800
2018-08-18T18:55:20+0800 [twisted.web.server.Site#info] Starting factory
2018-08-18T18:55:20+0800 [Launcher] Scrapyd 1.2.0 started: max_proc=8, runner='scrapyd.runner'
2018-08-18T18:55:21+0800 [twisted.python.log#info] "127.0.0.1" - - [18/Aug/2018:10:55:20 +0000] "GET /listjobs.json?project=dangdang HTTP/1.1" 200 86 "-" "python-requests/2.13.0"
2018-08-18T18:55:28+0800 [twisted.python.log#info] "127.0.0.1" - - [18/Aug/2018:10:55:25 +0000] "GET /listspiders.json?project=dangdang HTTP/1.1" 200 71 "-" "python-requests/2.13.0"
2018-08-18T18:55:28+0800 [twisted.python.log#info] "127.0.0.1" - - [18/Aug/2018:10:55:28 +0000] "GET /listjobs.json?project=dangdang HTTP/1.1" 200 86 "-" "python-requests/2.13.0"
·····
2 启动SpiderKeeper
注意:如果是window启动需要输入账号密码,均为admin
python@ubuntu:~$ spiderkeeper
成功启动显示如下:
/usr/local/lib/python3.5/dist-packages/flask_restful_swagger/swagger.py:14: ExtDeprecationWarning: Importing flask.ext.restful is deprecated, use flask_restful instead.
from flask.ext.restful import Resource, fields
--------------------------------------------------------------------------------
INFO in run [/usr/local/lib/python3.5/dist-packages/SpiderKeeper/run.py:22]:
SpiderKeeper startd on 0.0.0.0:5000 username:admin/password:admin with scrapyd servers:http://localhost:6800
--------------------------------------------------------------------------------
2018-08-18 18:57:14,205 - SpiderKeeper.app - INFO - SpiderKeeper startd on 0.0.0.0:5000 username:admin/password:admin with scrapyd servers:http://localhost:6800
访问localhost:5000可以看到如下界面
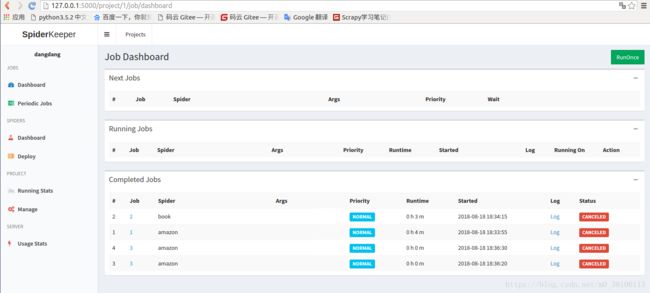
3 打包项目,部署到scrapyd上
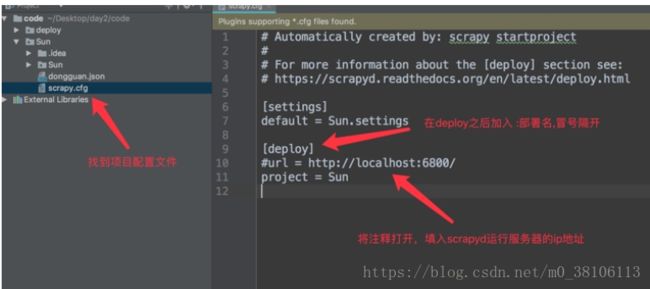
3.1 配置需要部署的项目
编辑需要部署的项目的scrapy.cfg文件(需要将哪一个爬虫部署到scrapyd中,就配置该项目的该文件)
[deploy:部署名(部署名可以自行定义)]
url = http://127.0.0.1:6800/
project = 项目名(创建爬虫项目时使用的名称)
3.2 部署项目到scrapyd
同样在scrapy项目路径下执行
scrapyd-deploy 部署名 -p 项目名称
例如:
python@ubuntu:~/Desktop/dangdang$ scrapyd-deploy book -p dangdang
Packing version 1534588377
Deploying to project "dangdang" in http://127.0.0.1:6800/addversion.json
Server response (200):
{"node_name": "ubuntu", "project": "dangdang", "version": "1534588377", "status": "ok", "spiders": 2}
4 部署项目到spiderkeeper上
首先在项目路径中“生蛋”
scrapyd-deploy --build-egg output.egg
然后打开spiderkeeper的页面,点击deploy,点击create project创建新项目book

点击选择文件,上传之前创建的.egg文件

之后,部署就完成了!
5 spiderkeeper 的使用
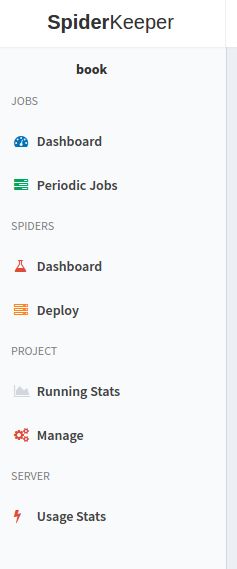
spiderkeeper的功能都罗列在左边的菜单栏中,如上
Dashboard
主界面,可以查看所有爬虫(暂停的,未启动的,运行中的)的情况,如果要运行爬虫可以点击该页面右上角的runonce
显示如下:
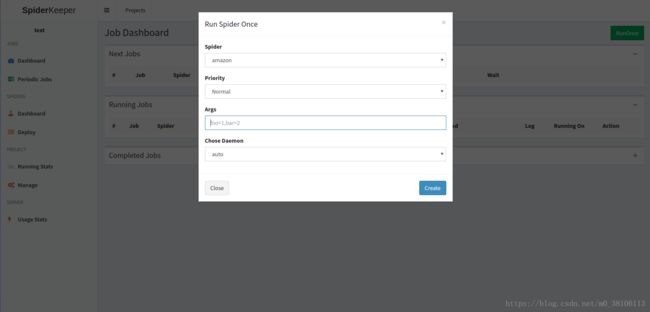
可以选择要执行的爬虫,设置ip池(没有实际用过,都是用自己写的代理池),选择在哪个服务器运行
创建之后会显示在运行栏

可以点击log查看日志,也可以直接停止
Periodic Jobs
定时任务,点击右上角的addjobs后可以添加任务,除了之前有的选项之后还可以设置每个月/每星期/每天/每小时/每分钟 的定时爬虫

Running Stats
查看爬虫的运行情况

只能显示时间段爬虫的存活情况
Manage
如果要删除任务可以在这里删除
6 总结
这算是一款不错的开源爬虫可视化软件,对于爬虫的管理算是做到了美观而且简单。但是对于爬虫的爬取情况需要通过日志查看,也就是想要知道详细情况还需要自己写好日志的记录。