RNN学习笔记
1. RNN概述
CNN网络被用于处理图像数据,而对于非连续的数据处理一般是采用RNN网络进行实现的。对于经典的RNN网络其基本结构组成如下图所示
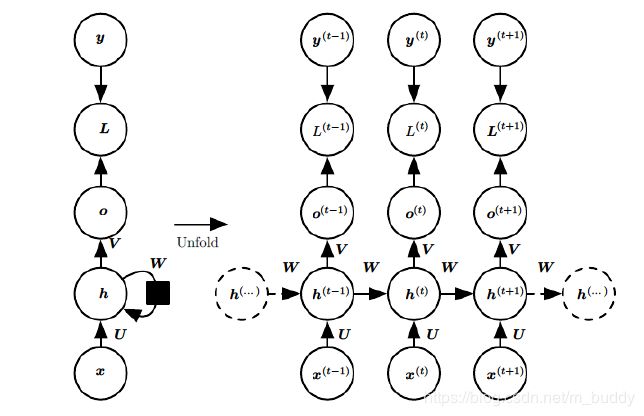
上图中左边是RNN模型没有按时间展开的图,如果按时间序列展开,则是上图中的右边部分。我们重点观察右边部分的图。这幅图描述了在序列索引号 t t t附近RNN的模型。其中:
- x ( t ) x^{(t)} x(t)代表在序列索引号 t t t时训练样本的输入。同样的, x ( t − 1 ) x^{(t−1)} x(t−1)和 x ( t + 1 ) x^{(t+1)} x(t+1)代表在序列索引号 x ( t − 1 ) x^{(t−1)} x(t−1)和 x ( t + 1 ) x^{(t+1)} x(t+1)时训练样本的输入。
- h ( t ) h^{(t)} h(t)代表在序列索引号 t t t时模型的隐藏状态。 h ( t ) h^{(t)} h(t)由 x ( t ) x^{(t)} x(t)和 h ( t − 1 ) h^{(t-1)} h(t−1)共同决定。
3) o ( t ) o^{(t)} o(t)代表在序列索引号 t t t时模型的输出。 o ( t ) o^{(t)} o(t)只由模型当前的隐藏状态 h ( t ) h^{(t)} h(t)决定。 - L ( t ) L^{(t)} L(t)代表在序列索引号 t t t时模型的损失函数。
- y ( t ) y^{(t)} y(t)代表在序列索引号 t t t时训练样本序列的真实输出。
- U , W , V U,W,V U,W,V这三个矩阵是我们的模型的线性关系参数,它在整个RNN网络中是共享的,这点和DNN很不相同。
2. RNN前向算法与后向算法
2.1 前向算法
在RNN中隐状态 h ( t ) h^{(t)} h(t)的计算可以参考如下公式表示,最后简化后的形式同一般神经元相同,输入信息乘权重加偏值:
h ( t ) = σ ( U x t + W h ( t − 1 ) + b ) h^{(t)}=\sigma (Ux^{t} + Wh^{(t-1) }+ b) h(t)=σ(Uxt+Wh(t−1)+b)
其中 σ \sigma σ为RNN的激活函数,在隐层一般为 t a n h tanh tanh,这里补充一下:这里选择隐层的激活函数为 t a n h tanh tanh,但是由于连乘关系会存在梯度消失问题,自然可以采用Relu函数,但防止梯度爆炸,需要进行剪裁操作,对于这样的问题在LSTM变形中进行了改进。 b b b为线性偏置。
在RNN中由于后序时刻对前序的输入是存在依赖关系的,但是梯度传递的时候是连乘的关系,这就导致了梯度问题,这是在知乎上找到的一个解释:
则输出 o t o^{t} ot表示为:
o ( t ) = V h ( t ) + c o^{(t)}=Vh^{(t)} + c o(t)=Vh(t)+c
之后的分类输出是在这个的基础上经过softmax(输出层)映射得到,可以表示为
y ( t ) = σ ( o ( t ) ) y^{(t)}=\sigma (o^{(t)}) y(t)=σ(o(t))
最后 L ( t ) L^{(t)} L(t)通过计算 y ( t ) ^ \hat{y^{(t)}} y(t)^与 y ( t ) y^{(t)} y(t)之间的差异来更新网络
2.2 反向传播
有了RNN前向传播算法的基础,就容易推导出RNN反向传播算法的流程了。RNN反向传播算法的思路和DNN是一样的,即通过梯度下降法一轮轮地迭代,得到合适的RNN模型参数 U , W , V , b , c U,W,V,b,c U,W,V,b,c。由于我们是基于时间反向传播,所以RNN的反向传播有时也叫做BPTT(back-propagation through time)。当然这里的BPTT和DNN也有很大的不同点,即这里所有的 U , W , V , b , c U,W,V,b,c U,W,V,b,c在序列的各个位置是共享的,反向传播时我们更新的是相同的参数。
为了简化描述,这里的损失函数我们为对数损失函数,输出的激活函数为 s o f t m a x softmax softmax函数,隐藏层的激活函数为 t a n h tanh tanh函数。对于RNN,由于我们在序列的每个位置都有损失函数,因此最终的损失L为:
L = ∑ t = 1 T L ( t ) L=\sum_{t=1}^{T}L^{(t)} L=t=1∑TL(t)
其中 V , c V,c V,c的梯度计算式比较简单的:
∂ L ∂ c = ∑ t = 1 T ∂ L ( t ) c = ∑ t = 1 T ∂ L ( t ) o ( t ) ∂ o ( t ) c = ∑ t = 1 T y t ^ − y ( t ) \frac{\partial L}{\partial c}=\sum_{t=1}^{T} \frac{\partial L^{(t)}}{c}=\sum_{t=1}^{T} \frac{\partial L^{(t)}}{o^{(t)}} \frac{\partial o^{(t)}}{c}=\sum_{t=1}^{T} \hat {y^{t}}-y^{(t)} ∂c∂L=t=1∑Tc∂L(t)=t=1∑To(t)∂L(t)c∂o(t)=t=1∑Tyt^−y(t)
∂ L ∂ V = ∑ ( t = 1 ) T ∂ L ( t ) ∂ V = ∑ t = 1 T ∂ L ( t ) ∂ o ( t ) ∂ o ( t ) ∂ V = ∑ t = 1 T ( y t ^ − y ( t ) ) ( h ( t ) ) T \frac{\partial L}{\partial V}=\sum_{(t=1)}^{T} \frac{\partial L^{(t)}}{\partial V}=\sum_{t=1}^{T} \frac{\partial L^{(t)}}{\partial o^{(t)}} \frac{\partial o^{(t)}}{\partial V}= \sum_{t=1}^{T}( \hat {y^{t}}-y^{(t)})(h^{(t)})^{T} ∂V∂L=(t=1)∑T∂V∂L(t)=t=1∑T∂o(t)∂L(t)∂V∂o(t)=t=1∑T(yt^−y(t))(h(t))T
但是 W , U , b W,U,b W,U,b的梯度计算就比较的复杂了。从RNN的模型可以看出,在反向传播时,在某一序列位置 t t t的梯度损失由当前位置的输出对应的梯度损失和序列索引位置 t + 1 t+1 t+1时的梯度损失两部分共同决定。对于 W W W在某一序列位置 t t t的梯度损失需要反向传播一步步地计算。我们定义序列索引 t t t位置的隐藏状态的梯度为:
δ ( t ) = ∂ L ∂ h ( t ) \delta^{(t)}=\frac{\partial L}{\partial h^{(t)}} δ(t)=∂h(t)∂L
这样我们可以像DNN一样从 δ ( t + 1 ) \delta^{(t+1)} δ(t+1)递推 δ ( t ) \delta^{(t)} δ(t)
δ ( t ) = ∂ L ∂ o ( t ) ∂ o ( t ) ∂ h ( t ) + ∂ L ∂ h ( t + 1 ) ∂ h ( t + 1 ) ∂ h ( t ) = V T ( y ( t ) ^ − y ( t ) ) + W T δ ( t + 1 ) d i a g ( 1 − ( h ( t + 1 ) ) 2 ) \delta^{(t)}=\frac{\partial L}{\partial o^{(t)}} \frac{\partial o^{(t)}}{\partial h^{(t)}} + \frac{\partial L}{\partial h^{(t+1)}} \frac{\partial h^{(t+1)}}{\partial h^{(t)}}=V^{T}(\hat{y^{(t)}}-y^{(t)})+W^{T}\delta^{(t+1)}diag(1-(h^{(t+1)})^2) δ(t)=∂o(t)∂L∂h(t)∂o(t)+∂h(t+1)∂L∂h(t)∂h(t+1)=VT(y(t)^−y(t))+WTδ(t+1)diag(1−(h(t+1))2)
对于 δ ( T ) \delta^{(T)} δ(T),由于它是最后一个了,因而后面的那一部分就没有了,所以
δ ( T ) = ∂ L ∂ o ( T ) ∂ o ( T ) ∂ h ( T ) = V T ( y ( t ) ^ − y ( t ) ) \delta^{(T)}=\frac{\partial L}{\partial o^{(T)}} \frac{\partial o^{(T)}}{\partial h^{(T)}}= V^{T}(\hat{y^{(t)}}-y^{(t)}) δ(T)=∂o(T)∂L∂h(T)∂o(T)=VT(y(t)^−y(t))
这样前面 T − 1 T-1 T−1时刻加上 T T T传递给的梯度,这样就可以实现梯度传递了。继而,有了 δ ( t ) \delta^{(t)} δ(t),计算 W , U , b W,U,b W,U,b就容易了,这给出它们的计算表达式:
∂ L ∂ W = ∑ t = 1 T ∂ L ∂ h ( t ) ∂ h ( t ) ∂ W = ∑ t = 1 T d i a g ( 1 − ( h ( t ) ) 2 ) δ ( t ) ( h ( t ) ) T \frac{\partial L}{\partial W}=\sum_{t=1}^{T}\frac{\partial L}{\partial h^{(t)}} \frac{\partial h^{(t)}}{\partial W} =\sum_{t=1}^{T}diag(1-(h^{(t)})^2)\delta^{(t)} (h^{(t)})^T ∂W∂L=t=1∑T∂h(t)∂L∂W∂h(t)=t=1∑Tdiag(1−(h(t))2)δ(t)(h(t))T
∂ L ∂ b = ∑ t = 1 T ∂ L ∂ h ( t ) ∂ h ( t ) ∂ b = ∑ t = 1 T d i a g ( 1 − ( h ( t ) ) 2 ) δ ( t ) \frac{\partial L}{\partial b}=\sum_{t=1}^{T}\frac{\partial L}{\partial h^{(t)}} \frac{\partial h^{(t)}}{\partial b} =\sum_{t=1}^{T}diag(1-(h^{(t)})^2)\delta^{(t)} ∂b∂L=t=1∑T∂h(t)∂L∂b∂h(t)=t=1∑Tdiag(1−(h(t))2)δ(t)
∂ L ∂ U = ∑ t = 1 T ∂ L ∂ h ( t ) ∂ h ( t ) ∂ U = ∑ t = 1 T d i a g ( 1 − ( h ( t ) ) 2 ) δ ( t ) ( x ( t ) ) T \frac{\partial L}{\partial U}=\sum_{t=1}^{T}\frac{\partial L}{\partial h^{(t)}} \frac{\partial h^{(t)}}{\partial U} =\sum_{t=1}^{T}diag(1-(h^{(t)})^2)\delta^{(t)} (x^{(t)})^T ∂U∂L=t=1∑T∂h(t)∂L∂U∂h(t)=t=1∑Tdiag(1−(h(t))2)δ(t)(x(t))T
3. RNN种类:
(1)sequence-to-sequence:输入输出都是一个序列。例如股票预测中的RNN,输入是前N天价格,输出明天的股市价格。
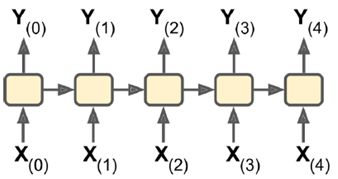
(2)sequence-to-vector:输入是一个序列,输出单一向量。例如,输入一个电影评价序列,输出一个分数表示情感趋势(喜欢还是讨厌)。
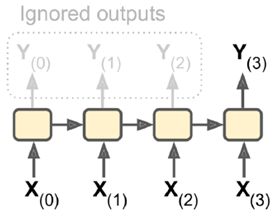
(3)vector-to-sequence:输入单一向量,输出一个序列。
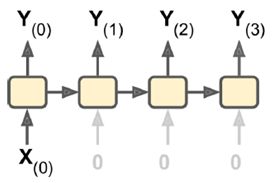
(4)Encoder-Decoder:输入sequence-to-vector,称作encoder,输出vector-to-sequence,称作decoder。
这是一个delay模型,经过一段延迟,即把所有输入都读取后,在decoder中获取输入并输出一个序列。这个模型在机器翻译中使用较广泛,源语言输在入放入encoder,浓缩在状态信息中,生成目标语言时,可以生成一个不等长度的目标语言序列。
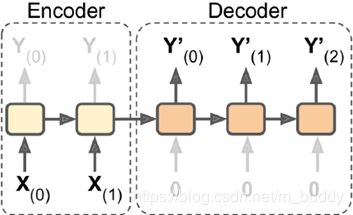
(5)Bidirectional RNNs
RNN 中对于当前时刻 t 通常会考虑之前时刻的信息而没有考虑下文的信息,Bidirectional RNNs 克服了这一缺点,其引入了对下文的考虑,其结构如下:
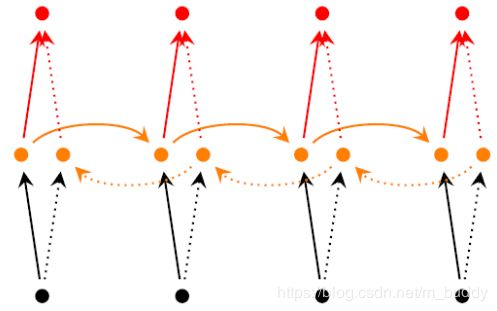
可见 BRNN 引入了一套额外的隐层,但是输入与输出层是共享的,多了一个隐层意味着多了三套参数分别为 U ′ , V ′ , W ′ U^′, V^′, W^′ U′,V′,W′ 。BRNN 的训练算法类似于 RNN ,forward pass 的过程如下:

backward pass 的过程如下:

计算完残差后,分别对前向参数 U , V , W U,V,W U,V,W 后向参数 U ′ , V ′ , W ′ U^′, V^′, W^′ U′,V′,W′ 求导即可,至此 BRNN 的训练算法介绍完毕,目前 ,BRNN 在 NLP 的序列标注任务中取得了极大的成功。
4. RNN在Caffe中的实现与调用
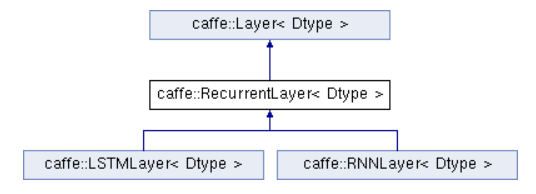
首先来看一下类的层次结构,在Caffe中为LSTM与RNN在基础类Layer的基础上抽象出一个父类RecurrentLayer,然后这两种RNN就在此基础上进行实现。
未完待续…
5. 参考REF
- 循环神经网络(RNN)模型与前向反向传播算法
- 【机器学习】RNN学习