【高性能MySQL】第六章查询性能优化 查询优化
6.4.3查询优化处理
查询的生命周期下一步:将一个SQL转换成一个执行计划,MySQL再依照这个执行计划和存储引擎进行交互:解析SQL、预处理、优化SQL执行计划
语法解析器和预处理
通过关键字将SQL语句进行解析:
解析器将使用MySQL语法规范验证解析查询,
生成解析树,预处理器据规则检查解析树是否合法
查询优化器
优化器将语法树从众多执行方式中找到best的执行计划
基于成本的优化器:预测查询使用某种执行计划时的成本,选择min的一个:通过last_query_cost得当前查询成本
show status like 'Last_query_cost'选择错误的执行计划原因:
1、统计信息不准,2、执行计划中的成本估算!=实际执行成本,3、不考虑并发,4、MySQL不是都基于成本的优化,5、mysql不考虑不受其控制的操作的成本(存储过程 自定义函数),6、有时无法估算all可能的执行计划
策略:
静态优化:
可直接对解析树进行分析、完成优化;编译时优化,第一次完成一直有效,不依赖特别的数值
动态优化:
查询上下文相关,每次查询重写评估,运行时优化
能够处理的优化类型:
重新定义关联表的顺序、将外连接转化为内连接
等价变换规则简化规范表达式,优化count min max (类似常量)
预估并转化为常数表达式、覆盖索引扫描、子查询优化、提前终止查询
等值传播、列表in的比较:先排序、二分查找![]() ,==多个OR:
,==多个OR:![]()
数据和索引的统计信息
服务器查询优化器生成查询执行计划需向存储引擎获取响应的统计信息:
每表或索引有多少个页面,表的索引基数是多少、数据行、索引长度 、分布信息
如何执行关联查询
mysql认为任何一个查询都是一次“关联”,借助临时表 关联
执行计划:
生成指令树、引擎执行完成该树返回结果
你以为是可能是这样的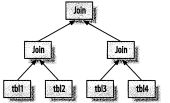 其实是嵌套循环成这样的
其实是嵌套循环成这样的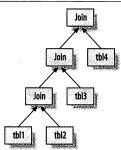
关联查询优化器:
决定表关联时的顺序,评估不同顺序时的成本选择,因为前面的嵌套所以这个还是挺重要的因素
当需要关联的表数超过optimizer_search_depth限制,会选择“贪婪”搜索模式
排序优化:
排序过程统称文件排序filesort;尽可能避免排序或尽可能避免对大量数据排序
数据量<排序缓存区:内存中快速排序;内存不够,将数据分块、每块使用快速排序 排序,将各块排序结果存放在磁盘上,合并 返回
排序算法:
- 两次传输排序(旧版)读取行指针和需要排序的字段,对其进行排序,据排序结果读取所需要的数据行;lot随机I/O ,排序时存尽可能少的数据,排序缓存区容纳尽可能多的行数进行排序
- 单次传输排序(新 4.1后)读取查询所需all列,据给定列排序,查询需all列总长<=max_length_for_sort_data,选此
排序消耗临时空间比较大:足够长的定长空间存排序记录、UTF-8 将为每字符预留三个字节
关联查询需排序:
1、order by子句all列来自关联的第一个表,在关联处理第一个表时进行文件排序,在explain的extra字段会有using filesort
2、其他,先将关联结果存临时表,all关联结束进行文件排序,explain的extra看到using temporary,using filesort,有limit,则limit再排序后应用
mysql5.6很多改进:
当只想要返部分排序结果,limit 不再对all结果排序,据实际情况,抛弃不满足条件的结果再进行排序
6.4.4查询执行引擎
逐步据执行计划(一个数据结构)完成查询,过程中需通过储存引擎实现的接口handler API
查询中每张表由一个handler实例表示(优化阶段便为表建handler实例,优化器据实例接口获取表的相关信息)
引擎接口有丰富的功能(虽底层接口十几个而已),存储引擎插件式架构成为可能的同时也有些限制,不是all的操作由handler完成
6.4.5返回结果给客户端
last阶段,返回结果,可被缓存将结果放到查询缓存中
增量、逐步返回的过程:
服务器处理完最后一个关联表,生成第一条结果时,mysql便可开始向客户端逐步返回结果集
好处:1、服务器不存太多结果、内存省了,2、客户端第一时间获得返回结果
结果集每行均一个满足mysql客户端/服务器通信协议的封包发送 通过TCP协议传输 (ing封包缓存批量传输)
该6.5了,换、诶也不知道这样学习好不好、可能无所谓好坏吧,还有别的方法吗?多想无益
小结:
使用新版是多么幸福的一件事情,同时使用旧版是多么锻炼人的一件事件,莫名好像知道了些什么
话说回来,为了节省时间也是为了提高效率,博客将缩略来写,因为水平有限,可能总结的不是太对,所以欢迎一起交流,互相提高,嗯~先这样。