【高性能MySQL】第7章MySQL高级特性 上 分区 视图
前言:
mysql从5.0和5.1开始引入很多高级特性:分区 、触发器等,这些特性表现如何、带你去发现
7.1分区表
分区表是独立逻辑表,底层由多个物理子表组成
底层文件系统看、分区表all有个#分隔命名的表文件
对底层表的封装:索引也是按分区子表定义的,无全局索引
实现分区的代码是一组底层表的句柄对象Handler Object的封装
对分区表(可直接)请求:通过句柄转成存储引擎接口调用,分区对SQL黑盒子、应用透明
创建表时使用PARTITION BY子句定义每个分区存放的数据,执行查询优化器据分区定义过滤不需要的分区
优缺点:
较粗的粒度将相关数据放一起;表数据可分布不同物理设备、高效利用设备;
表最多只能有1024个分区;5.1中分区表达式须整数or返回整数的表达式;分区字段有主键or唯一索引列,all主键列和唯一索引列都必须包含进来;无法使用外键约束;
发挥大作用的场景:
表大到无法all放到内存中,或表前面都是历史数据
7.1.1分区表原理
存储引擎管理分区的各底层表和普通表一样,分区表的索引:在各底层表上各自加一完全相同的索引
select:分区层先打开并锁住all底层表,优化器判断是否可过滤,再调对应引擎接口访问各个分区的数据
insert:分区层先打开并锁住all底层表,确定哪个分区接收该记录,再将记录写入对应底层表
delete:打开锁住all底层表,确定分区、底层表删除
update:打开锁住all底层表,确定分区,取出数据更新,应放在哪个分区,最后对底层表写入,原数据底层表删除
引擎能自己实现行级锁,如InnoDB则会在分区层释放对应表锁,加锁解锁与普通innodb查询类似
7.1.2、3分区表类型 使用
范围、键值、哈希、列表分区、5.5中可使用range columns类型的分区
数据量超大,b-tree索引无法起作用,除非索引覆盖查询
7.1.4什么情况下回出现问题 5.5版分割线
1、null值或无效值使分区过滤无效:
first分区特殊分区:非法值对应数据放入,查询时mysql检查两个分区
优化:so创建一个无用的第一分区,5.5中不需要优化
2、分区列和索引列不匹配:无法进行分区过滤
3、选择分区的成本很高:类型多 实现方式不同 性能不同
范围分区:写入时扫描分区列表找到合适目前分区,可通过限制分区数据缓解,键哈希分区无此问题
4、打开并锁住all底层表的成本可能很高:发生在过滤前,和类型无关,影响all查询
5、维护分区成本可能很高:一些操作重组分区 或类似alter操作:需要复制数据 建临时分区 复制其中 删除原区
限制:
1、all分区必须使用相同引擎;2、分区函数中可使用的函数和表达式也有一些限制
3、某些引擎不支持分区;4、对应myisam分区表,不能使用load index into cache
5、myisam表,分区表需打开more文件描述符:看似一表其实lot独立分区,每个分区对引擎都是独立表
即时配置合适表缓存,还会出现超过文件描述符限制的问题
注意版本,新版本改进了很多
7.1.5查询优化 303
访问分区表:在where条件中带入分区、可让优化器过滤掉无须访问的分区
MySQL只能在使用分区函数的列比较过滤分区,运行时分区过滤
原则:即便在创建分区时可使用表达式,但在查询时却只能据列来过滤分区
7.1.6合并表
早期、简单分区实现,容许用户单独访问各个子表,一门待淘汰的技术
相当于容器,包含了多个真实表,可在create table中使用特别union语法指定包含哪些真实的表
前提条件:字段要和被合并的各个真实表字段相同;表中的索引各个真实字表也有
子表虽有主键限制,但是合并表仍可能有重复值;每个子表行为和表定义相同(同一个表嘛)但合并表全局不受条件影响;删合并表子表不受影响,子表删除但文件描述打开、该表还存在,只能通过合并表访问到
 insert_method=last 所有的insert语句发给最后一个表;first
insert_method=last 所有的insert语句发给最后一个表;first
注意:
1、创建不检查各子表的兼容性,子表定义不同,可能建出无法使用的合并表;创建后修改子表使用合并表会报错
2、无法使用replace、自增字段
3、访问合并表,访问all子表,限制合并表中子表数很重要(当合并表是某个关联查询的一部分表时:访问一个表的记录数可能会将比较传递到关联的其他表中)
执行范围查找,每子表各执行一次,比直接访问单表性能差,子表越多、性能越糟
全表扫描和普通表的全表扫描速度同
合并表上做唯一键、主键查询,找到即停止
子表读取顺序和create table顺序同
合并表子表可直接被访问,具有mysql5.5分区不能提供的特性
1、myisam表可以是多个合并表的子表;2、可通过复制.frm MYI MYD文件,实现服务器间复制子表
3、合并表中添加新子表容易,直接修改合并表定义即可;4、可创建只包含需要数据的合并表;
5、想对子表备份 恢复 修改 修复 等 可先将其从合并表删除,结束后再加;6、可用myisampack压缩子表
7.2视图
5.0后引入,本身虚拟表、不放数据,返回的是其他表生成的,视图和表同一命名空间中
很多地方MySQL对视图和表同样对待,但也有不同,不能对视图创触发器、不是drop table删除视图
实现视图的两种实现算法:本身属性
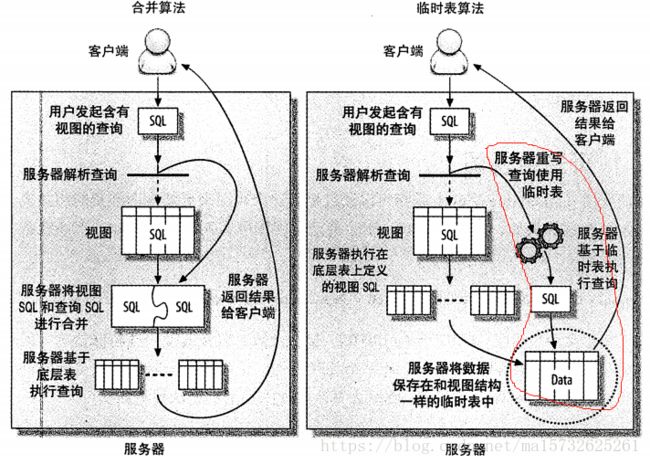
如果视图中包含group by、distinct、任何聚合函数、union、子查询等的时候无法在原表记录和视图记录建立一一映射,将使用临时表算法实现视图;
explain 一条对视图的查询查看使用了什么算法:select_type为derived临时表
create algorithm = temptable view v1 as select * from actor:基于该视图任何查询视图all生成一个临时表
7.2.1可更新视图 updatable view
1、通过更新视图来更新视图涉及的表,指定了合适的条件、可更新 删除 写入数据
2、如果视图定义中包含group by union 聚合函数及其他特殊情况,不能被更新
3、更新查询可是个关联语句,被更的列须来自同一个表
4、all临时表算法 无法被更新
5、定义视图时可使用check option子句:任何通过视图更新的行,须符合视图本身where定义:不能更新视图定义列以外的列:![]() 不能更 continent列,插不同continent值的新数据
不能更 continent列,插不同continent值的新数据
7.2.2视图对性能的影响
无须在系统中建权限,借助视图实现基于列的权限控制
临时表算法实现的视图,有时性能会很糟,递归执行这类视图,先外后内,无法做more内外结合的优化
7.2.3视图的限制
不支持物化视图(将视图结果放在一个可查看的表中,定期从原表刷新数据到这个表)
不支持索引:可构建缓存表或汇总表模拟物化视图和索引
修改视图:
并不会保存视图定义的原始SQL语句,可通过.frm文件最后一行取得一些信息,如有file权限,可用LOAD_FILE()语句读取创建信息,再加一些字符处理工作,可获得完整创建语句

substring_index(被截取字段,关键字,关键字出现的次数)【源】【源】
如果count是正数,那么就是从左往右数,第N个分隔符的左边的全部内容
相反,如果是负数,那么就是从右边开始数,第N个分隔符右边的所有内容
小结:
分区技术等待淘汰,但是思想、作用还有可取之处
视图这个比较常用,相对而言这篇博客偏于理论,实践性知识还需要在学习、总结