Read + Verify: Machine Reading Comprehension with Unanswerable Questions 论文阅读笔记
原文链接:http://cn.arxiv.org/pdf/1808.05759
Read + Verify: Machine Reading Comprehension with Unanswerable Questions
本篇文章创新点:
- 1 提出了reader - vertify 结构,首先生成一个答案,再验证答案的合理性
- 2 提出了三种模型
- 3 提出了两个独立的loss函数作为辅助
摘要部分
没有答案的情况也是机器阅读理解的任务之一,目的是在无法推断答案的情况下不进行回答。之前的工作主要集中在预测没有答案的概率来判断是否有答案,然后他们并没有通过考虑判断答案的合理性性来判断答案是否存在,因此作者提出一种read-then-vertify的模型,它不仅能够利用神经网络从候选答案中进行抽取,并且产生无答案概率,而且利用一个答案验证器来决定预测的答案是否来源于输入的片段。此外,引入两个新的loss函数来辅助reader模型能够更好的解决答案抽取过程中没有答案的情况。然后再SQuAD数据集上取得了优异的结果。
一 、简介部分
首先感谢前人的工作。然而,当前所研究方法基于一个重要的假设就是在文章的范围内必定存在一个正确的答案。因此,模型只需要根据问题选择一个最合理的文章范围,而不需要检查答案是否存在。最近SQuAD 2.0提出测试问题答案并且解决没有答案的情况,为了处理无法回答的问题,系统必须学会识别大量的语言现象,如否定、反义词和问题之间的实体变化。
之后就是related work,存在的问题就是前人的工作没有验证所生成的答案是否合理,为了解决上述问题,本文提出了一种新的“read-then-vertify”系统。如图1所示,我们的系统由两个部分组成:
- (1)一个用于提取候选答案和检测无法回答问题的无答案阅读器;
- (2)一个用于决定提取的候选答案是否合法的答案验证器
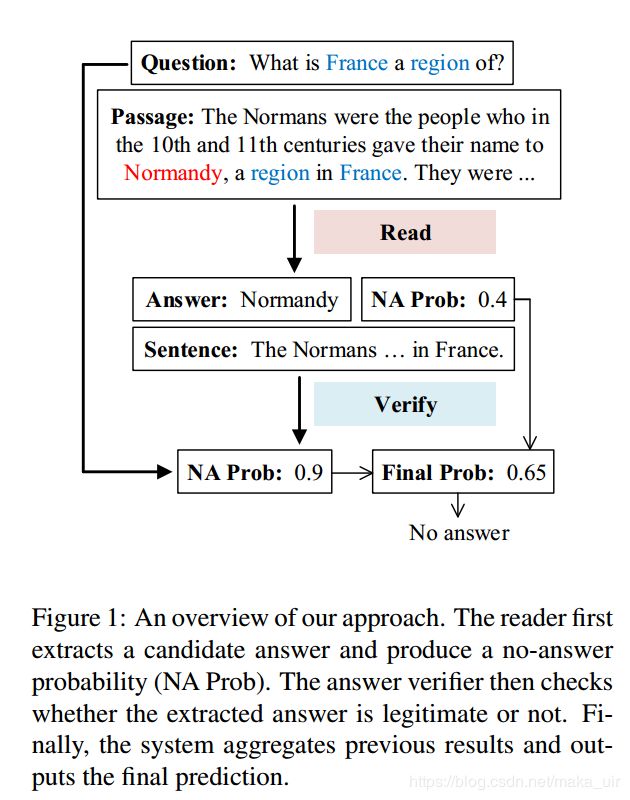
主要工作主要集中在以下三个方面:
首先,我们在现有的阅读器上增加了两个辅助的loss函数,这两个函数能够使模型更好的抽取答案,并且也能够检测没有答案的情况。由于在后续的验证阶段总是需要一个答案,因此对于不能回答的答案reader模型也要抽取一个答案。然而,以前的方法并没有解决答案不存在时候的情况。作者通过引入一个独立的损失函数来解决这个问题,该损失函数目的在于问题答案的提取,而不考虑答案的存在清理。为了不与无答案检测过程相冲突,利用一个多头网络生成两个得分,其中一个得分是对没有答案概率进行标准化,另一对用于辅助损失函数。此外,我们还提出了另一种没有答案时候的损失函数,以进一步减轻冲突,方法是将重点放在无答案检测任务上,而不考虑答案抽取任务。
其次,除了一般的阅读理解过程,作者还引入了一个额外的答案验证环节,旨在通过比较回答句和问题,找到支持答案的佐证。这是基于一种常识性的认识,无法回答的问题通常出现在一些段落词和问题词之间。以图1为例,在将文章片段“诺曼底,法国的一个地区”与问题进行比较后,我们可以很容易地确定没有答案存在,因为问题要求一个不可能的条件。我们研究了三种用于回答验证模型的体系结构。第一个是序列模型,它把两个句子作为一个长序列,而第二种方法则是在两个句子之间进行交互推理。最后是一个混合模型,它结合了上述两个模型的优点并进一步提高。
最后,我们在SQuAD 2.0(Rajpurkar et al., 2018)上评估了我们的系统,这是一个增加了无法回答问题的阅读理解基准。我们最好的reader model在开发集上的F1得分为73.7和69.1,无论有没有使用ELMo embeddings (Peters et al., 2018)。结合答案验证器,整个系统分别提高到74.8 F1和72.3 F1。此外,最好的系统在测试集上的得分为74.2 F1,在提交时超过了之前的所有方法。
二、背景部分
2.1 问题综述
给定上下文和问题,机器不仅需要找到问题的答案,还需要检测无法回答的情况。文章和问题表示为一个词条序列,记为P = x_p, Q = x_q,其中l_p为文章长度,l_q为问题长度。我们的目标是通过预测产生一个答案A ,由文章中的一段文字组成:A = x_p x_p 在 l_a 与 l_b 范围内,la和lb表示答案边界,如果没有答案返回一个空字符串。(这个与MS数据集不同,答案是抽取的,那个是生成的和抽取相结合的)
2.2 无答案抽取模型
为了预测答案的范围,目前的方法首先将文章和问题做embedding并编码成两个大小相同的向量。然后他们利用各种attention机制,如bi-attention(Seo et al., 2017)或reattention (Hu et al., 2018a),构建文章和问题的相似性特征,分别记为U = u_i 和 V = v_j。总结一下就是利用指针网络(Vinyals et al., 2015)对表示答案边界的短文词进行打分(Wang et al., 2017)。
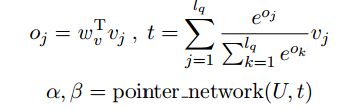
其中 α和β是一个范围得分,表示答案的开始和结束。为了进一步检测问题的答案是否存在,以前的方法 (Levy et al.,2017; Clark and Gardner, 2018) 除了预测答案范围的分布以外还进一步预测没有答案的概率。具体地说,一个共享的softmax函数可以对有无答案的预测和范围预测的概率进行标准化,产生一个综合的无答案损失,定义为:
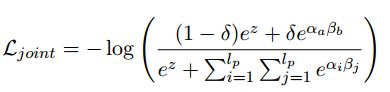
a和b是数据中给出的开始和结束位置,δ是1代表有答案,0则代表没有答案。在测试时,一旦归一化的无答题分数超过某个阈值,就会发现问题是没有答案的。
三、方法部分
在本节中,我们描述了我们提出的read-then-verify模型。该系统首先使用神经网络提取候选答案,并检测问题是否无法回答。然后利用答案验证器进一步验证预测答案的合理性。我们用两种新的辅助损失函数来帮助模型提升准确性,并研究了三种不同的结构来验证答案
3.1 Reader with Auxiliary Losses
虽然之前的no answer reader 能够共同学习答案抽取和有无答案检测,但是每个任务都存在两个问题。对于答案的提取,之前的方法中,没有人通过训练reader去寻找没有答案问题的情况。在我们的系统中,reader需要提取一个似乎可信的答案,然后反馈给接下来的问题验证阶段。由于span分数和no-answer分数之间共享loss,可能会引发冲突。由于这些标准化分数的总和总是1,一个大了另一个就会减小,反之亦然。因此, Clark and Gardner (2018)提出答案提取的不准确的loss可能会导致对没有答案检测的不精确预测。针对以上问题,我们提出了两个辅助损耗,在不互相干扰的情况下独立优化和增强每个任务的性能。
Independent Span Loss:
这种损失的目的是关注回答的抽取。在这项任务中,要求模型为所有可能的问题选取候选答案。因此,除了可回答的问题外,我们还将不可回答的案例作为积极的例子,并将似是而非的答案视为标准答案。为了不与无答案检测冲突,我们建议使用多头指针网络另外生产一对跨度分数α和β
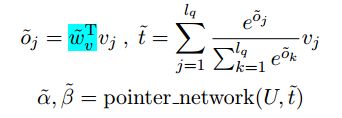
多头机制共享相同的网络架构,但是参数不同。
然后,我们将独立的跨度损失定义为:

其中a和b是真实回答边界。最后的范围概率是使用两个softmax简单平均得到的。
Independent No-Answer Loss
尽管使用了一个多头指针网络来防止冲突问题,但由于没有答案的概率z是用span分数标准化得到的,所以仍然可以对答案存在检测产生影响。因此,我们考虑更加偏向答案存在检测的预测。这是通过引入一个独立的loss实现的 :
![]()
其中σ是sigmod活函数。通过这个loss,我们期望该模型在不考虑共享loss的操作情况下,对有无答案的预测更加理想。
最后,我们将上述损失函数合并如下:
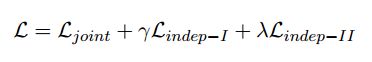
γ和λ两个超参控制两个辅助的损失函数。
3.2 Answer Verifier
提取答案后,使用回答验证器将回答句与问题进行比较,来判断支持答案的局部文本信息。在这里,我们将回答句定义为包含标准答案或似是而非答案的上下文句。我们为验证任务探索了三种不同的体系结构(如图2所示):
- (1)将输入作为长序列的顺序模型;
- (2)将两个句子相互编码的交互模型;
- (3)将这两种方法都考虑在内的混合模型
Model-I: Sequential Architecture
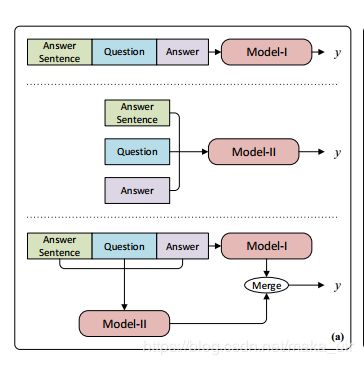
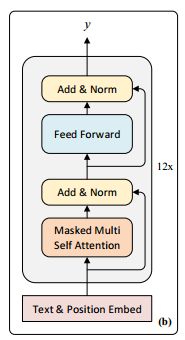
在模型A中,我们将标注答案和问题以及提取的答案转换输入序列。然后我们采用最近提出的Finetuned Transformer模型(Radford et al., 2018)来完成这项任务。该模型是一种多层Transformer decoder(Liu et al., 2018a),它首先在一个大的未标记的文本语料库上训练语言建模目标,然后对特定的目标任务进行精细训练。具体来说,给定一个回答句S、一个问题Q和一个提取的答案A,我们将两个句子与答案连接起来,并在两者之间添加分隔符以得到[S;Q;$;A]。该序列也可以表示为一系列Token X,然后通过multi head self attention 进行编码,然后根据位置进行feed-forward编码
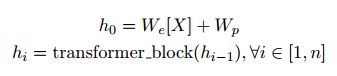
其中X为vocab中序列的索引,W_e 为令牌嵌入矩阵,Wp为位置嵌入矩阵,n为层数。然后将最后一个隐层输入到线性投影层,然后使用softmax函数输出有无答案概率y:
![]()
使用标准的交叉熵作为loss:
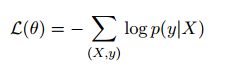
Model-II: Interactive Architecture
由于Answer Verifier需要对两个句子之间的关系进行建模,因此我们还考虑了一种基于交互的方法,它有以下几层:
Encoder:我们使用Glovd 来做embedding(Pennington et al., 2014),并且同时对字符进行了embedding。我们运行一个双向LSTM (BiLSTM) (Hochreiter和Schmidhuber, 1997)来编码字符并连接最后两个隐藏状态,以获得character embedding。此外,我们还使用二进制特性来表示一个单词是否是答案的一部分。然后,所有嵌入和特性一起被一个权重共享的BiLSTM连接和编码,生成两组上下文表示:

其中l_s为回答句长度,且[·;·]表示连接。
然后应用mean- max pooling(平均最大池化层)生成两个句子的表示。然后将所有的汇总向量连接到一个前馈分类器中,该分类器由带有gelu激活的投影层和softmax输出层组成,产生无答案概率。与之前一样,我们优化了负对数似然目标函数
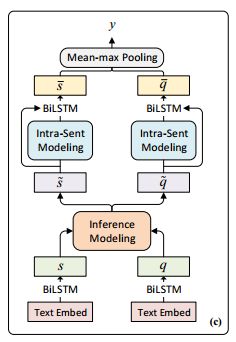
Model-III: Hybrid Architecture
为了探索如何将模型A和模型B提取的特征进行集成以获得更好的表示能力,我们研究了上述两种模型的组合,即Model-C。我们将两个模型的输出向量合并成一个联合表示。然后使用统一的前馈分类器输出无答案概率。来探索一下两个模型综合的效果。在实践中,我们使用一个简单的连接来合并两个信息源。
实验部分
我们的no answer reader 使用是上下文段落进行训练,而answer接受的是oracle回答句的训练。模型A遵循无监督预处理和监督优化的过程。也就是说,首先使用语言建模目标对大型未标记文本语料库进行优化,以初始化其参数。然后将参数调整到与监督目标相适应的答案验证任务。对于ModeB,我们直接用监督损失来训练它。然而,ModelC包含两个不同的体系结构,它们需要不同的培训过程。因此,我们使用model A和model B的预训练参数初始化modelC,然后对整个模型进行微调,直到收敛
在测试阶段,reader首先会预测出候选的答案,以及无答案的概率。然后,answer verfity 验证所提取的答案及其句子,并输出句子级别的概率,一旦联合无答案概率(计算为上述两种概率的平均值)超过某个阈值,就会发现问题是无法回答的。我们调优这个阈值以最大化开发集上的F1得分,并报告EM(精确匹配)和F1指标。我们还使用精度度量(ACC)来评估无应答检测的性能,默认情况下其阈值设置为0.5
实验设置
我们使用Reinforced Mnemonic Reader阅读器(RMR) (Hu et al., 2018a)作为我们的基础阅读器,它是SQuAD1.1数据集中的最先进的阅读理解模型之一。使用了其默认参数,训练了无应答目标和我们的辅助损失。ELMo(嵌入语言模型)(Peters et al., 2018)被单独列在我们的实验配置中。的hyper-parameterγ是设置为0.3,λ= 1。至于答案验证器,我们使用Radford et al.(2018)的原始配置来进行模型A。对于ModelB,使用学习率为 0.0008 的Adam optimizer (Kingma and Ba, 2014),将隐藏层的size设置为300,使用dropout (Srivastava et al., 2014) 0.3,防止过度拟合。读取器的批处理大小为48,模型A的批处理大小为64,模型V为32。我们使用Glove(Pennington et al., 2014) 100D嵌入用于阅读器,300D嵌入用于ModelB和ModelC。我们使用nltk标记来预处理段落和问题,以及分割的句子。段落和句子被截断,分别不超过300字和150字。
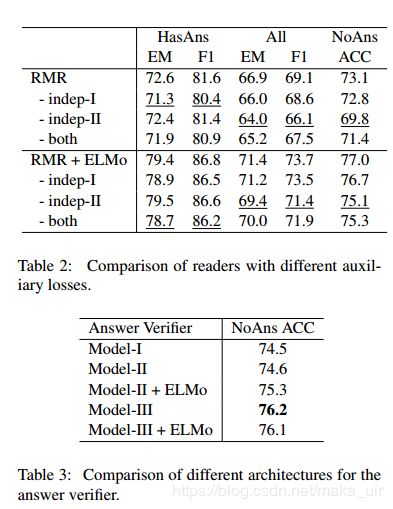
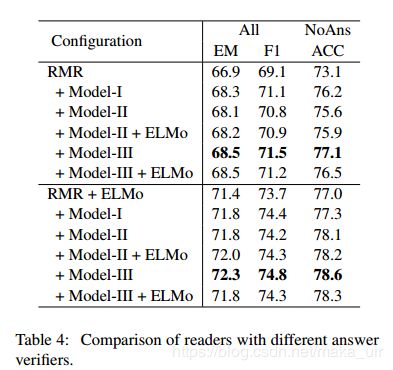
实验结果
相关工作
数据部分略
神经阅读模型通常利用各种注意机制来构建文章和问题的相互依赖的表示,并顺序地预测答案边界(Seoet al .,2017;Hu等人,2018a;Wang等人,2017;Yu等人,2018年;Hu等人,2018b)。然而,这些方法并不是为处理noanswer案例而设计的。为了解决这个问题,前期工作(Levy et al., 2017;(Clark and Gardner, 2018)除了回答跨度上的分布之外,预测一个不回答概率,从而共同学习不回答检测和回答提取。我们的无应答阅读器通过引入两个辅助损耗来独立地增强这两个任务,从而扩展了现有的方法
为了识别包含关系,已经提出了各种工作分支,包括基于编码的方法(Bowman et al., 2016),基于交互的方法(Parikh et al., 2016)和基于序列的方法(Radford et al., 2018)。在本文中,我们研究了最后两个分支,并进一步提出了一个混合架构,将两者适当地结合起来
Tan等人(2018)提出了一种基于答案验证的方法,通过将问题与文章进行比较,验证阅读理解任务的答案。与此相反,我们的回答验证者通过比较问题和回答句子来对文章进行去噪,从而专注于找到支持答案的局部蕴涵
总结部分
我们提出了一种“先读后验证”的系统,当一个问题没有答案的时候,这个系统可以避免回答。我们首先引入两个辅助损失,帮助读者分别专注于答案提取和无答案检测,然后使用一个答案验证器来验证预测答案的合法性,其中考察了三种不同的体系结构。我们的系统在团队2.0数据集上取得了最先进的成果,在提交时(2018年8月23日)超过了所有以前的方法。展望未来,我们计划为答案验证模型设计新的网络结构,该模型需要用更复杂的推理来处理问题
延伸阅读文章:
https://arxiv.org/pdf/1806.03822.pdf Know what you don’t know: unanswerable questions for squad SQuAD 2.0 版本
https://arxiv.org/pdf/1802.05365.pdf Deep contextualized word representations (ELMo embeddings)文章中用到了
无答案预测:
http://www.aclweb.org/anthology/K/K17/K17-1034.pdf Zero-shot relation extraction via reading comprehension.
http://cn.arxiv.org/pdf/1710.10723 Simple and Effective Multi-Paragraph Reading Comprehension
文本蕴含
https://arxiv.org/pdf/1606.01933.pdf A Decomposable Attention Model for Natural Language Inference
答案预测
http://tcci.ccf.org.cn/conference/2018/papers/106.pdf Modeling Answer Validation for Machine Reading Comprehension