Python爬虫学习笔记1——pathon爬虫原理
前言:
最近感觉python爬虫很有趣,打算开始系统的学习一下。
简单来说互联网是由一个个站点和网络设备组成的大网,我们通过浏览器访问站点,站点把HTML、JS、CSS代码返回给浏览器,这些代码经过浏览器解析、渲染,将丰富多彩的网页呈现我们眼前;
1、爬虫是什么?
简单来说,网络爬虫就是一段程序,它模拟人类访问互联网的形式,不停地从网络上抓取我们需要的数据。我们可以定制各种各样的爬虫,来满足不同的需求,如果法律允许,你可以采集在网页上看到的、任何你想要获得的数据。
爬虫是一种从网络上高速提取数据的方式(当然它也可以用作它途,如果需要的话。因为从本质上来说,它就是利用python与网站进行交互、并对网站返回的结果进行分析和处理的过程)。你可以把爬虫想想成一个机器人(其实它就是个机器人,不过是软件形式上的),坐在一台电脑旁边,不停地点开一个个网页,从里面复制指定文本或图片进行保存(假设需求就是保存指定文本或图片)。神奇的是,它的手速非常非常快,一阵眼花缭乱中,本地磁盘中就已经存了一大堆数据。
如果我们把互联网比作一张大的蜘蛛网,数据便是存放于蜘蛛网的各个节点,而爬虫就是一只小蜘蛛,
沿着网络抓取自己的猎物(数据)爬虫指的是:向网站发起请求,获取资源后分析并提取有用数据的程序;
从技术层面来说就是 通过程序模拟浏览器请求站点的行为,把站点返回的HTML代码/JSON数据/二进制数据(图片、视频) 爬到本地,进而提取自己需要的数据,存放起来使用;
2.网络爬虫能做什么
上面说了一大堆,可能也没说清楚爬虫究竟是什么。没关系,我们举几个例子来看。
比如,学校经常在官网上发布一些比较重要的通知,我不想每天都花费精力去看官网,却又想当有新通知的时候,就能知道,并看到它。
这种时候,就需要爬虫来帮忙咯。写一个程序,让它每半个小时或一个小时就去访问一次官网,检查有没有新的通知,如果没有,就什么都不做,等待下次检查,如果有,就将新通知从网页中提取出来,保存,并发邮件告诉我们通知的内容,然后继续等待即可。
假设,最近有点闲了,想看看电影,但又不想看烂片。于是,默默打开了豆瓣,上面有电影评分嘛,还有影评。我想要获取所以评分在8分以上的电影名称、简介以及该电影的部分热评,从中选出想看的出来。
这个时候,一个小小的爬虫就能轻轻松松地从一堆电影中找出符合要求的保存下来,不用费神地一个个去瞅了。如果你还会自然语言处理和机器学习,那就更棒了,或许你可以直接对这些数据进行分析,让程序匹配出你感兴趣的电影来。(当然了,举例子嘛,现实生活中,显然投入和产出不成正比= =看个电影哪那么麻烦orz)
再比如,采集京东、淘宝的商品评论信息啦,采集招聘网站的企业职位信息啦,采集微博信息啦,或者只是简单地爬一些美女图片啦……各种情况,采什么,看需求吧。
3.开发爬虫的准备工作
3.1 编程语言
做开发嘛,首先,我们要有一门开发语言,这里我选择python。
python是一门非常容易上手的解释型语言,还有大量的第三方类库,使用起来非常方便。编程语言用起来再也不用脑阔疼了,人生苦短,快用python~
3.2 开发平台和环境
开发平台,推荐linux。不要有太大的心里压力,因为现在ubuntu的图形界面做的已经很友好了,linux小白使用起来也没什么问题,真碰到问题再去百度或者谷歌就行了。
不推荐windows的原因之一是,在windows上面,很多类库安装起来会非常麻烦而且容易碰到各种问题,相比较而言,ubuntu就省心了很多
如果一定要用windows,并且有一台远程的linux主机的话,也可以考虑使用远程的python环境来开发。这一点,如果有时间,我写个教程吧,没时间就算了= =大家可以搜索一下关键词pycharm 远程调试。
IDE的话,推荐使用Pycharm。 windows、linux、macos多平台支持,非常好用,值得拥有。详细的我就不介绍了,用一用就会了。
4.推荐的python爬虫学习书籍
这里推荐两本很不错的python爬虫入门书籍:
1.米切尔 (Ryan Mitchell) (作者), 陶俊杰 (译者), 陈小莉 (译者)的 Python网络数据采集
2.范传辉 (作者)的 Python爬虫开发与项目实战
5、爬虫的基本流程:
用户获取网络数据的方式:
-
方式1:浏览器提交请求—>下载网页代码—>解析成页面
-
方式2:模拟浏览器发送请求(获取网页代码)->提取有用的数据->存放于数据库或文件中
爬虫要做的就是方式2;
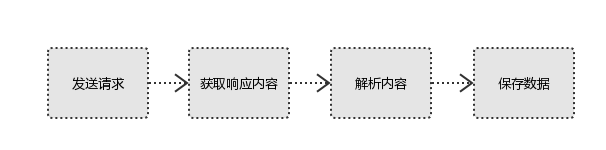
1、发起请求
使用http库向目标站点发起请求,即发送一个Request
Request包含:请求头、请求体等
Request模块缺陷:不能执行JS 和CSS 代码
2、获取响应内容
如果服务器能正常响应,则会得到一个Response
Response包含:html,json,图片,视频等
3、解析内容
解析html数据:正则表达式(RE模块),第三方解析库如Beautifulsoup,pyquery等
解析json数据:json模块
解析二进制数据:以wb的方式写入文件
4、保存数据
数据库(MySQL,Mongdb、Redis)
文件
参考文章:
1、http://www.cnblogs.com/linhaifeng/articles/7773496.html
2、https://www.cnblogs.com/sss4/p/7809821.html
3、https://blog.csdn.net/aaronjny/article/details/77885007