Surprise:一个Python推荐系统算法库
Surprise,是scikit系列中的一个推荐系统算法库。
官网:http://surpriselib.com/;Conda指令:https://anaconda.org/nicolashug/scikit-surprise
文档:http://surprise.readthedocs.io/en/stable/
一、基本模块
1. 推荐算法分类
可分为基于用户行为的推荐算法和基于内容(物品属性)的推荐算法。
基于用户行为数据的推荐算法一般称为协同过滤算法,主要方法有基于邻域的方法(neighborhood-based)、隐语义模型(latent factor model,LFM)、基于图的随机游走算法(random walk on graph)等。
在业界得到最广泛应用的算法是基于邻域的方法,主要包含下面两种算法:基于用户的协同过滤算法 UserCF,给用户推荐和他兴趣相似的其他用户喜欢的物品;基于物品的协同过滤算法 ItemCF,给用户推荐和他之前喜欢的物品相似的物品。
2. 基于邻域的CF算法的可设定度量准则,surprise.similarities 模块
余弦相似度 cosine、均方差相似度 msd、皮尔逊相关系数 pearson、基线皮尔逊相关系数 pearson_baseline。
3. 评价指标模块,surprise.accuracy
均方根误差 rmse、平均绝对误差 mae、fcp。
4. 数据集 surprise.dataset 模块
包含了 movielens-100k、movielens-1m、Jester 数据集。还可读取 pandas.DataFrame 格式及其他文件格式的数据集。
5. surprise.model_selection 模块
提供了用于交叉验证所需要的数据集切分、自动CV、网格搜索 GridSearchCV 等。
二、实现推荐算法
1. surprise.prediction_algorithms.algo_base
该模块定义了 类AlgoBase,每个单独的预测算法都继承自该类。
2. surprise.prediction_algorithms.predictions,定义了预测结果类。
3. Basic algorithms 基本算法
(1)prediction_algorithms.random_pred.NormalPredictor
从训练集估计得到一个正态分布(均值和标准差),基于该正态分布进行随机预测。
(2)prediction_algorithms.baseline_only.BaselineOnly
4. k-NN inspired algorithms kNN算法
(1)prediction_algorithms.knns.KNNBasic,即基本的协同过滤算法。
- k,kNN 算法中的 k 参数;
- min_k,需考虑的最小邻居数,当邻居数不足时,使用全局平均进行预测;
- sim_options,该参数接收一个 dict,如
- sim_options = {'name': 'cosine',
'user_based': False # compute similarities between items}
(2)prediction_algorithms.knns.KNNWithMeans,考虑了每个用户的平均打分值。

(3)prediction_algorithms.knns.KNNWithZScore,考虑了每个用户的 z-score 标准化。
(4)prediction_algorithms.knns.KNNBaseline,包含可学习参数,可使用 SGD 和 ALS 算法进行参数估计。推荐使用 pearson_baseline 度量方式。
- bsl_options,接收一个 dict,说明配置信息。
- bsl_options = {'method': 'sgd', 'learning_rate': .00005, }
5. Matrix Factorization-based algorithms
SVD、RSVD、ASVD、SVD++详解
(1)prediction_algorithms.matrix_factorization.SVD

(2)prediction_algorithms.matrix_factorization.SVDpp
引入隐式反馈,可以是打分动作(谁对某个商品打过分),或者是浏览记录等,隐式回馈的原因比较复杂,专门用一部分参数空间去建模,每个 item 对应一个向量 yi ,通过 user 隐含回馈过的 item 的集合来刻画用户的偏好。

(3)prediction_algorithms.matrix_factorization.NMF
NMF 非负矩阵分解,与 SVD 算法类似,用户和物品因子都必须是正值。
6. prediction_algorithms.slope_one.SlopeOne
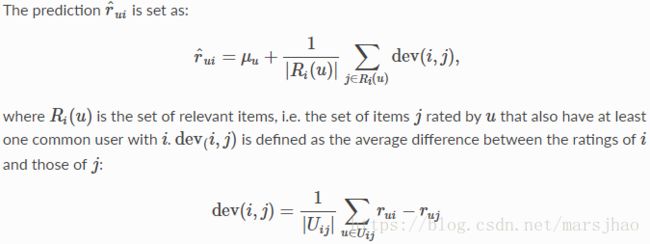
通过计算物品之间的平均差异来进行预测。
7. prediction_algorithms.co_clustering.CoClustering