python内存管理
python3.6.9 内存管理的官方文档 https://docs.python.org/zh-cn/3.6/c-api/memory.html
一、变量存哪了?
x = 10当我们在p1.py中定义一个变量x = 10,那么计算机把这个变量值10存放在哪里呢了?我们回顾计算机的三大核心组件为:CPU、内存和硬盘。一定不是CPU,那是存放在内存还是硬盘中了呢?我们再回顾变量运行的三个过程,如果我们没有使用python解释器运行p1.py这个文件,那么x=10很明显只是很普通的四个字符x、=、1、0。而只有Python解释器运行了这个文件,那字符进入了内存,才会有变量这个概念。也就是说变量是存放在内存当中的。
变量存放在内存中这句话太宽泛了,我们把它具体化。现在想象我们在学校(电脑内存)里上课,学校每开一个班,学校都会开辟一个教室给这个班级上课用(存放变量值10),而班级的门牌号则是(变量名x)。也就是说,对于电脑内存这个大内存,每定义一个变量就会在这个大内存中开辟一个小空间,小空间内存放变量值10,然后内存给这个小空间一个变量名x(门牌号),x指向10。
二、Python垃圾回收机制
对于p1.py,如果我们再加上一段代码x = 11,大内存会开辟另一个小空间存储变量值11,把变量值绑定另一个门牌号x,但是由于之前有x,所以大内存会解除x与10的连接,让x与11连接。这个时候10由于没有了门牌号,所以成为了python眼中的垃圾,python就会处理这个垃圾,释放10的内存占用,这就是python的垃圾回收机制。而其他语言需要手动把10的内存占用释放掉。
关于python的存储问题
(1)由于python中万物皆对象,所以python的存储问题是对象的存储问题,并且对于每个对象,python会分配一块内存空间去存储它
(2)对于整数和短小的字符等,python会执行缓存机制,即将这些对象进行缓存,不会为相同的对象分配多个内存空间
(3)容器对象,如列表、元组、字典等,存储的其他对象,仅仅是其他对象的引用,即地址,并不是这些对象本身
2.1.1垃圾回收
从基本原理上,当Python的某个对象的引用计数降为0时,说明没有任何引用指向该对象,该对象就成为要被回收的垃圾了。比如某个新建对象,它被分配给某个引用,对象的引用计数变为1。如果引用被删除,对象的引用计数为0,那么该对象就可以被垃圾回收。比如下面的表:
a = [1, 2, 3]
del a解析del
del a后,已经没有任何引用指向之前建立的[1,2,3],该表引用计数变为0,用户不可能通过任何方式接触或者动用这个对象,当垃圾回收启动时,Python扫描到这个引用计数为0的对象,就将它所占据的内存清空。
del a后,已经没有任何引用指向之前建立的[1, 2, 3]这个表。用户不可能通过任何方式接触或者动用这个对象。这个对象如果继续待在内存里,就成了不健康的变量。当=启动时,Python扫描到这个引用计数为0的对象,就将它所占据的内存清空。
(1)、垃圾回收时,Python不能进行其它的任务,频繁的垃圾回收将大大降低Python的工作效率;
(2)、Python只会在特定条件下,自动启动垃圾回收(垃圾对象少就没必要回收)
(3)、当Python运行时,会记录其中分配对象(object allocation)和取消分配对象(objectdeallocation)的次数。当两者的差值高于某个阈值时,垃圾回收才会启动。
我们可以通过gc模块的get_threshold()方法,查看该阈值:
import gc
print(gc.get_threshold())返回(700, 10, 10),后面的两个10是与分代回收相关的阈值,后面可以看到。700即是垃圾回收启动的阈值。可以通过gc中的set_threshold()方法重新设置。
我们也可以手动启动垃圾回收,即使用gc.collect()。
2.1.2分代回收
Python将所有的对象分为0,1,2三代;
所有的新建对象都是0代对象;
当某一代对象经历过垃圾回收,依然存活,就被归入下一代对象。
Python同时采用了分代(generation)回收的策略。这一策略的基本假设是,存活时间越久的对象,越不可能在后面的程序中变成垃圾。我们的程序往往会产生大量的对象,许多对象很快产生和消失,但也有一些对象长期被使用。出于信任和效率,对于这样一些“长寿”对象,我们相信它们的用处,所以减少在垃圾回收中扫描它们的频率。
Python将所有的对象分为0,1,2三代。所有的新建对象都是0代对象。当某一代对象经历过垃圾回收,依然存活,那么它就被归入下一代对象。垃圾回收启动时,一定会扫描所有的0代对象。如果0代经过一定次数垃圾回收,那么就启动对0代和1代的扫描清理。当1代也经历了一定次数的垃圾回收后,那么会启动对0,1,2,即对所有对象进行扫描。
这两个次数即上面get_threshold()返回的(700, 10, 10)返回的两个10。也就是说,每10次0代垃圾回收,会配合1次1代的垃圾回收;而每10次1代的垃圾回收,才会有1次的2代垃圾回收。
同样可以用set_threshold()来调整,比如对2代对象进行更频繁的扫描。
import gc
gc.set_threshold(700, 10, 5)2.1.3孤立的引用环
引用环的存在会给上面的垃圾回收机制带来很大的困难。这些引用环可能构成无法使用,但引用计数不为0的一些对象。
a = []
b = [a]
a.append(b)
del a
del b上面我们先创建了两个表对象,并引用对方,构成一个引用环。删除了a,b引用之后,这两个对象不可能再从程序中调用,就没有什么用处了。但是由于引用环的存在,这两个对象的引用计数都没有降到0,不会被垃圾回收。
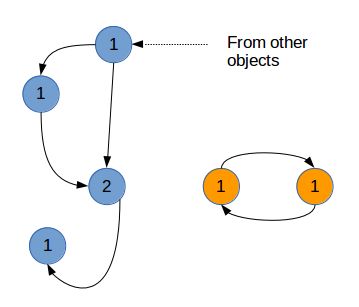
孤立的引用环
为了回收这样的引用环,Python复制每个对象的引用计数,可以记为gc_ref。假设,每个对象i,该计数为gc_ref_i。Python会遍历所有的对象i。对于每个对象i引用的对象j,将相应的gc_ref_j减1。
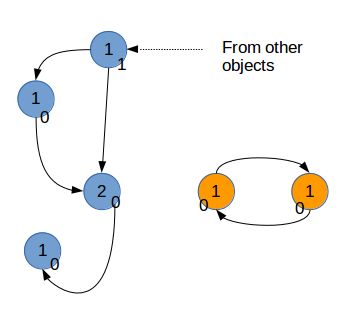
遍历后的结果
在结束遍历后,gc_ref不为0的对象,和这些对象引用的对象,以及继续更下游引用的对象,需要被保留。而其它的对象则被垃圾回收。
2.2.1 引用计数
从上述的解释我们可以知道只要某个变量值绑定着门牌号,就不是垃圾,反之变量值没有绑定着门牌号,这个变量值就是垃圾,python就会自动清理这个垃圾。这里我们对于这个门牌号给定一个专业的解释,在python中这个门牌号被称作引用计数。
x = 10 # 10引用计数加1为1
y = x # 10引用计数加1为2
x = 11 # 10引用计数减1为1;11引用计数加1为1
del y # 10引用计数减1为0,触发python垃圾回收机制,python清理10的内存占用上述代码就是一个引用计数加减的过程。
关于引用计数器
(1)一个对象会记录着引用自己的对象的个数,每增加一个引用,个数加一,每减少一个引用,个数减一
(2)查看引用对象个数的方法:导入sys模块,使用模块中的getrefcount(对象)方法,由于这里也是一个引用,故输出的结果多1
(3)增加引用个数的情况:1.对象被创建p = Person(),增加1;2.对象被引用p1 = p,增加1;3.对象被当作参数传入函数func(object),增加2,原因是函数中有两个属性在引用该对象;4.对象存储到容器对象中l = [p],增加1
(4)减少引用个数的情况:1.对象的别名被销毁del p,减少1;2.对象的别名被赋予其他对象,减少1;3.对象离开自己的作用域,如getrefcount(对象)方法,每次用完后,其对对象的那个引用就会被销毁,减少1;4.对象从容器对象中删除,或者容器对象被销毁,减少1
(5)引用计数器用法:
import sys
class Person(object):
pass
p = Person()
p1 = p
print(sys.getrefcount(p))
p2 = p1
print(sys.getrefcount(p))
p3 = p2
print(sys.getrefcount(p))
del p1
print(sys.getrefcount(p))多一个引用,结果加1,销毁一个引用,结果减少1
import sys
class Num:
pass
a = Num()
print(sys.getrefcount(Num()))
print(sys.getrefcount(a))
print(sys.getrefcount(3000))
print(sys.getrefcount(1))循环引用导致内存泄露
import sys
class ClassA():
def __init__(self):
print( 'object born,id:%s'%str(hex(id(self))))
def __del__(self):
print('object del,id:%s'%str(hex(id(self))))
def f1():
while True:
c1=ClassA()
del c1
def f2():
while True:
c1=ClassA()
c2=ClassA()
c1.t=c2
c2.t=c1
del c1
del c2
f2()
import sys
class ClassA():
def __init__(self):
print( 'object born,id:%s'%str(hex(id(self))))
def __del__(self):
print('object del,id:%s'%str(hex(id(self))))
def f1():
while True:
c1=ClassA()
print(sys.getrefcount(c1))
del c1
# print(sys.getrefcount(c1))
def f2():
id_lis=[]
while True:
c1=ClassA()
c2=ClassA()
c1.t=c2
c2.t=c1
id_lis.append(hex(id(c1)))
id_lis.append(hex(id(c2)))
id_c1=id_lis[0]
id_c2=id_lis[1]
print('id_c1',id_c1)
print('id_c2',id_c2)
print(sys.getrefcount(c1))
print(sys.getrefcount(c2))
del c1
del c2
# print('c1',sys.getrefcount(id_c1))
# print('c2',sys.getrefcount(id_c2))
f2()
执行f2(),进程占用的内存会不断增大。
object born,id:0x237cf30
object born,id:0x237cf58
创建了c1,c2后,0x237cf30(c1对应的内存,记为内存1),0x237cf58(c2对应的内存,记为内存2)这两块内存的引用计数都是1,执行c1.t=c2和c2.t=c1后,这两块内存的引用计数变成2.
在del c1后,内存1的对象的引用计数变为1,由于不是为0,所以内存1的对象不会被销毁,所以内存2的对象的引用数依然是2,在del c2后,同理,内存1的对象,内存2的对象的引用数都是1。
虽然它们两个的对象都是可以被销毁的,但是由于循环引用,导致垃圾回收器都不会回收它们,所以就会导致内存泄露。
引用减少
from sys import getrefcount
a = [1, 2, 3]
b = a
print(getrefcount(b))
del a
print(getrefcount(b))
如果某个引用指向对象A,当这个引用被重新定向到某个其他对象B时,对象A的引用计数减少:
from sys import getrefcount
a = [1, 2, 3]
b = a
print(getrefcount(b))
a = 1
print(getrefcount(b))
2.3.1内存池机制
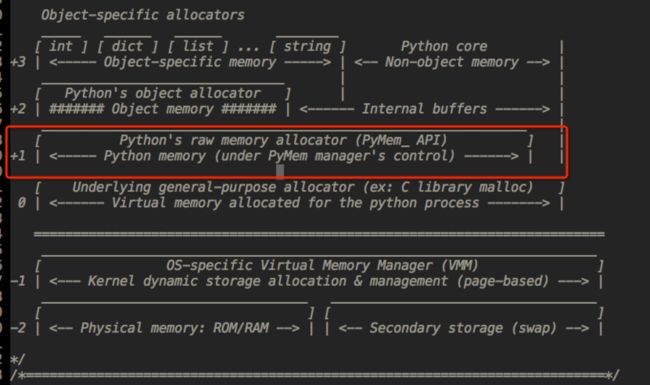
Python的内存机制以金字塔行,-1,-2层主要有操作系统进行操作,
第0层是C中的malloc,free等内存分配和释放函数进行操作;
第1层和第2层是内存池,有Python的接口函数PyMem_Malloc函数实现,当对象小于256K时有该层直接分配内存;
第3层是最上层,也就是我们对Python对象的直接操作;
Python中所有小于256个字节的对象都使用pymalloc实现的分配器,而大的对象则使用系统的 malloc。另外Python对象,如整数,浮点数和List,都有其独立的私有内存池,对象间不共享他们的内存池。也就是说如果你分配又释放了大量的整数,用于缓存这些整数的内存就不能再分配给浮点数。
扩展:在 C 中如果频繁的调用 malloc 与 free 时,是会产生性能问题的.再加上频繁的分配与释放小块的内存会产生内存碎片. Python 在这里主要干的工作有:
如果请求分配的内存在1~256字节之间就使用自己的内存管理系统,否则直接使用 malloc.
这里还是会调用 malloc 分配内存,但每次会分配一块大小为256k的大块内存.
经由内存池登记的内存到最后还是会回收到内存池,并不会调用 C 的 free 释放掉.以便下次使用.对于简单的Python对象,例如数值、字符串,元组(tuple不允许被更改)采用的是复制的方式(深拷贝?),也就是说当将另一个变量B赋值给变量A时,虽然A和B的内存空间仍然相同,但当A的值发生变化时,会重新给A分配空间,A和B的地址变得不再相同
三、小整数池
对于上一节讲的引用计数,需要注意的是:Python实现int的时候有个小整数池。为了避免因创建相同的值而重复申请内存空间所带来的效率问题, Python解释器会在启动时创建出小整数池,范围是[-5,256],该范围内的小整数对象是全局解释器范围内被重复使用,永远不会被垃圾回收机制回收。
在pycharm中运行python程序时,pycharm出于对性能的考虑,会扩大小整数池的范围,其他的字符串等不可变类型也都包含在内一便采用相同的方式处理了,我们只需要记住这是一种优化机制,至于范围到底多大,无需细究。
适用对象: int(float),str,bool
对象的具体细则:(了解即可)
int:那么大家都知道对于整数来说,小数据池的范围是-5~256 ,如果多个变量都是指向同一个(在这个范围内的)数字,他们在内存中指向的都是一个内存地址。
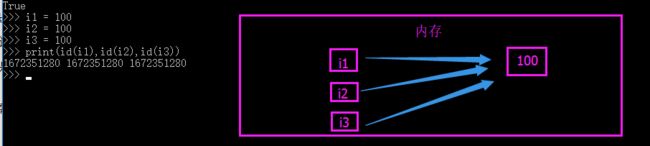
那么对于字符串的规定呢?
str:字符串要从下面这几个大方向讨论(了解即可!):
1,字符串的长度为0或者1,默认都采用了驻留机制(小数据池)。
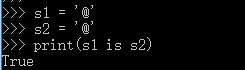
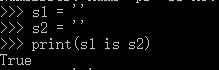
2,字符串的长度>1,且只含有大小写字母,数字,下划线时,才会默认驻留。
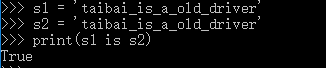
3,用乘法得到的字符串,分两种情况。
3.1 乘数为1时:
仅含大小写字母,数字,下划线,默认驻留。

含其他字符,长度<=1,默认驻留。
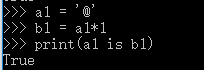
含其他字符,长度>1,默认驻留。
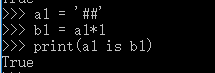
3.2 乘数>=2时:
仅含大小写字母,数字,下划线,总长度<=20,默认驻留。
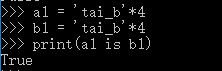
4,指定驻留。
from sys import intern
a = intern('hello!@'*20)
b = intern('hello!@'*20)
print(a is b)
#指定驻留是你可以指定任意的字符串加入到小数据池中,让其只在内存中创建一个对象,多个变量都是指向这一个字符串。
intern 是 Python 中的一个内建函数,该函数的作用就是对字符串进行 intern 机制处理,处理后返回字符串对象。我们发现但凡是值相同的字符串经过 intern 机制处理之后,返回的都是同一个字符串对象,这种方式在处理大数据的时候无疑能节省更多的内存空间,系统无需为相同的字符串重复分配内存,对于值相同的字符串共用一个对象即可。
满足以上字符串的规则时,就符合小数据池的概念。
bool值就是True,False,无论你创建多少个变量指向True,False,那么他在内存中只存在一个。
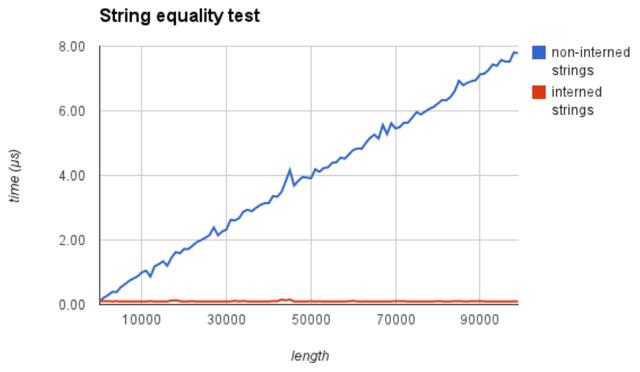
看一下用了小数据池(驻留机制)的效率有多高:
显而易见,节省大量内存在字符串比较时,非驻留比较效率o(n),驻留时比较效率o(1)。
补充
大整数池
大整数对象池。说明:终端是每次执行一次,所以每次的大整数都重新创建,而在pycharm中,每次运行是所有代码都加载都内存中,属于一个整体,所以
这个时候会有一个大整数对象池,即处于一个代码块的大整数是同一个对象。c1 和d1 处于一个代码块,而c1.b和c2.b分别有自己的代码块,所以不相等。
四、扩展(gc模块的介绍)
gc模块提供一个接口给开发者设置垃圾回收的选项。采用引用计数的方法管理内存的一个缺陷是循环引用的问题,而gc模块的一个主要功能就是
解决循环引用的问题
常用函数:
1.gc.set_debug(flags)设置gc的debug日志,一般设置为gc.DEBUG_LEAK
2.gc.collect([generation])显式进行垃圾回收,可以输入参数,0代表只检查第一代的对象,1代表检查
一,二代的对象,2代表检查一,二,三代的对象,如果不传参数,执行一个full collection,也就是等于传2.
返回不可达(unreachable objects)对象的数目
3.gc.get_threshold()获取的gc模块中自动执行垃圾回收的频率
4.gc.set_threshold(threshold0[,threshold1[,threshold2])设置自动执行垃圾回收的频率
5.gc.get_count()获取当前自动执行垃圾回收的计数器,返回一个长度为3的列表
gc模块的自动垃圾回收机制
必须要import gc模块,并且 is_enable()=True 才会启动自动垃圾回收
这个机制的主要作用就是发现并处理不可达的垃圾对象
垃圾回收=垃圾检查+垃圾回收
注意点
gc模块唯一处理不了的是循环引用的类都有__del__方法,所以项目中要避免定义__del__方法
class A():
def __init__(self):
pass
def __del__(self):
pass
class B():
def __init__(self):
pass
def __del__(self):
pass
a = A()
b = B()
a._b = b
b._a = a
del a
del b
print gc.collect() #结果是4
print gc.garbage #结果是[<__main__.A instance at 0x0000000002296448>, <__main__.B instance at 0x0000000002296488>]
可以看到,对我们自定义类的对象而言,collect方法并不能解决循环引用引起的内存泄露,即使在collect过后,解释器中仍然存在两个垃圾对象。
这里需要明确一下,之前对于“垃圾”二字的定义并不是很明确,在这里的这个语境下,垃圾是指在经过collect的垃圾回收之后仍然保持unreachable状态,即无法被回收,且无法被用户调用的对象应该叫做垃圾。gc模块中有garbage这个属性,其为一个列表,每一项都是当前解释器中存在的垃圾对象。一般情况下,这个属性始终保持为空集。
那么为什么在这种场景下collect不起作用了呢?这主要是因为我们在类中重载了__del__方法。__del__方法指出了在用del语句删除对象时除了释放内存空间以外的操作。一般而言,在使用了del语句的时候解释器会首先看要删除对象的引用计数,如果为0,那么就释放内存并执行__del__方法。在这里,首先del语句出现时本身引用计数就不为0(因为有循环引用的存在),所以解释器不释放内存;再者,执行collect方法时照理由应该会清除循环引用所产生的无效引用计数从而达到del的目的,对于这两个对象而言,python无法判断调用它们的__del__方法时会不会要用到对方那个对象,比如在进行b.del()时可能会用到b._a也就是a,如果在那之前a已经被释放,那么就彻底GG了。为了避免这种情况,collect方法默认不对重载了__del__方法的循环引用对象进行回收,而它们俩的状态也会从unreachable转变为uncollectable。由于是uncollectable的,自然就不会被collect处理,所以就进入了garbage列表。
collect返回4的原因是因为,在A和B类对象中还默认有一个__dict__属性,里面有所有属性的信息。比如对于a,有a.__dict__ = {'_b':<main.B instance at xxxxxxxx>}。a的__dict__和b的__dict__也是循环引用的。但是字典类型不涉及自定义的__del__方法,所以可以被collect掉。所以garbage里只剩下两个了。
有时候garbage里也会出现那两个__dict__,这主要是因为在前面可能设置了gc模块的debug模式,比如gc.set_debug(gc.DEBUG_LEAK),会把所有已经回收掉的unreachable的对象也都加入到garbage里面。set_debug还有很多参数诸如gc.DEBUG_STAT|DEBUG_COLLECTABLE|DEBUG_UNCOLLECTABLE|DEBUG_SAVEALL等等,设置了相关参数后gc模块会自动检测垃圾回收状况并给出实时地信息反映。