(keras)yolov3特定目标检测&自己图片做训练集
目录
先图片测试一下
yolo3检测自己标注的图片数据集&特定目标检测
自己的图片标注成Pascal VOC格式数据集
安装工具labelImg
操作方法
voc数据转化和准备
建立文件夹
使用脚本自动划分数据集
生成yolo格式文件
训练
修改加载路径
修改网络配置
重新生成h5文件
其他可设置参数
开始训练
测试模型
修改模型加载路径
运行
用qtpy做的界面,测试一下
一点改动
鉴于很多人问各种问题,我只是跑了keras版本的yolov3没看完程序,所以有的问题无法解答。相对而言推荐使用pytorch版本的yolov3:https://github.com/ming71/yolov3-pytorch,全部代码我都加了注释,这个我比较清楚可以解答。pytorch的是动态图,调试和速度都要快,推荐这个。
不同数据集标注转换代码见github代码工具:https://github.com/ming71/toolbox 不再单独回复.
先图片测试一下
1. 下载
代码:
git clone https://github.com/qqwweee/keras-yolo3.git
训练好的权值文件:
https://pjreddie.com/darknet/yolov2/
2.生成h5文件
yolov3.weights权值文件tf不识别,需要进行转化:
(1)cd到对应weight文件目录下
(2)转化:
python convert.py yolov3.cfg yolov3.weights model_data/yolo.h5
3.运行
使用python yolo_video.py --image运行,识别图片,然后键入路径文件名开始识别
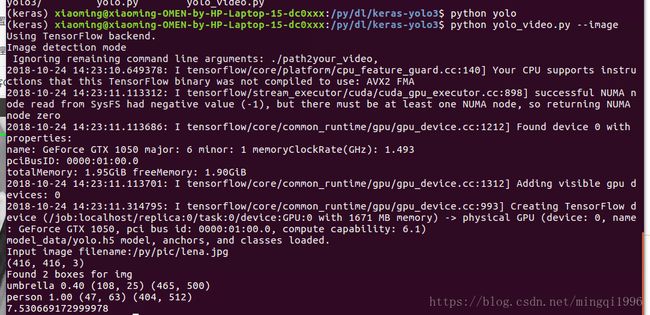
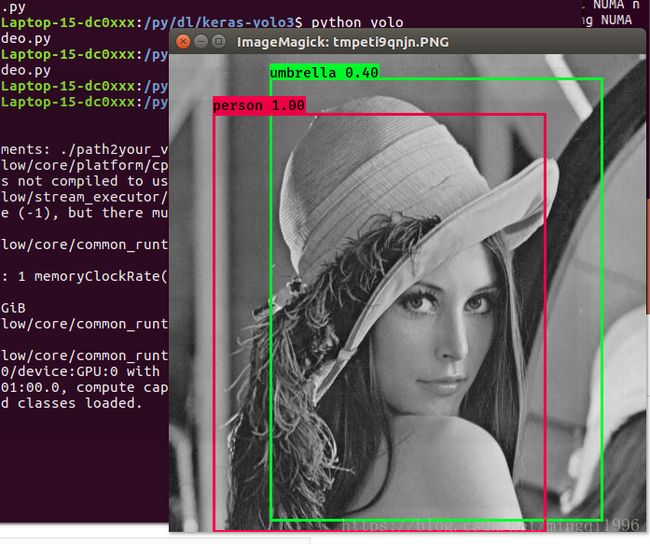
结果:
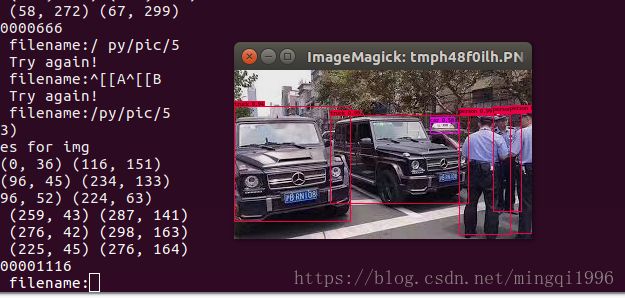
再测一个车辆和行人的:
视频的话是python yolo_vedio --input name.mp4
(网上 都是说直接python yolo.py,但是yolo.py下没有main函数,应该不能运行才是)
yolo3检测自己标注的图片数据集&特定目标检测
自己的图片标注成Pascal VOC格式数据集
安装工具labelImg
非常方便
git clone https://github.com/tzutalin/labelImg编译工具:
conda install lxml
make qt5py3直接python运行lableimage.py文件即可。
另外:
如果是现成非VOC数据集,需要格式转化成VOC的话,我的转换工具应该有帮助:
https://github.com/ming71/voc_data_convert
操作方法
1.运行打开:
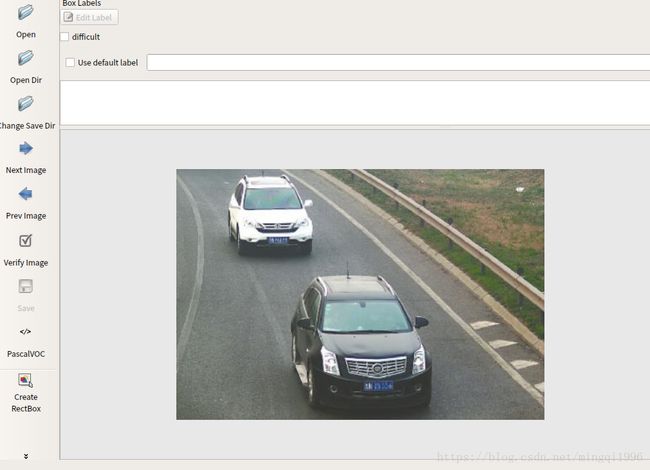
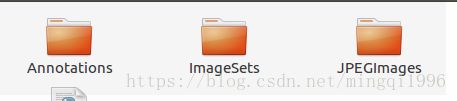
2.按voc数据格式要求创建文件夹:
Annotations:用于存放标注后的xml文件
ImageSets/Main:用于存放训练集、测试集、验收集的文件列表
JPEGImages:用于存放原始图像
3.将待标注图片下载到JPEGimages文件夹下
注意:文件名后缀要是xxx.jpg,不能是jpeg!
4.在OpenDir中,打开JPEGimage文件夹
(1)W键快捷creatbox,进行框选待测图片中的检测目标(如车,行人)
(2)输入目标的标签(如:car,person),后面和train.py,voc_annotation.py等调整时匹配
(2)左侧save到Annotations文件夹下,会存为xml文件(比较麻烦,也可以直接存当前文件夹,后期统一移到Annotations里)
(3)下一张图片继续
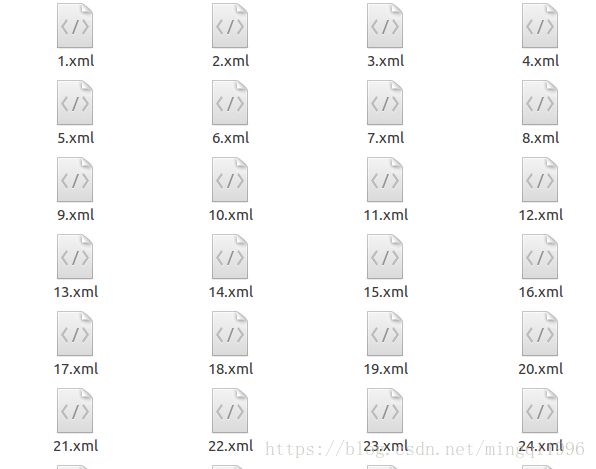
voc数据转化和准备
建立文件夹
新建文件夹VOCdevkit/VOC2007,将标注数据文件夹Annotations、ImageSets、JPEGImages放到文件夹VOCdevkit/VOC2007里面:

使用脚本自动划分数据集
git clone https://github.com/EddyGao/make_VOC2007/blob/master/make_main_txt.py将python文件放到VOC2007下,并运行。
python make_main_txt.py得到如下结果:

生成yolo格式文件
修改voc_annotation.py分类
classes修改为只有car
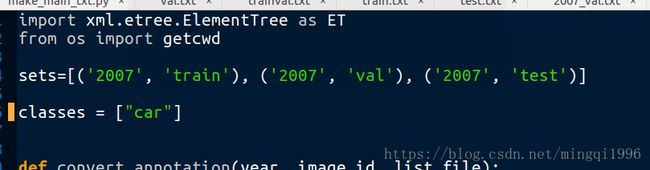
数据转换
回到yolo文件夹keras-yolo3-solo,执行上述转换文件:
python voc_annotation.py生成yolo文件:

将这三个文件移动到model_data文件夹下。并在该文件夹下新建文档my_class.txt,写入分类car.
(用以取代原来的yolo多分类voc_classes.txt)

训练
修改加载路径
annotation_path = 'model_data/2007_train.txt'
log_dir = 'model_data/logs/'
classes_path = 'model_data/my_class.txt'
修改网络配置

在主文件夹yolov3.cfg下,修改每个yolo层上一层的filter为18(单分类计算得到的数值),以及yolo层的class为1
计算方法参考:https://blog.csdn.net/davidlee8086/article/details/79693079
(注意:只修改yolo层上面的filter,其他卷积层的不该)
重新生成h5文件
python convert.py -w yolov3.cfg yolov3.weights model_data/yolo_weights.h5
其他可设置参数
batch_size =32 :默认值比较大,对电脑性能有要求,如果跑不动回报错,我改为16OK
注意:设置过小会导致出现损失计算nan的错误,适当增大即可
val_split = 0.1:如果只用十几张图片测试模型时,建议划分比大点,否则本来分到验证集就不多,乘以0.1后不到1就会没有验证集,导致验证集loss计算报错。
epochs=100:实验可以少跑几轮看看效果
开始训练
python train.py
生成默认模型文件在model_data/logs里面(左边是失败的,右边的没完成,训练了一半卡了,但是改个名字也能用.....毕竟也训练了的,改为trained_weights_final.h5):
测试模型
修改模型加载路径
在yolo.py下改为:
"model_path": 'logs/trained_weights_final.h5'运行
python yolo_video.py --image
用qtpy做的界面,测试一下
一个是yolo的权值,一个是我十几张图训练的辣鸡模型:

勉为其难能框住一点....多加点数据就好了(大概)
qt文件上传:https://download.csdn.net/download/mingqi1996/11146694(积分不够了,上传点东西凑一下)
一点改动
直接运行yolo.py也行,写个main函数就OK
if __name__ == '__main__':
yolo=YOLO()
path = '/py/pic/test.jpg'
try:
image = Image.open(path)
except:
print('Open Error! Try again!')
else:
r_image = yolo.detect_image(image)
r_image.show()
yolo.close_session()另一种环境配置:
cuda8.0
tensotflow 1.4.1(作者要求1.6.0,测试证明不用也行)
cudnn 7.0.5
keras 2.1.5
更正
由于voc数据集预训练的模型已经有了车辆,再进行训练没有意义。所以可以用来训练不包含在原来21类别的物体检测。
这种情况下,比如想要识别熊猫、遥感图像、蛇等,train.py的第一部分冻结神经元那块就没必要先加载原来的预训练的模型权值,再进行fine-tune,而是直接进行训练就行,不必修改cfg之类的。
至于损失的话,降到10左右就差不多训练可以了。
尝试训练一下...