Java(爬虫)底层实现爬取京东spu+sku数据
第一: 加入pom指定坐标(采用springboot的定时任务进行爬取数据)
org.springframework.boot
spring-boot-starter-parent
2.0.5.RELEASE
UTF-8
UTF-8
1.8
org.springframework.boot
spring-boot-starter-data-jpa
org.springframework.boot
spring-boot-starter-web
mysql
mysql-connector-java
runtime
org.springframework.boot
spring-boot-starter-test
test
org.apache.httpcomponents
httpclient
org.jsoup
jsoup
1.10.3
org.apache.commons
commons-lang3
org.springframework.boot
spring-boot-maven-plugin
第二步(2.1) 指定指定获取的数据库表以及对应的pojo
package com.jd.crawler.pojo;
import javax.persistence.*;
@Entity
@Table(name = "jd_item")
public class JdItem {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private Long spu;
private Long sku;
private String title;
private Double price;
private String pic;
private String url;
private java.util.Date created;
private java.util.Date updated;
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public Long getSpu() {
return spu;
}
public void setSpu(Long spu) {
this.spu = spu;
}
public Long getSku() {
return sku;
}
public void setSku(Long sku) {
this.sku = sku;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public Double getPrice() {
return price;
}
public void setPrice(Double price) {
this.price = price;
}
public String getPic() {
return pic;
}
public void setPic(String pic) {
this.pic = pic;
}
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
public java.util.Date getCreated() {
return created;
}
public void setCreated(java.util.Date created) {
this.created = created;
}
public java.util.Date getUpdated() {
return updated;
}
public void setUpdated(java.util.Date updated) {
this.updated = updated;
}
}
数据库表结构(2.2)

三: 配置application.properties进行连接数据库 (SpringDataJpa)
server.port=8081
#DB Configuration:
spring.datasource.driverClassName=com.mysql.jdbc.Driver
spring.datasource.url=jdbc:mysql://127.0.0.1:3306/crawler
spring.datasource.username=root
spring.datasource.password=12345
#JPA Configuration:
spring.jpa.database=MySQL
spring.jpa.show-sql=true
四: 编写Dao

五 ,我这里忽略了保存数据库service以及serviceimpl的操作
六,开始爬取数据,编写一个HttpUtils用来快速访问操作
package com.jd.crawler.utils;
import org.apache.http.client.config.RequestConfig;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.impl.conn.PoolingHttpClientConnectionManager;
import org.apache.http.util.EntityUtils;
import org.springframework.stereotype.Component;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStream;
import java.util.UUID;
/**
* @author misterWei
* @create 2018年10月06号:22点08分
* @mailbox [email protected]
*/
@Component
public class HttpUtils {
//创建网络连接管理池
private PoolingHttpClientConnectionManager cm;
public HttpUtils() {
this.cm= new PoolingHttpClientConnectionManager();
//最大连接数
this.cm.setMaxTotal(200);
//设置每个数据的连接数
this.cm.setDefaultMaxPerRoute(20);
}
//需要定义两个Method方法
//第一个用来访问连接
public String getHtml(String html){
//创建访问对象
CloseableHttpClient build = HttpClients.custom().setConnectionManager(cm).build();
//声明httpget来进行请求响应
HttpGet httpGet = new HttpGet(html);
httpGet.setConfig(this.getrequestConfig());
CloseableHttpResponse closeableHttpResponse = null;
try {
closeableHttpResponse = build.execute(httpGet);
if (closeableHttpResponse.getStatusLine().getStatusCode()==200){
//此次状态请求200 成功 定义一个html的字符串页面
String htmlStr = "";
//并判断当前请求数据是否又返回数据内容等信息
if (closeableHttpResponse.getEntity() != null){
htmlStr = EntityUtils.toString( closeableHttpResponse.getEntity(),"utf8");
}
return htmlStr;
}
}catch (Exception e){
e.printStackTrace();
}finally {
try {
if ( closeableHttpResponse != null){
closeableHttpResponse.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
return null;
}
//第二个用来保存图片
public String getImage(String url){
//创建访问对象
CloseableHttpClient build = HttpClients.custom().setConnectionManager(cm).build();
//声明httpget来进行请求响应
HttpGet httpGet = new HttpGet(url);
httpGet.setConfig(this.getrequestConfig());
CloseableHttpResponse closeableHttpResponse = null;
try {
closeableHttpResponse = build.execute(httpGet);
if (closeableHttpResponse.getStatusLine().getStatusCode()==200){
//获取文件类型 MIME类型属性
String endName = url.substring(url.lastIndexOf("."));
//根据UUID来生成文件名称
String fileName = UUID.randomUUID().toString()+endName;
OutputStream outputStream = new FileOutputStream("C:\\Users\\asus\\Desktop\\images\\"+fileName);
//字节流写入指定的文件夹中
closeableHttpResponse.getEntity().writeTo(outputStream);
return fileName;
}
}catch (Exception e){
e.printStackTrace();
}finally {
try {
if ( closeableHttpResponse!=null){
closeableHttpResponse.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
return null;
}
//此方法用来设置连接参数
private RequestConfig getrequestConfig(){
RequestConfig requestConfig = RequestConfig.custom().setConnectTimeout(3000)//设置创建连接的超时时间
.setConnectionRequestTimeout(3000) //设置获取连接的超时时间
.setSocketTimeout(1000).build();//设置连接的超时时间
return requestConfig;
}
}
七:主业务的编码流程:
package com.jd.crawler.task;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.jd.crawler.service.CrawlerJdService;
import com.jd.crawler.pojo.JdItem;
import com.jd.crawler.utils.HttpUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.stereotype.Component;
import java.util.Date;
import java.util.List;
/**
* @author misterWei
* @create 2018年10月06号:22点39分
* @mailbox [email protected]
*/
@Component
public class JdItemTask {
@Autowired
private HttpUtils httpUtils;
@Autowired //这个就是一个保存数据库的service操作
private CrawlerJdService crawlerJdService;
//用来转化金额操作,
public static final ObjectMapper objectMapper = new ObjectMapper();
//主要逻辑的编写
//间隔100秒执行一次
@Scheduled(fixedDelay = 1000 * 100)
public void process() throws Exception{
String url =
"https://search.jd.com/Search" +
"?keyword=%E6%89%8B%E6%9C%BA&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&wq=%E6%89%8B%E6%9C%BA&cid2=653&cid3=655&s=61&click=0" +
"&page=";//分页爬取数据
for (int i = 0; i < 10; i=i+2) {
String html = this.httpUtils.getHtml(url + i);
//解析页面数据,并将解析的数据保存到数据库中
this.parserHTML(html);
System.out.println("保存成功!");
}
}
private void parserHTML(String html) throws Exception {
//使用Jsoup进行解析页面操作
Document parse = Jsoup.parse(html);
//根据页面的标签属性进行获取数据
Elements select = parse.select("div#J_goodsList > ul > li");
for (Element element : select) {
//获取爬取数据的spu信息
long spu = Long.parseLong(element.attr("data-spu"));
Elements select1 = element.select("li.ps-item img");
for (Element element1 : select1) {
//获取sku数据
long sku = Long.parseLong(element1.attr("data-sku"));
//判断当前商品是否抓取
JdItem jdItem = new JdItem();
jdItem.setSku(sku);
List jdItems = crawlerJdService.ifJditems(jdItem);
if (jdItems.size()>0){
//如果大于0说明是有内容的也就是说是有数据的那就不执行操作,重新执行下一次循环
continue;
}
jdItem.setSpu(spu);
//商品url
jdItem.setUrl("https://item.jd.com/"+sku+".html");
//创建时间
jdItem.setCreated((java.util.Date) new Date());
//更新时间
jdItem.setUpdated((java.util.Date) new Date());
//获取商品标题
String html1 = this.httpUtils.getHtml(jdItem.getUrl());
String title = Jsoup.parse(html1).select("div.sku-name").text();
jdItem.setTitle(title);
//获取商品价格
String priceurl = "https://p.3.cn/prices/mgets?skuIds=J_"+sku;
String html2 = this.httpUtils.getHtml(priceurl);
double price = objectMapper.readTree(html2).get(0).get("p").asDouble();
jdItem.setPrice(price);
//获取图片价格信息
String replace ="https:"+ element1.attr("data-lazy-img").replace("/n9/", "/n1/");
String image = this.httpUtils.getImage(replace);
System.out.println(image);
jdItem.setPic(image);
//保存数据到数据库中
this.crawlerJdService.saveJdItem(jdItem);
}
}
}
}
注意的是 本人在使用ObjectMapper 这个对象来自package com.fasterxml.jackson.databind
八,开启启动类启动获取数据:
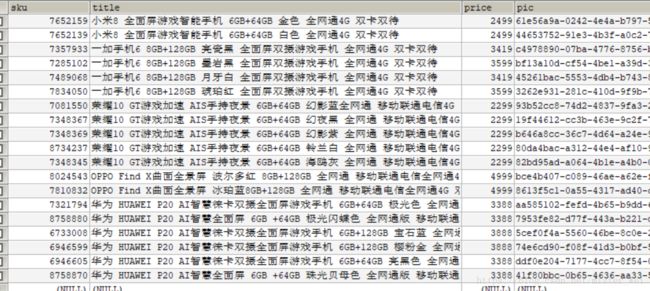
我这里写的并不完善,但是在我的github中已经上传了,不仅仅有这些内容,还有webmagic小框架的搭建爬取数据,并且使用ElasticSearch作为搜索引擎,搭建,喜欢的朋友可以clone下来进行参考.
地址为:(https://github.com/selfconfidence/crawler-html.git)