Intellij连接远程hadoop
环境:服务器:CentOS6.6 Hadoop-2.7.2
client端:windows10:开发工具:intellij IDEA
前期准备:需要在windows平台下载hadoop-2.7.2的bin包,并且解压到本地目录,我的是在E:\hadoop-2.7.2\hadoop-2.7.2,具体如下:
1、在intellij中创建一个maven project flie-》new project
 /
/
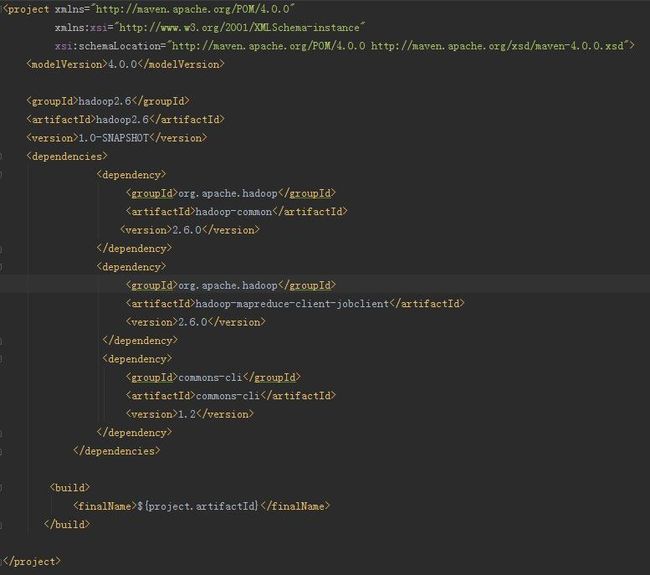
2、pom.xml文件里编写如下:
3、新建java class WordCount
4、在工程目录下的resources文件夹下新建log4j.properties文件和core-site.xml文件
我的log4j.properties是从服务器的hadoop的配置目录中拷过来的。
core-site.xml文件的内容如下:
fs.defaultFS
hdfs://mj2:9000
5、添加hadoop-2.7.2依赖包
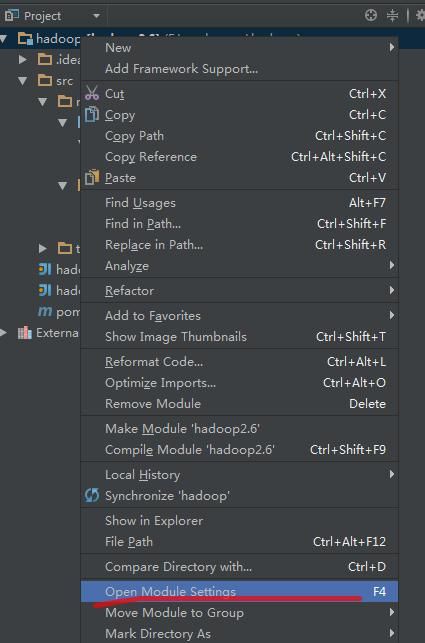


给jar包文件夹取名为hadoop-library,最后点apply即可。

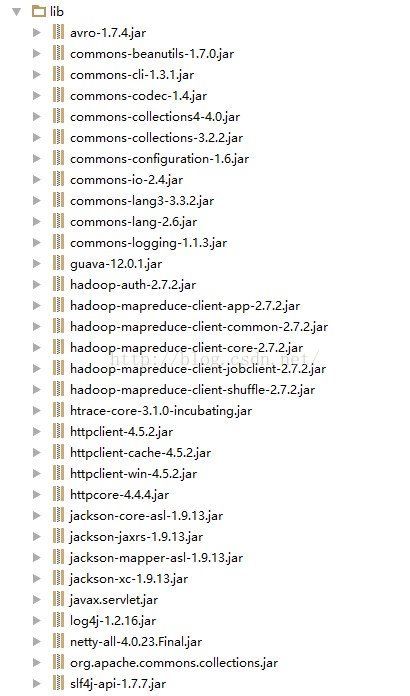
我的项目中可能由于网络问题,maven依赖的包总是下载不下来,所以我把需要的包都下载或者从服务器拷贝过来放在了lib文件夹中。具体如下:
6、还需要的就是在hadoop的解压目录下的bin目录下,需要的两个文件原来没有,一个是winutils.exe,另一个是hadoop.dll文件。所以需要上网下载winutils.exe和hadoop.dll文件。为了防止冲突,可以把下载的hadoop.dll文件放在C:\Windows\System32中。
(我在网上没有找到hadoop版本-2.7.2的hadoop.dll,所以用的2.7.2版本的同样可以)
7、WordCount的代码:
package wordCounts;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static class TokenizerMapper
extends Mapper{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
System.setProperty("hadoop.home.dir", "E:\\hadoop-2.7.2\\hadoop-2.7.2");
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount ");
System.exit(2);
}
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
} 8、配置WordCount运行参数
Run-》Edit Configurations...
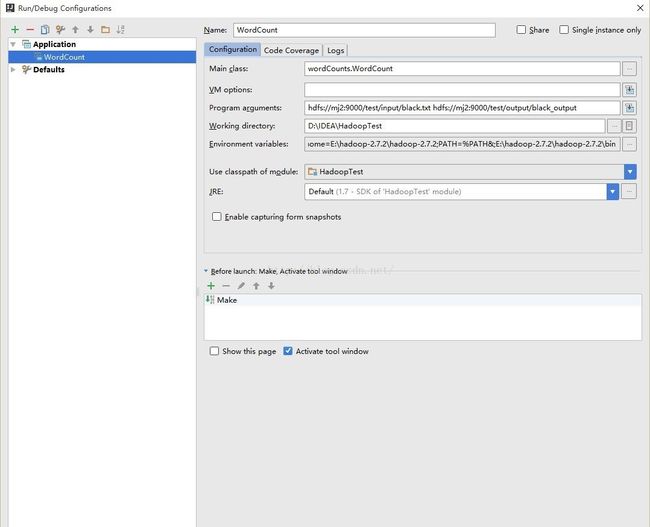
其中,Program arguments:为传入的hdfs中的文件,以及reduce之后的结果文件目录(中间用空格隔开)
Environment variables:为程序运行时设定的环境变量:具体如下:

需要注意的事项有:
(1)你的windows下必须有一个和线上hadoop集群一样的用户名
(2)确保你的hadoop程序中的所有jar都是compile
intellij下唯一不爽的,由于没有类似eclipse的hadoop插件,每次运行完wordcount,下次再要运行时,只能手动命令行删除output目录,再行调试。为了解决这个问题,可以将WordCount代码改进一下,在运行前先删除output目录,见下面的代码:
/**
* 删除指定目录
*
* @param conf
* @param dirPath
* @throws IOException
*/
private static void deleteDir(Configuration conf, String dirPath) throws IOException {
FileSystem fs = FileSystem.get(conf);
Path targetPath = new Path(dirPath);
if (fs.exists(targetPath)) {
boolean delResult = fs.delete(targetPath, true);
if (delResult) {
System.out.println(targetPath + " has been deleted sucessfullly.");
} else {
System.out.println(targetPath + " deletion failed.");
}
}
}