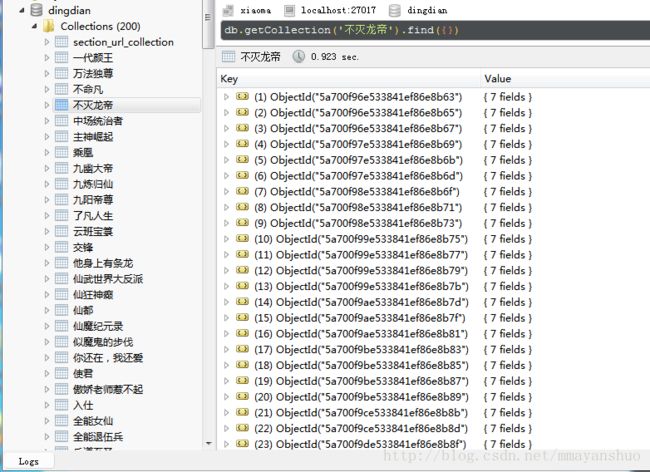
Python网络爬虫(九):爬取顶点小说网站全部小说,并存入MongoDB
前言:本篇博客将爬取顶点小说网站全部小说、涉及到的问题有:Scrapy架构、断点续传问题、Mongodb数据库相关操作。
背景:
Python版本:Anaconda3
运行平台:Windows
IDE:PyCharm
数据库:MongoDB
浏览器工具: Chrome浏览器
前面的博客中已经对Scrapy作了相当多的介绍所以这里不再对Scrapy技术作过多的讲解。
一、爬虫准备工作:
此次我们爬取的是免费小说网站:顶点小说
http://www.23us.so/
我们要想把它全部的小说爬取下来,是不是得有全部
小说的链接?
我们看到顶点小说网站上有一个总排行榜。

点击进入后我们看到,这里有网站上所有的小说,一共有1144页,每页大约20本小说,算下来一共大约有两万两千多本,是一个庞大的数据量,并且小说的数量还在不断的增长中。
好!我们遇到了第一个问题,如何获取总排行榜中的页数呢?也就是现在的“1144”。
1、获取排行榜页面数:
最好的方法就是用Xpath。
我们先用F12审查元素,看到“1144”放在了“id”属性为“pagestats”的em节点中。

我们再用Scrapy Shell分析一下网页。
注意:Scrapy Shell是一个非常好的工具,我们在编写爬虫过程中,可以用它不断的测试我们编写的Xpath语句,非常方便。
输入命令:
scrapy shell "http://www.23us.so/top/allvisit_2.html"然后就进入了scrapy shell

因为页数放在“id”属性为“pagestats”的em节点中,所以我们可以在shell中输入如下指令获取。
response.xpath('//*[@id="pagestats"]/text()').extract_first()
我们可以看到,Xpath一如既往的简单高效,页面数已经被截取下来了。
2、获取小说主页链接、小说名称:
接下来,我们遇到新的问题,如何获得每个页面上的小说的链接呢?我们再来看页面的HTML代码。

小说的链接放在了“a”节点里,而且这样的a节点区别其他的“a”节点的是,没有“title”属性。
所以我们用shell测试一下,输入命令:
response.xpath('//td/a[not(@title)]/@href').extract()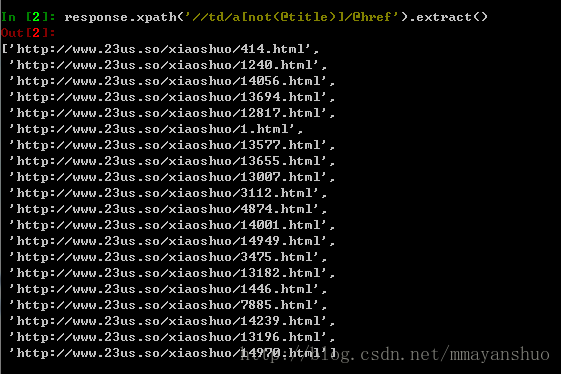
我们看到,小说的链接地址我们抓到了。
同样还有小说名,
response.xpath('//td/a[not(@title)]/text()').extract()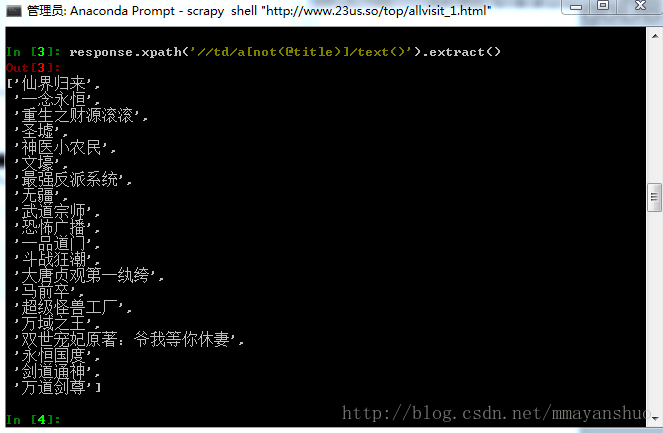
我们可以看到页面上的小说名称我们也已经抓取到了。
3、获取小说详细信息:
我们点开页面上的其中一个小说链接:
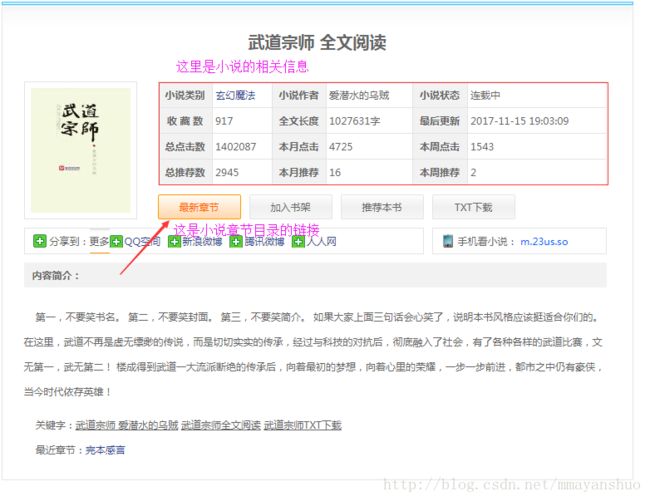
这里有小说的一些相关信息和小说章节目录的地址。
我们想要的数据首先是小说全部章节目录的地址,然后是小说类别、小说作者、小说状态、小说最后更新时间。
我们先看小说全部章节目录的地址。用F12,我们看到:

小说全部章节地址放在了“class”属性为“btnlinks”的“p”节点的第一个“a”节点中。
我们还是用scrapy shell测试一下我们写的xpath语句。
键入命令,进入shell界面
scrapy shell "http://www.23us.so/xiaoshuo/13007.html"在shell中键入命令:
response.xpath('//p[@class="btnlinks"]/a[1]/@href').extract_first()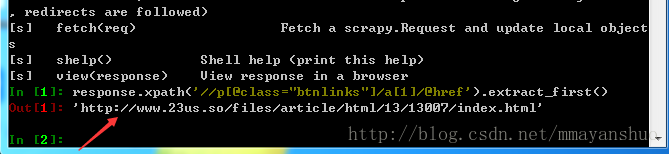
小说的章节目录页面我们已经截取下来了。
类似的还有小说类别、小说作者、小说状态、小说最后更新时间,命令分别是:
#小说类别
response.xpath('//table/tr[1]/td[1]/a/text()').extract_first()
#小说作者
response.xpath('//table/tr[1]/td[2]/text()').extract_first()
#小说状态
response.xpath('//table/tr[1]/td[3]/text()').extract_first()
#小说最后更新时间
response.xpath('//table/tr[2]/td[3]/text()').extract_first()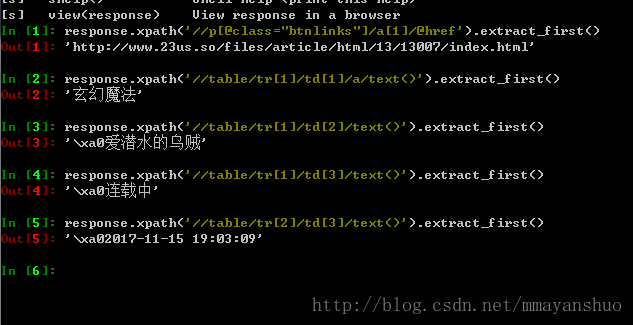
4、获取小说全部章节:
我们点开“最新章节”,来到小说全部章节页面。

我们如何获得这些链接呢?答案还是Xpath。
用F12看到,各章节地址和章节名称放在了一个“table”中:

退出上次的scrapy shell ,分析 全部章节页面。
scrapy shell "http://www.23us.so/files/article/html/13/13007/index.html"在shell中键入Xpath语句:
response.xpath('//table/tr/td/a/@href').extract()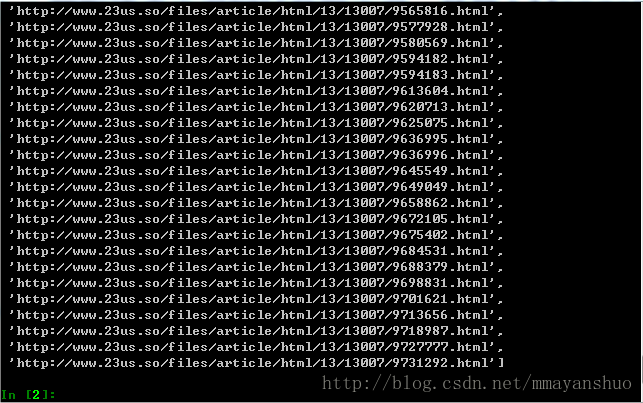
同样还有各章节名称
response.xpath('//table/tr/td/a/text()').extract()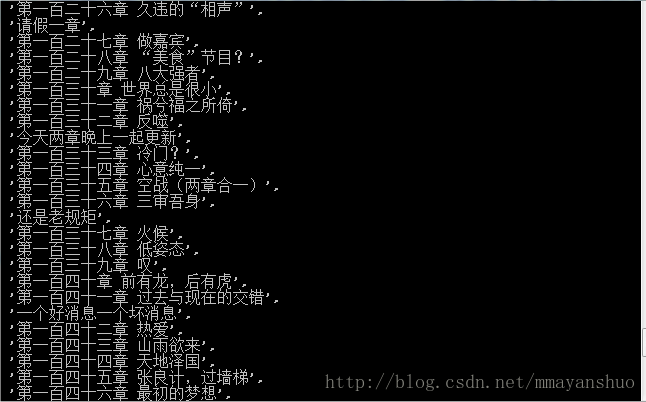
5、爬取小说章节内容:
好了,小说各个章节地址我们截取下来了,接下来就是小说各个章节的内容。
我们用F12看到,章节内容放在了“id”属性为“contents”的“dd”节点中。

这里我们再用Xpath看一下,键入Xpath语句:
Response.xpath('//dd[@id="contents"]').extract()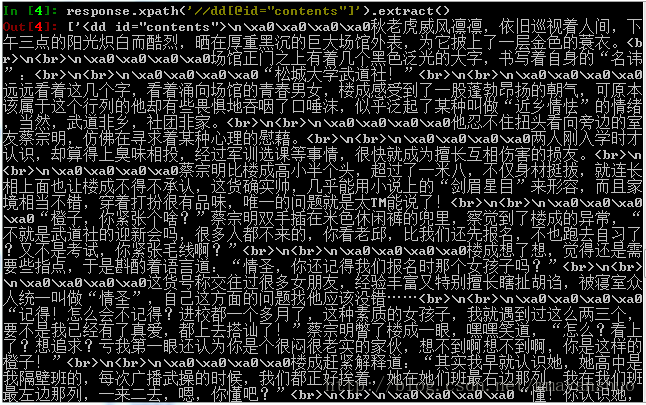
我们看到,小说内容已经让我们截取到了!
二、编写爬虫:
整个流程上面已经介绍过了,还有一个非常重要的问题:
断点续传问题
我们知道,爬虫不可能一次将全部网站爬取下来,网站的数据量相当庞大,在短时间内不可能完成爬虫工作,在下一次启动爬虫时难道再将已经做过的工作再做一次?当然不行,这样的爬虫太不友好。那么我们如何来解决断点续传问题呢?
我这里的方法是,将已经爬取过的小说每一章的链接存入Mongodb数据库的一个集合中。在爬虫工作时首先检测,要爬取的章节链接是否在这个集合中:
如果在,说明这个章节已经爬取过,不需要再次爬取,跳过;
如果不在,说明这个章节没有爬取过,则爬取这个章节。爬取完成后,将这个章节链接存入集合中;
如此,我们就完美实现了断点续传问题,十分好用。
接下来贴出整个项目代码:
注释我写的相当详细,熟悉一下就可以看懂。
items.py
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class DingdianxiaoshuoItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
#小说名字
novel_name=scrapy.Field()
#小说类别
novel_family=scrapy.Field()
#小说主页地址
novel_url=scrapy.Field()
#小说作者
novel_author=scrapy.Field()
#小说状态
novel_status=scrapy.Field()
#小说字数
novel_number=scrapy.Field()
#小说所有章节页面
novel_all_section_url= scrapy.Field()
#小说最后更新时间
novel_updatetime=scrapy.Field()
#存放小说的章节地址,程序中存放的是一个列表
novel_section_urls=scrapy.Field()
#存放小说的章节地址和小说章节名称的对应关系,程序中存储的是一个字典
section_url_And_section_name=scrapy.Field()
dingdian.py
# -*- coding: utf-8 -*-
import scrapy
from scrapy import Selector
from dingdianxiaoshuo.items import DingdianxiaoshuoItem
class dingdian(scrapy.Spider):
name="dingdian"
allowed_domains=["23us.so"]
start_urls = ['http://www.23us.so/top/allvisit_1.html']
server_link='http://www.23us.so/top/allvisit_'
link_last='.html'
#从start_requests发送请求
def start_requests(self):
yield scrapy.Request(url = self.start_urls[0], callback = self.parse1)
#获取总排行榜每个页面的链接
def parse1(self, response):
items=[]
res = Selector(response)
#获取总排行榜小说页码数
max_num=res.xpath('//*[@id="pagestats"]/text()').extract_first()
max_num=max_num.split('/')[1]
print("总排行榜最大页面数为:"+max_num)
#for i in max_num+1:
for i in range(0,int(max_num)):
#构造总排行榜中每个页面的链接
page_url=self.server_link+str(i)+self.link_last
yield scrapy.Request(url=page_url,meta={'items':items},callback=self.parse2)
#访问总排行榜的每个页面
def parse2(self,response):
print(response.url)
items=response.meta['items']
res=Selector(response)
#获得页面上所有小说主页链接地址
novel_urls=res.xpath('//td/a[not(@title)]/@href').extract()
#获得页面上所有小说的名称
novel_names=res.xpath('//td/a[not(@title)]/text()').extract()
page_novel_number=len(novel_urls)
for index in range(page_novel_number):
item=DingdianxiaoshuoItem()
item['novel_name']=novel_names[index]
item['novel_url'] =novel_urls[index]
items.append(item)
for item in items:
#访问每个小说主页,传递novel_name
yield scrapy.Request(url=item['novel_url'],meta = {'item':item},callback = self.parse3)
#访问小说主页,继续完善item
def parse3(self, response):
#接收传递的item
item=response.meta['item']
#写入小说类别
item['novel_family']=response.xpath('//table/tr[1]/td[1]/a/text()').extract_first()
#写入小说作者
item['novel_author']=response.xpath('//table/tr[1]/td[2]/text()').extract_first()
#写入小说状态
item['novel_status']=response.xpath('//table/tr[1]/td[3]/text()').extract_first()
#写入小说最后更新时间
item['novel_updatetime']=response.xpath('//table/tr[2]/td[3]/text()').extract_first()
#写入小说全部章节页面
item['novel_all_section_url']=response.xpath('//p[@class="btnlinks"]/a[1]/@href').extract_first()
url=response.xpath('//p[@class="btnlinks"]/a[@class="read"]/@href').extract_first()
#访问显示有全部章节地址的页面
print("即将访问"+item['novel_name']+"全部章节地址")
#yield item
yield scrapy.Request(url=url,meta={'item':item},callback=self.parse4)
#将小说所有章节的地址和名称构造列表存入item
def parse4(self, response):
#print("这是parse4")
#接收传递的item
item=response.meta['item']
#这里是一个列表,存放小说所有章节地址
section_urls=response.xpath('//table/tr/td/a/@href').extract()
#这里是一个列表,存放小说所有章节名称
section_names=response.xpath('//table/tr/td/a/text()').extract()
item["novel_section_urls"]=section_urls
#计数器
index=0
#建立哈希表,存储章节地址和章节名称的对应关系
section_url_And_section_name=dict(zip(section_urls,section_names))
#将对应关系,写入item
item["section_url_And_section_name"]=section_url_And_section_name
yield item
settings.py
# -*- coding: utf-8 -*-
# Scrapy settings for dingdianxiaoshuo project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://doc.scrapy.org/en/latest/topics/settings.html
# https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'dingdianxiaoshuo'
SPIDER_MODULES = ['dingdianxiaoshuo.spiders']
NEWSPIDER_MODULE = 'dingdianxiaoshuo.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'dingdianxiaoshuo (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
DOWNLOAD_DELAY = 0.25
#CLOSESPIDER_TIMEOUT = 60 # 后结束爬虫
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# Enable or disable spider middlewares
# See https://doc.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'dingdianxiaoshuo.middlewares.DingdianxiaoshuoSpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'dingdianxiaoshuo.middlewares.DingdianxiaoshuoDownloaderMiddleware': 543,
#}
# Enable or disable extensions
# See https://doc.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'dingdianxiaoshuo.pipelines.DingdianxiaoshuoPipeline': 300,
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5pipeline.py
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
#因为爬取整个网站时间较长,这里为了实现断点续传,我们把每个小说下载完成的
#章节地址存入数据库一个单独的集合里,记录已完成抓取的小说章节
from pymongo import MongoClient
from urllib import request
from bs4 import BeautifulSoup
#在pipeline中我们将实现下载每个小说,存入MongoDB数据库
class DingdianxiaoshuoPipeline(object):
def process_item(self, item, spider):
#print("马衍硕")
#如果获取章节链接进行如下操作
if "novel_section_urls" in item:
# 获取Mongodb链接
client = MongoClient("mongodb://127.0.0.1:27017")
#连接数据库
db =client.dingdian
#获取小说名称
novel_name=item['novel_name']
#根据小说名字,使用集合,没有则创建
novel=db[novel_name]
#使用记录已抓取网页的集合,没有则创建
section_url_downloaded_collection=db.section_url_collection
index=0
print("正在下载:"+item["novel_name"])
#根据小说每个章节的地址,下载小说各个章节
for section_url in item['novel_section_urls']:
#根据对应关系,找出章节名称
section_name=item["section_url_And_section_name"][section_url]
#如果将要下载的小说章节没有在section_url_collection集合中,也就是从未下载过,执行下载
#否则跳过
if not section_url_downloaded_collection.find_one({"url":section_url}):
#使用urllib库获取网页HTML
response = request.Request(url=section_url)
download_response = request.urlopen(response)
download_html = download_response.read().decode('utf-8')
#利用BeautifulSoup对HTML进行处理,截取小说内容
soup_texts = BeautifulSoup(download_html, 'lxml')
content=soup_texts.find("dd",attrs={"id":"contents"}).getText()
#向Mongodb数据库插入下载完的小说章节内容
novel.insert({"novel_name": item['novel_name'], "novel_family": item['novel_family'],
"novel_author":item['novel_author'], "novel_status":item['novel_status'],
"section_name":section_name,
"content": content})
index+=1
#下载完成,则将章节地址存入section_url_downloaded_collection集合
section_url_downloaded_collection.insert({"url":section_url})
print("下载完成:"+item['novel_name'])
return item
三、启动项目,查看运行结果:
程序编写完成后,我们进入项目所在目录,键入命令启动项目:
scrapy crawl dingdian 启动项目后,我们通过Mongodb可视化工具–RoBo看到,我们成功爬取了小说网站,接下来的问题交给时间。