Hadoop-2.7.5 + Spark-2.2.0分布式集群搭建过程(1)
文章目录
- 前提条件:
- 一、 Java下载与安装配置
- 1.1 Java下载
- 1.2 Java安装:
- 1.3 其他服务器的Java安装
- 二、SSH安装及设置
- 2.1 安装并验证 SSH
- 2.2 设置 ssh 免密登录
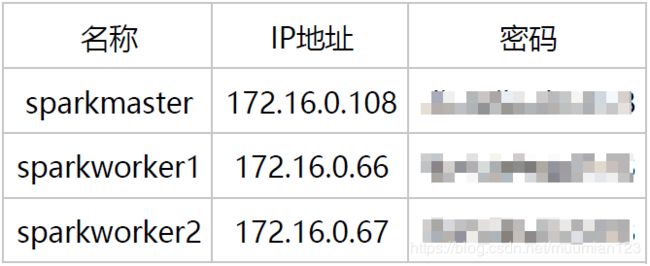
- 三、设置主机名和IP地址的对应关系
- 3.1 修改主机名称
- 3.2 配置host
- 3.3 三台服务器间SSH免密登陆
- 四、Rsync 安装配置
- 五、搭建Hadoop集群
- 5.1.hadoop安装配置
- 5.1.1 安装HADOOP
- 5.1.2.配置HADOOP单机版本
- 5.2 部署hadoop分布式集群
- 5.2.1 创建路径
- 5.2.2 配置集群
前提条件:
在同一局域网下使用SecureCRT对其中一台服务器进行连接并实现远程操控。
一、 Java下载与安装配置
1.1 Java下载
(鼠标右键粘贴,左键复制,Tab键自动补全)
wget http://download.oracle.com/otn-pub/java/jdk/8u162-b12/0da788060d494f5095bf8624735fa2f1/jdk-8u162-linux-x64.tar.gz
1.2 Java安装:
- 创建新目录:mkdir /home/uestc/bin/java(cd -:返回上级目录;cd~:返回根目录;ls:查看当前目录下内容;pwd:显示当前位置)

- 将下载的JDK移动至新建文件夹中:mv 文件所在目录/文件名 /新建目录
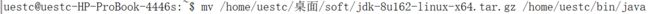
- 解压文件夹:tar -xvf jdk-8u162-linux-x64.tar.gz
- 配置Java:
# a. 修改环境变量:
sudo vim ~/.bashrc(针对个人用户则配置bashrc,全局则配置/etc/profile)
# b. 在末尾添加:
export JAVA_HOME=/home/uestc/bin/java/jdk1.8.0_162
export JRE_HOME=${JAVA_HOME}/jre
export CLASS_PATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
# c. 保存退出后使配置文件生效:
source ~/.bashrc
- 检测JAVA:
java –version
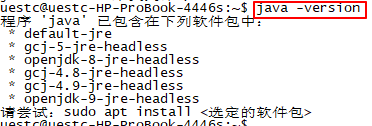
在出现提示“尝试:sudo apt install <选定的软件包>”时输入以下语句:
uestc@sparkmaster:~$ sudo apt install gcj-5-jre-headless
另外,删除自带 openjdk 的指令为:sudo apt-get remove openjdk*,最终结果应如下图所示:

1.3 其他服务器的Java安装
运用 scp 命令在 sparkworker1 和 sparkworker2 上安装 JDK 并采用上面相同的方式进行配置环境和检测:
scp -r [email protected]:/home/uestc/bin/java /home/uestc/bin/java
此为确保后期其他服务器配置 Scala 时 Java 环境正确。
二、SSH安装及设置
Hadoop 是采用 ssh 进行通信的,此时我们要设置密码为空,即不需要密码登录,这样免去每次通信时都输入密码。
2.1 安装并验证 SSH
- 安装ssh:
sudo apt-get install ssh - 启动ssh服务:
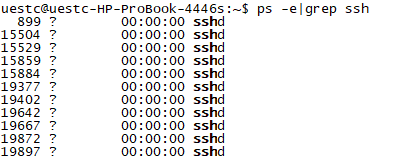
/etc/init.d/ssh start - 验证服务是否正常启动:
ps -e |grep ssh
2.2 设置 ssh 免密登录
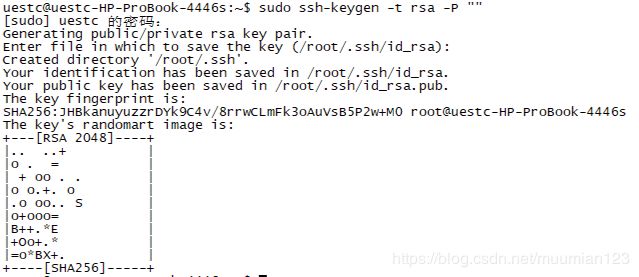
- 设置免密登录,生成私钥和公钥:
ssh-keygen -t rsa
(需要针对用户uestc进行操作,否则会默认生成根目录在root里面,用户uestc会没有访问权限)


- 追加公钥:
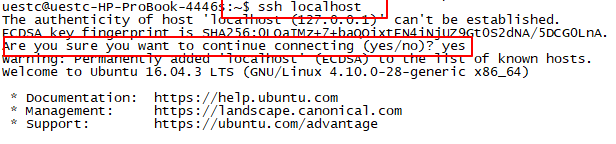
cat ~/.ssh/• id_rsa.pub >> ~/.ssh/authorized_keys - 验证免密登录:
ssh localhost(Are you sure you want to continue connecting (yes/no)?时输入 yes)
三、设置主机名和IP地址的对应关系
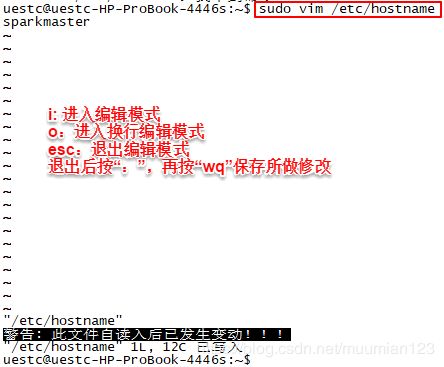
3.1 修改主机名称
sudo vim /etc/hostname
3.2 配置host
在“/etc/hosts”中把三台机器分别设置为sparkmaster、sparkworker1、sparkworker2
sudo vim hosts

- 重启使得更改生效:
reboot
- 保存退出之后ping一下主机名和IP地址验证转换关系是否正确(ping一下主机名和IP地址验证转换关系是否正确)
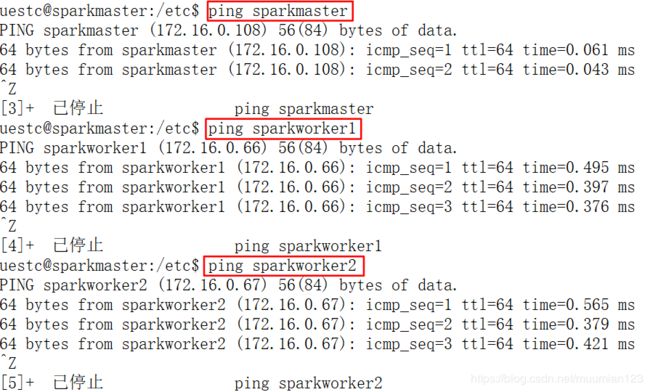
3.3 三台服务器间SSH免密登陆
注意:公钥保存在/home/uestc/.ssh文件夹中
用ssh-copy-id将公钥复制到远程机器中:ssh-copy-id [-i [identity_file]] [user@]machine
- 把 sparkmaster 的公钥发到 slaveworkers 上
- ssh-copy-id - i ./id_rsa.pub [email protected] 并输入 ssh ‘[email protected]’ 验证
- ssh-copy-id -i ./id_rsa.pub [email protected] 并输入 ssh ‘[email protected]’ 验证
- 把 sparkwork1 的公钥发到 sparkwork2 和 master 上
- ssh-copy-id -i ./id_rsa.pub [email protected] 并输入 ssh ‘[email protected]’ 验证
- ssh-copy-id -i ./id_rsa.pub [email protected] 并输入 ssh ‘[email protected]’ 验证
- 把 sparkwork2 的公钥发到 sparkwork1 和 master 上
- ssh-copy-id -i ./id_rsa.pub [email protected] 并输入 ssh ‘[email protected]’ 验证
- ssh-copy-id -i ./id_rsa.pub [email protected] 并输入 ssh ‘[email protected]’ 验证
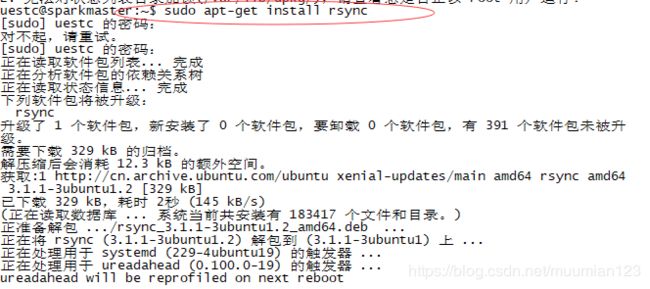
四、Rsync 安装配置
Ubuntu 默认安装了 rsync,可以通过以下命令来安装或更新 rsync:
apt-get install rsync
五、搭建Hadoop集群
5.1.hadoop安装配置
5.1.1 安装HADOOP
- 创建hadoop目录:
mkdir /home/uestc/bin/hadoop - 解压hadoop-2.7.5.tar.gz到刚创建的目录中:
tar -xvf ./hadoop-2.7.5.tar.gz /home/uestc/bin/hadoop
5.1.2.配置HADOOP单机版本
- 在hadoop-env.sh中配置java安装信息
# 1. 进入配置文件的目录:
cd /home/uestc/bin/hadoop/hadoop-2.7.5/etc/hadoop
# 2. 编辑hadoop-env.sh文件:
sudo vim ./hadoop-env.sh
# 添加以下内容:
export JAVA_HOME=/home/uestc/bin/java/jdk1.8.0_162
# 3. 使用source命令使hadoop-env.sh配置信息生效:source ./hadoop-env.sh
- 把hadoop加入环境变量:
sudo vim ~/.bashrc
# 添加以下内容:
export JAVA_HOME=/home/uestc/bin/java/jdk1.8.0_162
export JRE_HOME=${JAVA_HOME}/jre
export CLASS_PATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:/home/uestc/bin/hadoop/hadoop-2.7.5/bin:$PATH
# 使用source命令使hadoop-env.sh配置信息生效:
source ~/.bashrc
- 验证版本信息:hadoop version:

5.2 部署hadoop分布式集群
5.2.1 创建路径
- 分别创建以下路径
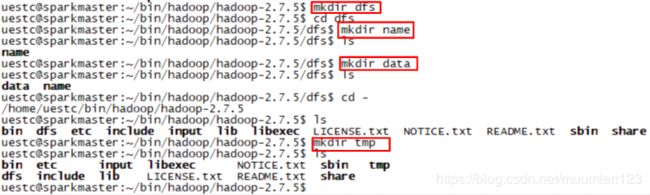
5.2.2 配置集群
进入hadoop配置文件区修改hadoop的配置文件
- 修改配置文件 hadoop-env.sh,在其中加入“JAVA_HOME”(前面已经配置了就可以忽略此步骤):
vim hadoop-env.sh

- 修改配置文件yarn-env.sh,在其中加入“JAVA_HOME”:
vim yarn-env.sh
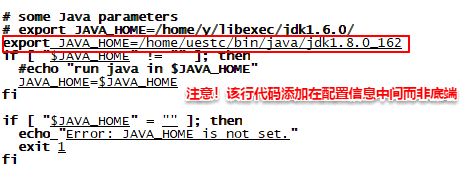
更改完之后输入source ./yarn-env.sh使得配置立刻生效。 - 修改配置文件 mapred-env.sh,在其中加入“JAVA_HOME”:
vim mapred-env.sh
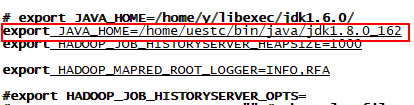
更改完之后输入source mapred-env.sh使得配置立刻生效。 - 修改配置文件 slaves(我们设置hadoop集群中的从节点为sparkworker1和sparkworker2):
vim slaves

- 修改配置文件core-site.xml:
vim core-site.xml,并添加以下内容:
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://sparkmaster:9000/value>
<description>The name of the default file systemdescription>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/home/uestc/bin/hadoop/hadoop-2.7.5/tmpvalue>
<description>A base for other temporary directoriesdescription>
property>
configuration>
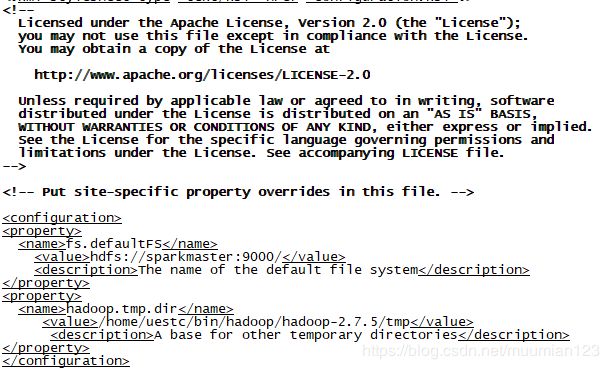
上述是core-site.xml文件的最小化配置。
- 修改配置文件hdfs-site.xml:
vim hdfs-site.xml,并添加以下内容:
<configuration>
<property>
<name>dfs.replicationname>
<value>2value>
<description>The number of dfs replicationdescription>
property>
<property>
<name>dfs.namenode.name.dirname>
<value>/home/uestc/bin/hadoop/hadoop-2.7.5/dfs/namevalue>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>/home/uestc/bin/hadoop/hadoop-2.7.5/dfs/datavalue>
property>
configuration>
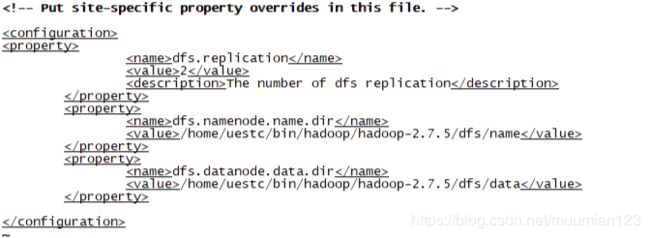
上述是hdfs-site.xml文件的最小化配置。
- 修改配置文件mapred-site.xml
拷贝一份 mapred-site.xml.template 命名为 mapred-site.xml:cp ./mapredsite.xml.template ./mapred-site.xml

并添加以下内容:
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
configuration>
上述是mapred-site.xml文件的最小化配置。
- 修改配置文件 yarn-site.xml:
vim yarn-site.xml,添加以下内容:
<configuration>
<property>
<name>yarn.resourcemanager.hostnamename>
<value>sparkmastervalue>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
configuration>
上述是yarn-site.xml文件的最小化配置。
- 在sparkworker1 和 sparkworker2 上完成和sparkmster同样的Hadoop操作,建议使用SCP命令把 sparkmaster 上安装和配置的java 以及 hadoop 的各项内容分别拷贝到 sparkworker1 和 sparkworker2 上:
- 移动 java 和 hadoop 到 sparkworker1 上:
# 移动java:
scp -r [email protected]:/home/uestc/bin/java /home/uestc/bin/java
vim ~/.bashrc
# 加入
export JAVA_HOME=/home/carifi/uestc/bin/java/jdk1.8.0_162
export JRE_HOME=${JAVA_HOME}/jre
export CLASS_PATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
# 生效
source ~/.bashrc
# 移动hadoop:
scp -r [email protected]:/home/uestc/bin/hadoop/ /home/uestc/bin/hadoop
- 移动 java 和 hadoop 到 sparkworker2 上:
# 移动java:
scp -r [email protected]:/home/uestc/bin/java /home/uestc/bin/java
vim /etc/profile
# 加入
export JAVA_HOME=/home/uestc/bin/java/jdk1.8.0_162
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export HADOOP_HOME=/home/uesct/bin/hadoop/hadoop-2.7.5
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
# 生效
source /etc/profile
# 移动hadoop:
scp -r [email protected]:/home/uestc/bin/hadoop/ /home/uestc/bin/hadoop