HoloLens原理分析和硬件拆解
不同于Google Glass等AR产品只能在固定位置显示一个虚拟屏幕,HoloLens能把全息影像和真实环境杂糅在一起,使全息影像像真实物体一样摆放在一个固定位置,并且能像真实物体在视觉上一样近大远小、相互遮挡,让人感觉全息影像就是真实世界的一部分。而要实现这些功能,HoloLens需要判断全息影像相对于自身以及现实空间的相对位置,这就面临着两个问题:我在哪(定位)和我周围有什么(三维环境重建)。定位与三维重建问题,其实就是SLAM问题(SimultaneousLocalization and Mapping,中文名为即时定位与地图重建)。
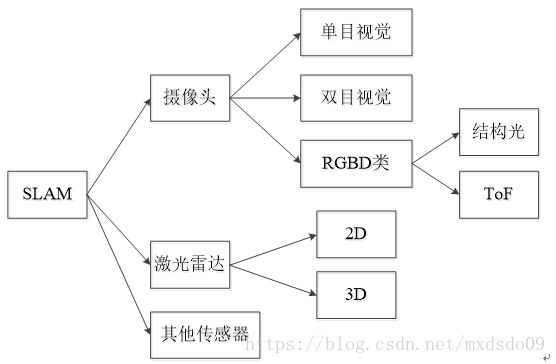
图2.7 主要的SLAM体系
而SLAM中传统的获取深度的方法主要有三种:基于视差原理的双目视觉方法;将光通过编码的方式射出打在物体上,由于编码光打在不同物体上的畸变程度不同,从而推断出物体立体信息的结构光方法;通过对光发射到物体表面并反射回来的时间差计算出物体距离的ToF(Time-of-Flight)方法。
HoloLens使用环境感知摄像头捕获真实环境图像并从中提取特征点,之后匹配相邻帧图像的特征点,通过特征点相对位置的变化来反向推出HoloLens转动的角度和产生的位移,从而计算出HoloLens的运动。
图2.8 配相邻帧图像的特征点
由于采用单目视觉或者双目视觉来获取场景每个像素点的深度信息的计算量相当大,并不能在较短的时间内完成,会直接影响HoloLens的三维重建的实时性,所以HoloLens另配有深度摄像头(景深摄像头)。HoloLens的深度头是基于ToF原理,可通过计算从投射红外线脉冲到其反射回来的时间与光速的乘积直接获得场景的深度信息。
在深度相机采集的深度信息后,HoloLens利用的是Richard Newcombe发明的Kinect Fusion理论来对真实环境进行三维重建。Kinect Fusion的原理为利用深度相机采集的深度信息对三维重建的刻画,可以类比为雕塑,对一个完整的立方体利用其深度信息进行不断的雕刻完善。通过在不同角度获取的深度信息,在不同的角度雕刻立方体使之成为我们想要的样子,完成三维重建。
图2.9 Kinect Fusion原理(来自 MicrosoftDeveloper Network)
a)将景深摄像头采集的深度信息转换为三维点云,并计算每一个点的法向量。
b)HoloLens的定位定姿。Kinect Fusion算法是通过计算当前三维点云和和由现有模型生成的预测三维点云进行ICP匹配,从而得到当前位姿。HoloLens的深度摄像头是基于ToF原理的,其采集的深度信息精度并不高,若是由此来计算HoloLens位置会使得误差较大,可能会导致全息影像不能稳定的固定在空间中。故HoloLens使用更为准确的环境感知摄像头来定位,IMU中的陀螺仪来定姿,完成这个步骤。
c)将点云数据依据HoloLens位姿融合到场景的三维模型中。
d)利用光线投影算法根据当前帧HoloLens位姿和现有模型预测当前帧对应的环境点云,并将其提供给b进行ICP匹配。
在HoloLens不断改变位姿的同时不断的通过环境感知摄像头和景深摄像头获取周围环境在不同视角下的点云,不断循环的过程完成三维场景重建。然而以目前的技术,还不能把空间建模做得很完美,实际的三维重建模型会有许多不平整、不连续、有孔洞甚至支离破碎的情况。
图2.10三维重建情况(a) 图2.11三维重建情况(b)
HoloLens的可佩带性决定了其体积和重量都不可能太大,在相当程度上限制了其计算能力和功耗,这也使得HoloLens无法以特别实时的方式不断更新三维重建。通常在对真实世界有了新的扫描信息输入时,三维重建才会以几秒一次的频率进行更新。假如HoloLens放置在一个比较固定的位置,在一开始生成三维重建时有个运动的物体经过,那么生成的三维重建在很长的时间里,都会有一串不规则的网格在物体运动的轨迹上。