一、常用术语
索引(Index)、类型(Type)、文档(Document)
- 索引Index是含有相同属性的文档集合。索引在ES中是通过一个名字来识别的,且必须是英文字母小写,且不含中划线(-);可类比于 MySQL 中的 database ;在 7.0中,由于类型(Type)的移除,我们可以理解为,一个索引就是一张 table。
- 一个索引中可以定义一个或多个类型Type,文档必须属于一个类型;可类比于 MySQL 中的 table;
- 文档Document是可以被索引的基本数据单位。文档是Elasticsearch中最小的数据存储单位。可类比于 MySQL 中 一个table 中的一行记录
注意事项:
从ES6.0开始,官方便不建议一个索引中创建多个类型;在ES7.0中,更是移除了类型(Type)这个概念。为什么呢?
在Elasticsearch索引中,不同类型(Type)中具有相同名称的字段在内部由相同的Lucene字段支持。一个index中多个Type在Lucene中会有许多问题。具体的可以参考官方说明:Removal of mapping types
节点Node、集群Cluster
- 节点:一个ES运行实例,是集群的的构成单元
- 集群:由1个(只有1个节点也是1个集群)或多个节点组成,对外提供服务
分片Shard(集群—提高吞吐与计算性能)、副本Replica(主从—提高可用性)
- 在ES中,每个索引都有多个分片,每个分片都是一个Lucene索引。假设一个索引的数据量很大,就会造成硬盘压力很大,同时,搜索速度也会出现瓶颈。我们可以将一个索引分为多个分片,从而分摊压力;分片同时还允许用户进行水平地扩展和拆分,以及分布式的操作,可以提高搜索以及其他操作的效率。
- 拷贝一份分片,就完成了分片的备份。备份的好处是,当一个主分片出现问题时,备份的分片就能代替工作,从而提高了ES的可用性。同时,备份的分片还可以执行搜索操作,以分摊搜索的压力。ES禁止同一个分片的主分片和副本分片在同一个节点上。
RESTful API
Elasticsearch 集群对外提供 RESTful API
- REST - REpresentational State Transfer
- URI 指定资源,如Index、Document等
- Http Method 指明资源操作类型,如GET、POST、PUT、DELETE等
倒排索引
-
正排索引
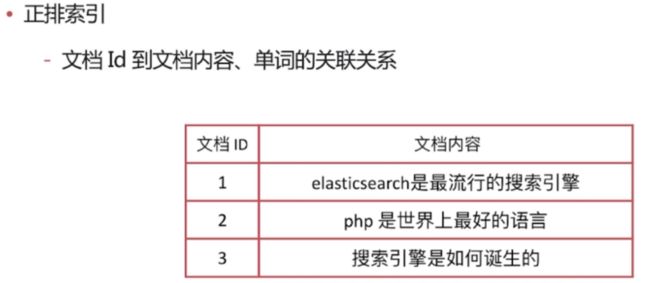 正排索引
正排索引


倒排索引组成
倒排索引是搜索引擎的核心,主要包含两部分:
- 单词词典(Term Dictionary)
- 记录所有文档的单词,一般都比较大
- 记录单词到倒排列表的关联信息
- 单词字典的实现一般是用B+Tree,能兼顾内存与磁盘性能,保障增删改查高效
- 倒排列表(Posting List)
- 倒排列表(Posting List)记录了单词对应的文档集合,由倒排索引项(Posting)组成
- 倒排索引项(Posting)主要包含如下信息:
- 文档ld,用于获取原始信息
- 单词频率(TF,Term Frequency),记录该单词在该文档中的出现次数,用于后续相关性算分
- 位置(Position),记录单词在文档中的分词位置(多个),用于做词语搜索(Phrase Query)
- 偏移(Offset),记录单词在文档的开始和结束位置,用于做高亮显示
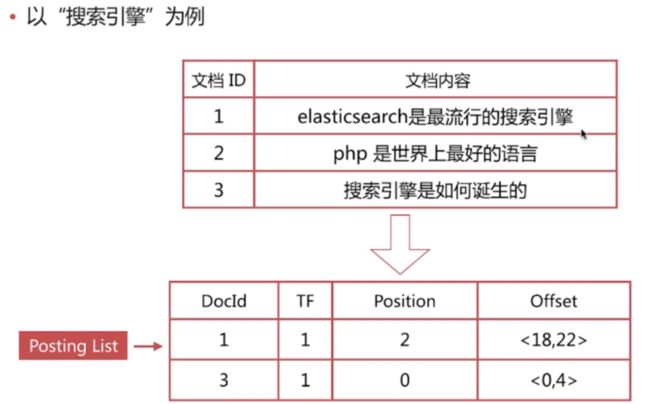
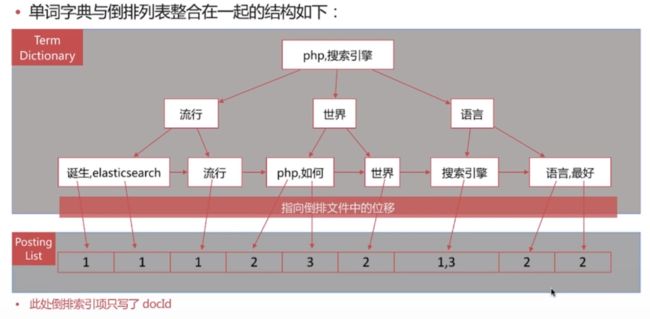
ES中的倒排索引
es存储的是一个json格式的文档,其中包含多个字段,每个字段会有自己的倒排索引。

相关性算分
相关性算分是指文档与查询语句间的相关度,英文为 relevance
- 通过倒排索引可以获取与查询语句相匹配的文档列表,那么如何将最符合用户查询需求的文档放到前列呢?
- 本质是一个排序问题,排序的依据是相关性算分
相关性算分的几个重要概念
- Term Frequency(TF)词频,即单词在该文档中出现的次数。词频越高,相关度越高
- Document Frequency(DF)文档频率,即单词出现的文档数
- Inverse Document Frequency(IDF)逆向文档频率,与文档频率相反,简单理解为1/DF。即单词出现的文档数越少,相关度越高
- Field-length Norm 文档越短,相关性越高
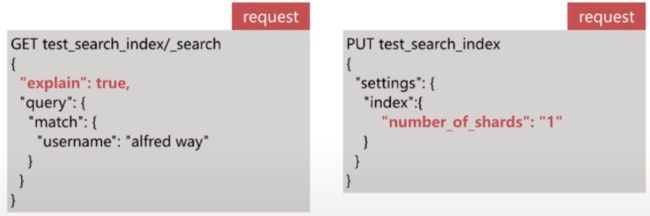
使用 explain 参数查看具体的计算方法
- es的算分是按照shard进行的,即shard的分数计算是相互独立的,所以在使用explain的时候注意分片数
-
可以通过设置索引的分片数为1来避免这个问题
ES中的相关性算分模型
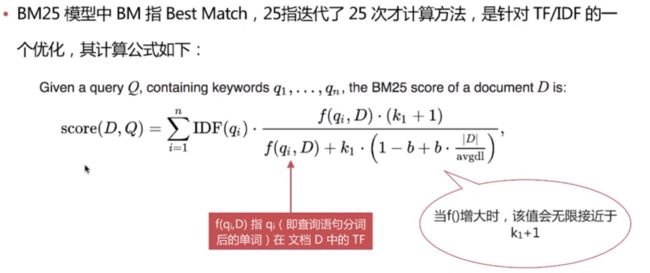
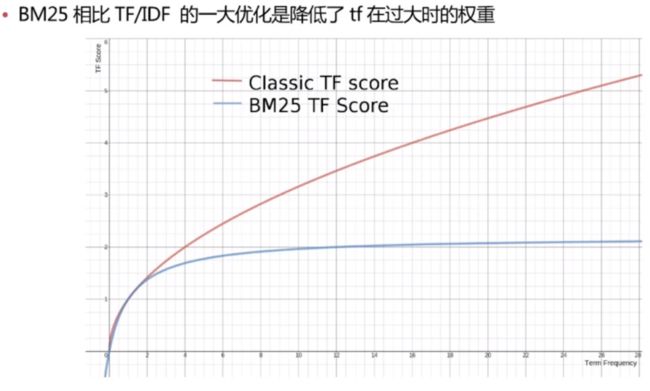
- TF/IDF 模型
- BM25 模型5.x之后的默认模型
TF/IDF 模型

BM25 模型
二、Document API
1. 文档是一个Json Object,由字段(Field)组成,常见数据类型如下:
- 字符串:text,keyword(不分词)
- 数值型:long,integer,short byte,double,float,half float,scaled_float
- 布尔:boolean
- 日期:date
- 二进制:binary
- 范围类型:integer_range,float_range,long_range,double_range,date_range
2. 文档元数据,用于标注文档的相关信息
- _index:文档所在的索引名
- _type:文档所在的类型名(7.0后默认_doc)
- _id:文档唯一id
- _uid:组合id,由_type和_id组成(6.x_type不再起作用,因此同_id值一样),默认禁用
- _source:文档的原始Json数据,可以从这里获取每个字段的内容
- _all:整合所有字段内容到该字段,默认禁用
3. 每个文档有唯一的_Id标识
- 自行指定
- es自动生成
4. 文档API
- es有专门的Document API,创建文档,查询文档,更新文档,删除文档
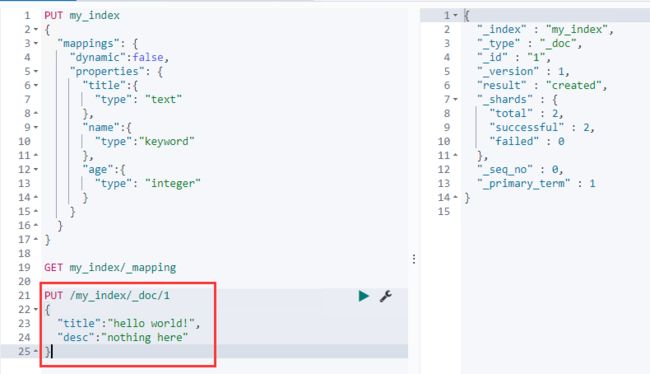
创建文档(创建文档时,如果索引不存在,es会自动创建对应的index和type)
- 指定id创建文档
PUT /test_index/_doc/1
{
"username":"zhangsan",
"age":1
}
- 不指定id创建文档
POST /test_index/_doc
{
"username":"lisi",
"sex":2
}
查询文档
- 指定要查询的文档id
GET /test_index/_doc/1

- 搜索所有文档,用到_search
GET /test_index/_search # GET /test_index/_doc/_search在高版本提示类型已过期,因此不用指定type了

批量增删改查文档
- ES允许一次创建多个文档,从而减少网络传输开销,提升写入速率,endpoint为_bulk
- index 用于创建文档,文档已存在则更细文档
- create 同样可以创建文档,文档已存在则返回错误
- delete 用于删除文档
- update 用于更新文档,文档不存在则返回错误
- 在es6.0之后的版本可以省略_type,官方已舍弃_type这个概念
POST _bulk
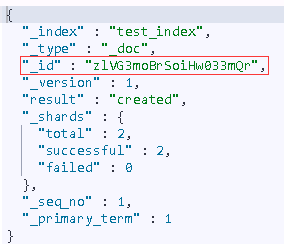
{"index":{"_index":"test_index","_id":"3"}}
{"username":"alfred","age":10}
{"create":{"_index":"test_index","_id":"3"}}
{"username":"alfred2","age":110}
{"delete":{"_index":"test_index","_id":"1"}}
{"update":{"_id":"2","_index":"test_index"}}
{"doc":{"age":"20"}}
返回:
{
"took" : 18,
"errors" : true,
"items" : [
{
"index" : {
"_index" : "test_index",
"_type" : "_doc",
"_id" : "3",
"_version" : 2,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 2,
"failed" : 0
},
"_seq_no" : 4,
"_primary_term" : 1,
"status" : 200
}
},
{
"create" : {
"_index" : "test_index",
"_type" : "_doc",
"_id" : "3",
"status" : 409,
"error" : {
"type" : "version_conflict_engine_exception",
"reason" : "[3]: version conflict, document already exists (current version [2])",
"index_uuid" : "jjJIqT7QSeaYcOeWxxY-og",
"shard" : "0",
"index" : "test_index"
}
}
},
{
"delete" : {
"_index" : "test_index",
"_type" : "_doc",
"_id" : "1",
"_version" : 3,
"result" : "not_found",
"_shards" : {
"total" : 2,
"successful" : 2,
"failed" : 0
},
"_seq_no" : 5,
"_primary_term" : 1,
"status" : 404
}
},
{
"update" : {
"_index" : "test_index",
"_type" : "_doc",
"_id" : "2",
"status" : 404,
"error" : {
"type" : "document_missing_exception",
"reason" : "[_doc][2]: document missing",
"index_uuid" : "jjJIqT7QSeaYcOeWxxY-og",
"shard" : "0",
"index" : "test_index"
}
}
}
]
}
批量查询文档[跨索引]
- es允许一次查询多个索引的文档,endpoint为_mget
GET /_mget
{
"docs": [
{
"_index": "test_index",
"_id": 1
},
{
"_index": "test_index2",
"_id": 1
}
]
}
返回
{
"docs" : [
{
"_index" : "test_index",
"_type" : "_doc",
"_id" : "1",
"found" : false
},
{
"_index" : "test_index2",
"_type" : null,
"_id" : "1",
"error" : {
"root_cause" : [
{
"type" : "index_not_found_exception",
"reason" : "no such index [test_index2]",
"resource.type" : "index_expression",
"resource.id" : "test_index2",
"index_uuid" : "_na_",
"index" : "test_index2"
}
],
"type" : "index_not_found_exception",
"reason" : "no such index [test_index2]",
"resource.type" : "index_expression",
"resource.id" : "test_index2",
"index_uuid" : "_na_",
"index" : "test_index2"
}
}
]
}
三、Indices APIs
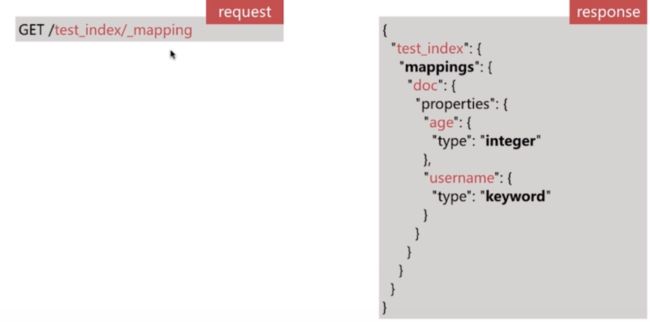
1. 索引中一般存储具有相同结构的文档(Document)
- 每个索引都有自己的mapping定义,用于定义字段名和类型
- 创建索引不定义mapping,es将自动根据插入的数据定义mapping,但是通常不建议这样做,mapping相当于数据库建表时的表结构定义
- 1个索引中可以存储不同结构的文档,但在6.0后type的舍弃,官方建议1个index存储1中结构的文档
2. 一个集群(只有1个节点也是1个集群)可以有多个索引,比如:nginx 日志存储的时候可以按照日期每天生成一个索引来存储
- nginx-log-2017-01-01
- nginx-log-2017-01-02
- nginx-log-2017-01-03
3. 索引API
- es有专门的IndexAPI,用于查询、创建、更新、删除索引配置等
创建索引
PUT /test_index

查看所有索引
GET /_cat/indices
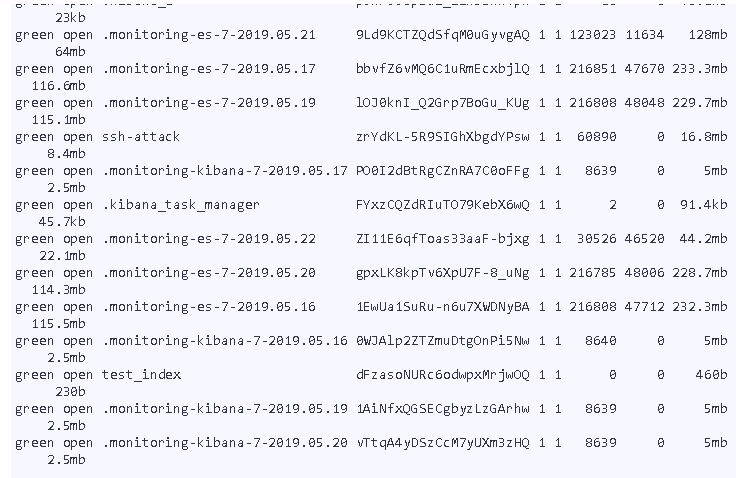
删除索引
DELETE /test_index
4. 索引模板
索引模板,英文为Index Template,主要用于在新建索引时自动应用预先设定的配置,简化索引创建的操作步骤
- 可以设定索引的配置和mapping
- 可以有多个模板,当创建的索引匹配到多个模板时,根据order设置,order大的覆盖小的配置
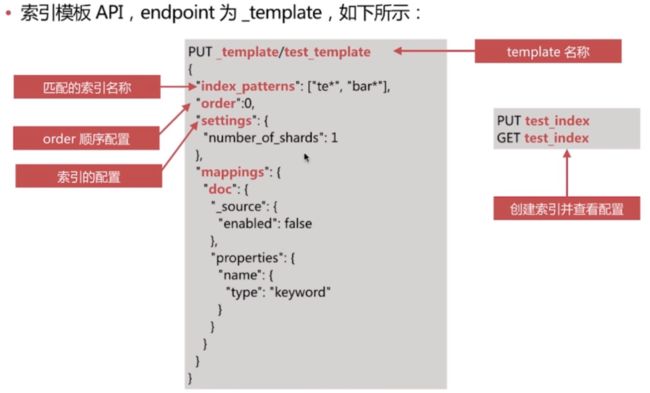
- 查看所有索引模板
- GET /_template
- 查看指定名称的索引模板
- GET /_template/test_template
- 删除指定名称的索引模板
- DELETE /_template/test_template
四、Analysis
分词是指将文本转换成一系列单词(term or token)的过程,也可以叫做文本分析,在es 里面称为Analysis,如下图所示:

在es中,分词会在如下两个时机使用:
-
创建或更新文档时,也称索引时(Index Time),会对相应的文档进行分词处理
 索引时分词
索引时分词 -
查询时(Search Time),会对查询语句进行分词
 查询时分词
查询时分词
一般不需要特别指定查询时分词器,直接使用索引时分词器即可(此时查询也会默认使用索引时分词器)
分词的使用建议:
- 明确字段是否需要分词,不需要分词的字段就将type设置为keyword,可以节省空间和提高写性能
- 善用_analyze API,查看文档的具体分词结果
- 动手测试
1. 分词器组成
分词器是es中专门处理分词的组件,英文为Analyzer,它的组成如下:
- Character Filters
- 针对原始文本进行处理,比如去除html特殊标记符
- Tokenizer
- 将原始文本按照一定规则切分为单词
- Token Filters
- 针对tokenizer处理的单词就行再加工,比如转小写、删除或新增等处理
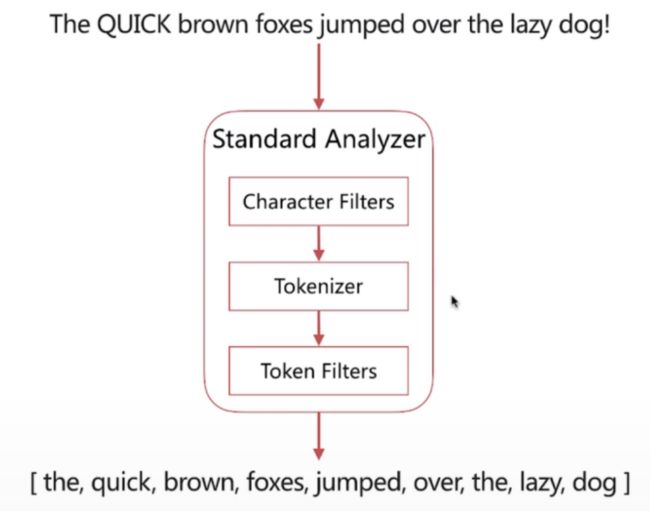
2. es内置的分词器
es 自带如下的分词器:
- Standard
- Simple
- Whitespace
- Stop
- Keyword
- Pattern
- Language
Standard Analyzer
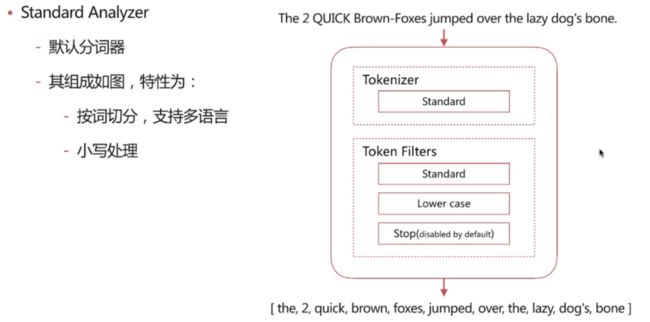
POST _analyze
{
"analyzer":"standard",
"text":"The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}
分词结果:
{
"tokens" : [
{
"token" : "the",
"start_offset" : 0,
"end_offset" : 3,
"type" : "",
"position" : 0
},
{
"token" : "2",
"start_offset" : 4,
"end_offset" : 5,
"type" : "",
"position" : 1
},
{
"token" : "quick",
"start_offset" : 6,
"end_offset" : 11,
"type" : "",
"position" : 2
},
{
"token" : "brown",
"start_offset" : 12,
"end_offset" : 17,
"type" : "",
"position" : 3
},
{
"token" : "foxes",
"start_offset" : 18,
"end_offset" : 23,
"type" : "",
"position" : 4
},
{
"token" : "jumped",
"start_offset" : 24,
"end_offset" : 30,
"type" : "",
"position" : 5
},
{
"token" : "over",
"start_offset" : 31,
"end_offset" : 35,
"type" : "",
"position" : 6
},
{
"token" : "the",
"start_offset" : 36,
"end_offset" : 39,
"type" : "",
"position" : 7
},
{
"token" : "lazy",
"start_offset" : 40,
"end_offset" : 44,
"type" : "",
"position" : 8
},
{
"token" : "dog's",
"start_offset" : 45,
"end_offset" : 50,
"type" : "",
"position" : 9
},
{
"token" : "bone",
"start_offset" : 51,
"end_offset" : 55,
"type" : "",
"position" : 10
}
]
}
Simple Analyzer
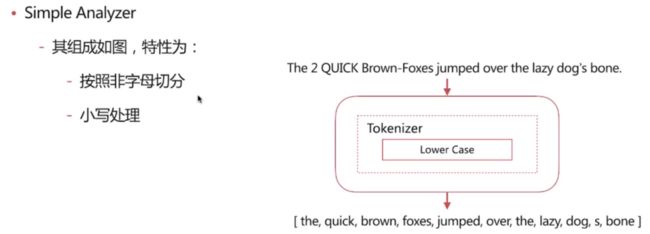
POST _analyze
{
"analyzer":"simple",
"text":"The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}
分词结果:
{
"tokens" : [
{
"token" : "the",
"start_offset" : 0,
"end_offset" : 3,
"type" : "word",
"position" : 0
},
{
"token" : "quick",
"start_offset" : 6,
"end_offset" : 11,
"type" : "word",
"position" : 1
},
{
"token" : "brown",
"start_offset" : 12,
"end_offset" : 17,
"type" : "word",
"position" : 2
},
{
"token" : "foxes",
"start_offset" : 18,
"end_offset" : 23,
"type" : "word",
"position" : 3
},
{
"token" : "jumped",
"start_offset" : 24,
"end_offset" : 30,
"type" : "word",
"position" : 4
},
{
"token" : "over",
"start_offset" : 31,
"end_offset" : 35,
"type" : "word",
"position" : 5
},
{
"token" : "the",
"start_offset" : 36,
"end_offset" : 39,
"type" : "word",
"position" : 6
},
{
"token" : "lazy",
"start_offset" : 40,
"end_offset" : 44,
"type" : "word",
"position" : 7
},
{
"token" : "dog",
"start_offset" : 45,
"end_offset" : 48,
"type" : "word",
"position" : 8
},
{
"token" : "s",
"start_offset" : 49,
"end_offset" : 50,
"type" : "word",
"position" : 9
},
{
"token" : "bone",
"start_offset" : 51,
"end_offset" : 55,
"type" : "word",
"position" : 10
}
]
}
Whitespace Analyzer
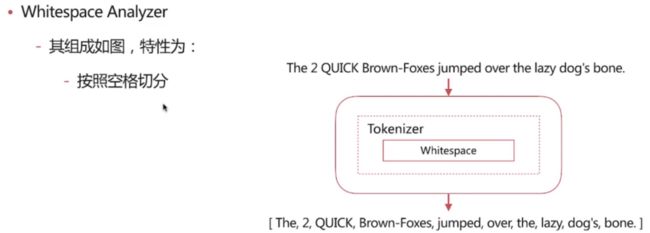
POST _analyze
{
"analyzer":"whitespace",
"text":"The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}
分词结果:
{
"tokens" : [
{
"token" : "The",
"start_offset" : 0,
"end_offset" : 3,
"type" : "word",
"position" : 0
},
{
"token" : "2",
"start_offset" : 4,
"end_offset" : 5,
"type" : "word",
"position" : 1
},
{
"token" : "QUICK",
"start_offset" : 6,
"end_offset" : 11,
"type" : "word",
"position" : 2
},
{
"token" : "Brown-Foxes",
"start_offset" : 12,
"end_offset" : 23,
"type" : "word",
"position" : 3
},
{
"token" : "jumped",
"start_offset" : 24,
"end_offset" : 30,
"type" : "word",
"position" : 4
},
{
"token" : "over",
"start_offset" : 31,
"end_offset" : 35,
"type" : "word",
"position" : 5
},
{
"token" : "the",
"start_offset" : 36,
"end_offset" : 39,
"type" : "word",
"position" : 6
},
{
"token" : "lazy",
"start_offset" : 40,
"end_offset" : 44,
"type" : "word",
"position" : 7
},
{
"token" : "dog's",
"start_offset" : 45,
"end_offset" : 50,
"type" : "word",
"position" : 8
},
{
"token" : "bone.",
"start_offset" : 51,
"end_offset" : 56,
"type" : "word",
"position" : 9
}
]
}
Stop Analyzer
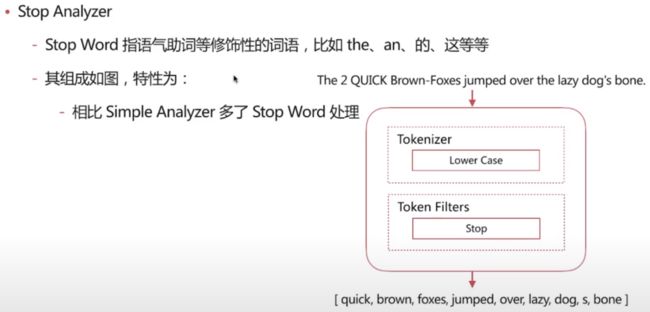
POST _analyze
{
"analyzer":"stop",
"text":"The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}
分词结果:
{
"tokens" : [
{
"token" : "quick",
"start_offset" : 6,
"end_offset" : 11,
"type" : "word",
"position" : 1
},
{
"token" : "brown",
"start_offset" : 12,
"end_offset" : 17,
"type" : "word",
"position" : 2
},
{
"token" : "foxes",
"start_offset" : 18,
"end_offset" : 23,
"type" : "word",
"position" : 3
},
{
"token" : "jumped",
"start_offset" : 24,
"end_offset" : 30,
"type" : "word",
"position" : 4
},
{
"token" : "over",
"start_offset" : 31,
"end_offset" : 35,
"type" : "word",
"position" : 5
},
{
"token" : "lazy",
"start_offset" : 40,
"end_offset" : 44,
"type" : "word",
"position" : 7
},
{
"token" : "dog",
"start_offset" : 45,
"end_offset" : 48,
"type" : "word",
"position" : 8
},
{
"token" : "s",
"start_offset" : 49,
"end_offset" : 50,
"type" : "word",
"position" : 9
},
{
"token" : "bone",
"start_offset" : 51,
"end_offset" : 55,
"type" : "word",
"position" : 10
}
]
}
Keyword Analyzer
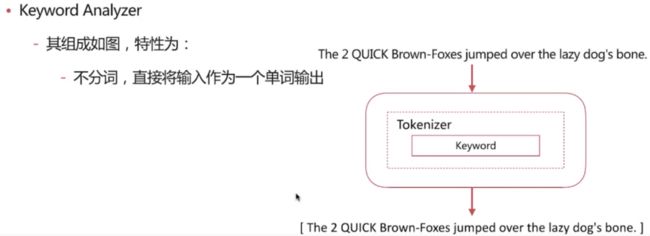
POST _analyze
{
"analyzer":"keyword",
"text":"The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}
分词结果:
{
"tokens" : [
{
"token" : "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone.",
"start_offset" : 0,
"end_offset" : 56,
"type" : "word",
"position" : 0
}
]
}
Pattern Analyzer
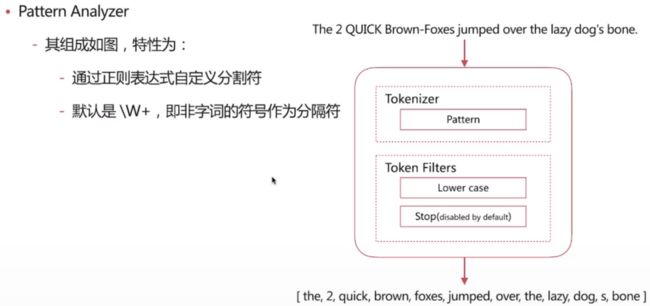
POST _analyze
{
"analyzer":"pattern",
"text":"The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}
分词结果:
{
"tokens" : [
{
"token" : "the",
"start_offset" : 0,
"end_offset" : 3,
"type" : "word",
"position" : 0
},
{
"token" : "2",
"start_offset" : 4,
"end_offset" : 5,
"type" : "word",
"position" : 1
},
{
"token" : "quick",
"start_offset" : 6,
"end_offset" : 11,
"type" : "word",
"position" : 2
},
{
"token" : "brown",
"start_offset" : 12,
"end_offset" : 17,
"type" : "word",
"position" : 3
},
{
"token" : "foxes",
"start_offset" : 18,
"end_offset" : 23,
"type" : "word",
"position" : 4
},
{
"token" : "jumped",
"start_offset" : 24,
"end_offset" : 30,
"type" : "word",
"position" : 5
},
{
"token" : "over",
"start_offset" : 31,
"end_offset" : 35,
"type" : "word",
"position" : 6
},
{
"token" : "the",
"start_offset" : 36,
"end_offset" : 39,
"type" : "word",
"position" : 7
},
{
"token" : "lazy",
"start_offset" : 40,
"end_offset" : 44,
"type" : "word",
"position" : 8
},
{
"token" : "dog",
"start_offset" : 45,
"end_offset" : 48,
"type" : "word",
"position" : 9
},
{
"token" : "s",
"start_offset" : 49,
"end_offset" : 50,
"type" : "word",
"position" : 10
},
{
"token" : "bone",
"start_offset" : 51,
"end_offset" : 55,
"type" : "word",
"position" : 11
}
]
}
Language Analyzer

3. 中文分词



4. Analyzer API
es提供了一个测试分词的api接口,方便验证分词效果,endpoint是_analyze:
- 可以直接指定 analyzer 进行测试
- 可以直接指定索引中的字段进行测试
- 可以自定义分词器进行测试
直接指定analyzer进行测试
POST /_analyze
{
"analyzer": "standard", # 分词器
"text":"Hello World!" # 测试文本
}
分词结果:
{
"tokens" : [
{
"token" : "hello", # 分词结果
"start_offset" : 0, # 开始偏移
"end_offset" : 5, # 结束偏移
"type" : "",
"position" : 0 # 分词位置
},
{
"token" : "world",
"start_offset" : 6,
"end_offset" : 11,
"type" : "",
"position" : 1
}
]
}
直接指定索引中的字段进行测试
POST /test_index/_analyze
{
"field": "username",
"text":"Hello World HA!"
}
分词结果:
{
"tokens" : [
{
"token" : "hello",
"start_offset" : 0,
"end_offset" : 5,
"type" : "",
"position" : 0
},
{
"token" : "world",
"start_offset" : 6,
"end_offset" : 11,
"type" : "",
"position" : 1
},
{
"token" : "ha",
"start_offset" : 12,
"end_offset" : 14,
"type" : "",
"position" : 2
}
]
}
自定义分词器进行测试
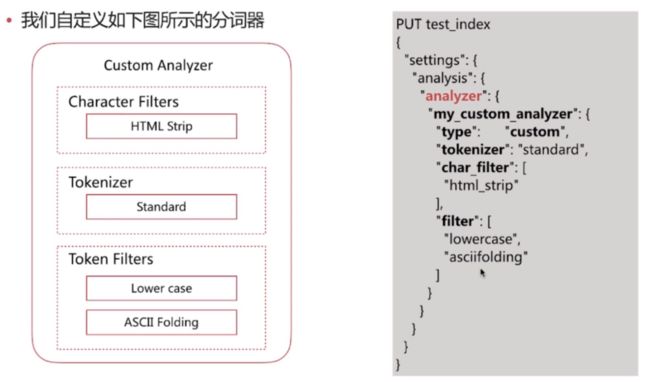
自定义分词器的三个组成部分:
Character Filters——char_filter
Tokenizer——tokenizer
Token Filters——filter
POST /_analyze
{
"tokenizer": "standard",
"filter": ["lowercase"],
"text": ["Hello ElasticSearch!"]
}
分词结果:
{
"tokens" : [
{
"token" : "hello",
"start_offset" : 0,
"end_offset" : 5,
"type" : "",
"position" : 0
},
{
"token" : "elasticsearch",
"start_offset" : 6,
"end_offset" : 19,
"type" : "",
"position" : 1
}
]
}
5. 自定义分词
当自带的分词无法满足需求时,可以自定义分词
- 通过自定义 Character Filters、Tokenizer和Token Filter实现
Character Filters
- 在Tokenizer之前对原始文本进行处理,比如增加、删除或替换字符等
- 自带的如下:
- HTML Strip去除html 标签和转换html实体
- Mapping 进行字符替换操作
- Pattern Replace 进行正则匹配替
- 会影响后续tokenizer 解析的postion和offset信息
HTML Strip
POST _analyze
{
"tokenizer": "keyword",
"char_filter": ["html_strip"],
"text": ["i am groot
"]
}
分词结果:
{
"tokens" : [
{
"token" : """
i am groot
""",
"start_offset" : 0,
"end_offset" : 17,
"type" : "word",
"position" : 0
}
]
}
Tokenizer
- 将原始文本按照一定规则切分为单词(term or token)
- 自带的如下:
- standard 按照单词进行分割
- letter 按照非字符类进行分割
- whitespace 按照空格进行分割
- UAX URL Email 按照standard分割,但不会分割邮箱和url
- NGram和Edge NGram连词分割
- Path Hierarchy 按照文件路径进行切割
Token Filter
- 对于tokenizer输出的单词(term)进行增加、删除、修改等操作
- 自带的如下:
- lowercase 将所有term转换为小写
- stop删除stop words
- NGram和Edge NGram连词分割
- Synonym 添加近义词的term
6. 自定义分词API
自定义分词需要在索引的配置中设定


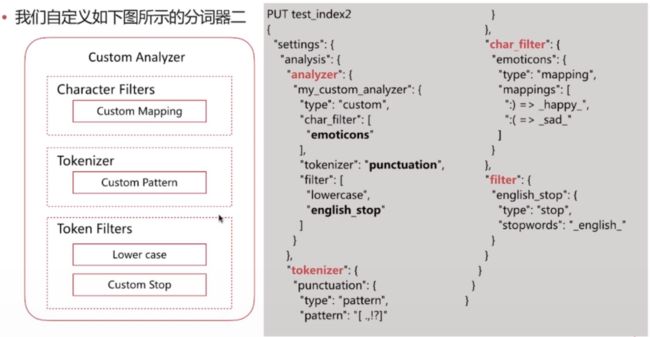

五、Mapping
类似数据库中的表结构定义,主要作用如下:
- 定义Index下的字段名(Field Name)
- 定义字段的类型,比如数值型、字符串型、布尔型等
- 定义倒排索引相关的配置,比如是否索引、记录 position等
1. mapping参数配置
- Mapping 中的字段类型一旦设定后,禁止直接修改,原因如下:
- Lucene 实现的倒排索引生成后不允许修改
- 如果要修改就需要重新建立新的索引,然后做 reindex操作把之间索引的数据导入到新的索引中
- 允许新增字段
- 通过dynamic参数来控制字段的新增
- true(默认)允许自动新增字段
- false 不允许自动新增字段,但是文档可以正常写入,但无法对字段进行查询等操作
- strict 文档不能写入mapping未定义的字段,插入文档会报错
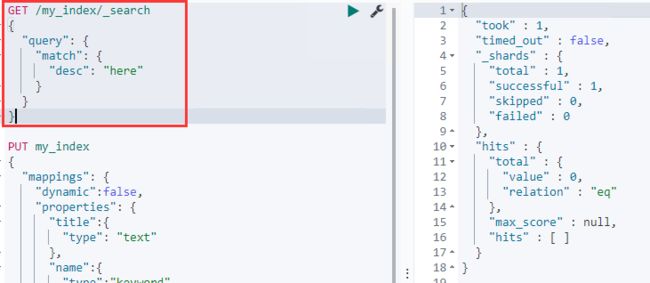
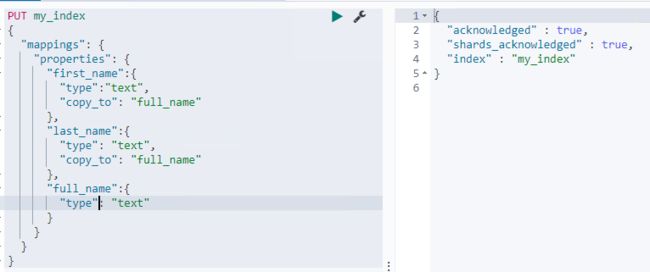
- copy_to字段复制
- 将该字段的值复制到目标字段,实现类似_all的作用
- 不会出现在_source中,只用来搜索,一般也是用于搜索使用
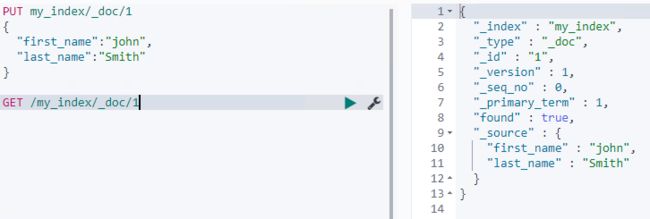
- index控制当前字段是否索引
- 默认为true,记录索引,即可搜索
- false则不记录索引,即不可搜索该字段,省去了为该字段建立倒排索引的时间与空间
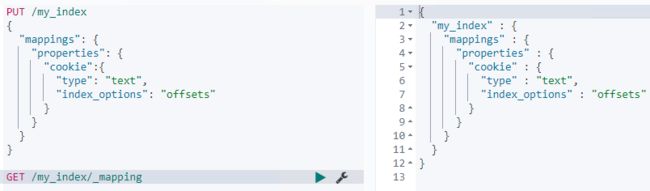
- index_options用于控制倒排索引记录的内容
- 有如下4种配置
- docs 只记录 doc id
- freqs 记录 doc id和term frequencies
- positions 记录 doc id、term frequencies和term position
- offsets 记录 doc id、term frequencies、term position和character offsets
- text 类型默认配置为positions,其他默认为docs
- 记录内容越多,占用空间越大
- 有如下4种配置
- null_value 当字段遇到null值的处理策略
- 默认为null,即空值,此时es会忽略该值。
- fields 多字段multi-fields
- 多字段可以以不同方式索引相同字段。例如,一个字符串字段既可以映射为全文搜索的text字段,也可以映射为排序或聚合的keyword字段。
dynamic控制字段的新增


copy_to将字段复制到目标字段
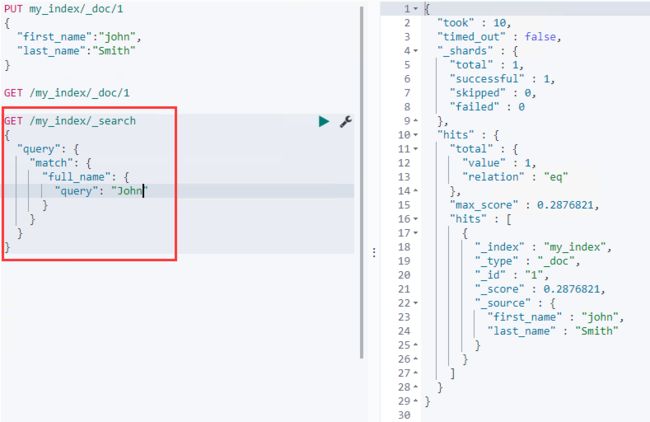
index控制当前字段是否索引
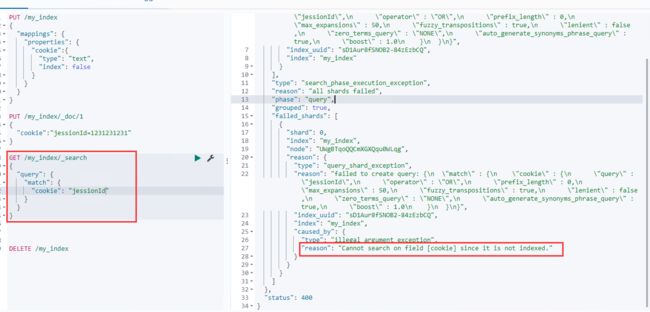
index_options控制倒排索引记录的内容
2. 数据类型
- 核心数据类型
- 字符串类型 text(分词)、keyword(不分词)
- 数值型long、integer、short、byte、double、float、half_float、scaled_float
- 日期类型 date
- 日期纳秒类型 date_nanos
- 布尔类型 boolean
- 二进制类型 binary
- 范围类型 integer_range、float_range、long_range、double_range、date_range
- 复杂类型
- 数组类型 array
- 对象类型 object
- 嵌套类型 nested object
- 地理位置类型
- 地理位置点 Geo-point
- 地理位置形状 Geo-shape
- 专用类型
- 记录ip地址 ip
- 实现自动补全 completion
- 记录分词数 token_count
- 记录字符串hash值 murmur3
- annotated-text
- percolator
- join
- alias
- rank_feature
- rank_features
- dense_vector
- sparse_vector
- 多字段特性 multi-fields
-
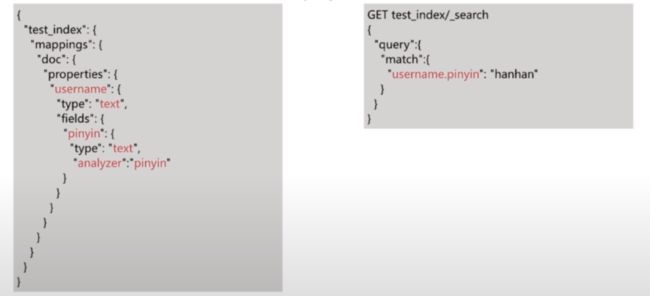
允许对同一个字段采用不同的配置,比如分词,常见例子如对人名实现拼音搜索,只需要在人名中新增一个子字段为pinyin即可,分词器需要支持子字段分词才可以索引
-
3. Dynamic Mapping
Dynamic field mapping
-
es可以自动识别文档字段类型,从而降低用户使用成本
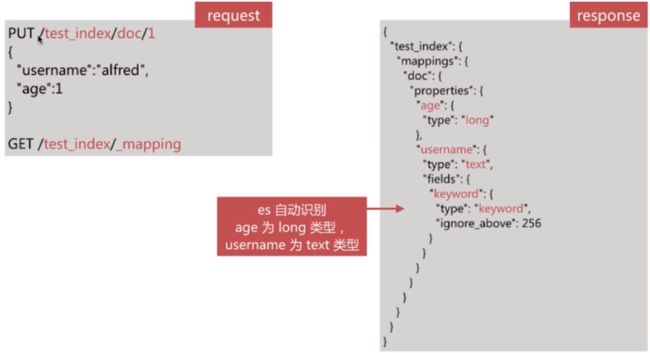
-
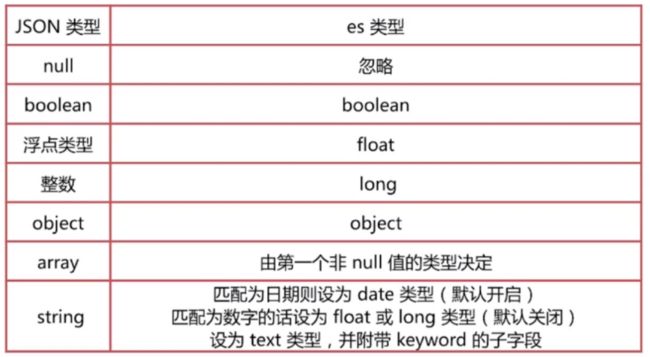
es是依靠JSON文档的字段类型来实现自动识别字段类型,支持的类型如下
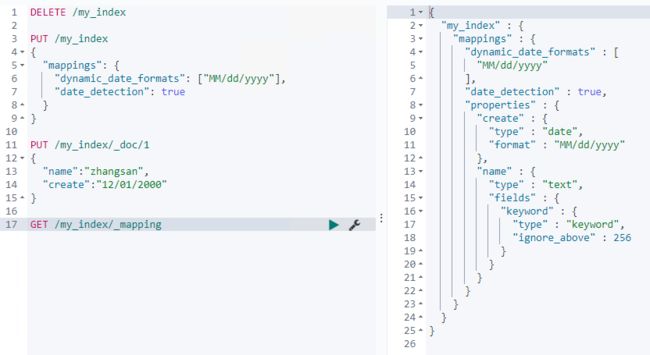
- 日期的自动识别可以自行配置日期格式,以满足各种需求
- 默认匹配格式是["strict_date_optional_time","yyyy/MM/dd HH:mm:ss Zllyyyy/MM/dd Z]
- strict_date_optional_time是ISO datetime的格式,完整格式类似下面:
- YYYY-MM-DDThh:mm:ssTZD(eg 1997-07-16T19:20:30+01:00)
- dynamic_date_formats可以自定义日期类型
-
date_detection 可以关闭日期自动识别的机制
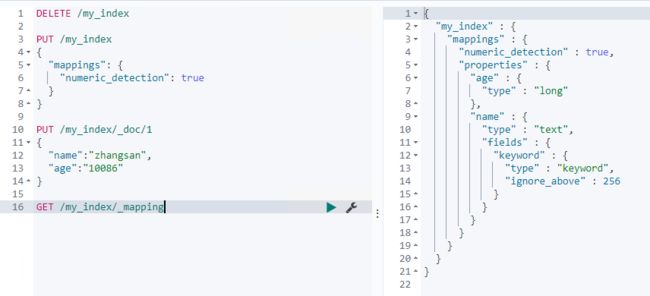
- 字符串是数字时,默认不会自动识别为整型,因为字符串中出现数字是完全合理的
-
numeric_detection可以开启字符串中数字的自动识别,如下所示
-
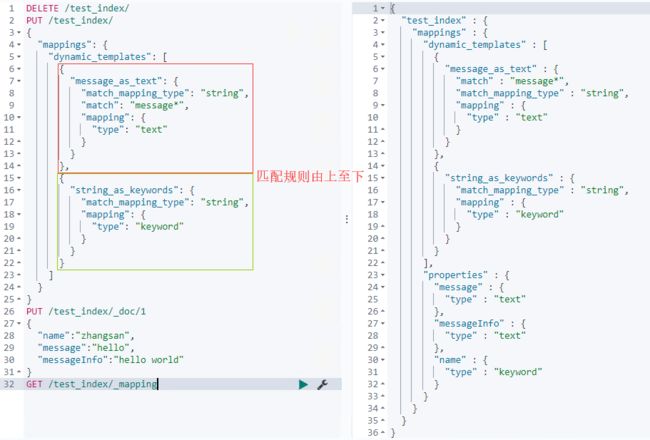
Dynamic templates
- 允许根据es自动识别的数据类型、字段名等来动态设定字段类型,可以实现如下效果:
- 所有字符串类型都设定为keyword类型,即默认不分词
- 所有以message开头的字段都设定为text类型,即分词
- 所有以long_开头的字段都设定为long类型
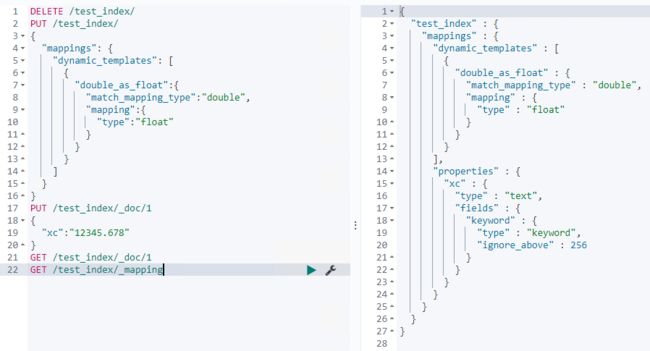
- 所有自动匹配为double类型的都设定为float类型,以节省空间
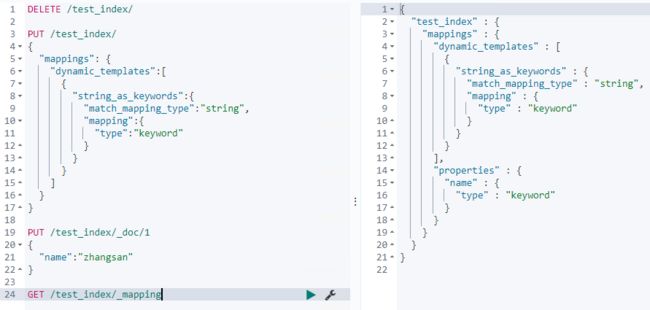
- 匹配规则参数
- match_mapping_type 匹配es自动识别的字段类型,如boolean,long,string等
- match,unmatch 匹配字段名
- path_match,path_unmatch 匹配路径
4. 自定义Mapping的建议
自定义Mapping的操作步骤如下:
- 写入一条文档到es的临时索引中,获取es自动生成的mapping
- 修改步骤1得到的mapping,自定义相关配置
- 使用步骤2的mapping 创建实际所需索引
六、Search APIs
实现对es中存储的数据进行查询分析,endpoint为_search,如下所示:

查询主要有两种形式:
- URI Search
- 操作简便,方便通过命令行测试
- 仅包含部分查询语法
- Request Body Search
- es提供的完备查询语法Query DSL(Domain Specific Language)

1. URI Search
通过url query参数来实现搜索,常用参数如下:
- q 指定查询的语句,语法为Query String Syntax
- df 若q中不指定字段时默认查询的字段,如果不指定,es会查询所有字段
- sort 排序
- timeout 指定超时时间,默认不超时
- from,size 用于分页
Query String Syntax
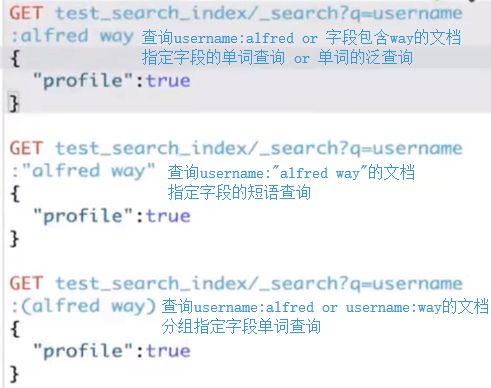
term(单词)与 phrase(词语)
- alfred way 单词查询,等效于 alfred OR way
- "alfred way" 词语查询,查询时会按照单词先后顺序检索
泛查询
- alfred 等效于在所有字段去匹配该term
指定字段
- name:alfred 查询name字段包含alfred的文档
Group分组设定,使用括号指定匹配的规则
- (quick OR brown) AND fox
- status:(active OR pending) title:(full text search)
布尔操作符
- AND(&&) OR(||) NOT(!)
- name:(tom NOT lee) 查询name字段不包含lee或者name字段包含tom的文档
- name:(tom AND NOT lee) 查询name字段不包含lee并且name字段包含tom的文档
- name:(tom OR lee) 等价于name:(tom lee) 查询name字段包含lee或者name字段包含tom的文档
- 注意AND OR NOT一定是大写的,小写的就变成term了
- +-分别对应must和must_not
- name:(tom +lee -alfred) 查询name字段一定包含lee一定不包含alfred可以包含tom的文档
- 等价于 name:(lee AND NOT alfred) OR (tom AND lee AND NOT alfred))
- +在url中会被解析为空格,要使用urlencode后的结果才可以,+为%2B
- name:(tom +lee -alfred) 查询name字段一定包含lee一定不包含alfred可以包含tom的文档
范围查询,支持数值和日期
- 区间写法,闭区间[],开区间用{}
- age:[1 TO 10]意为1<=age<=10
- age:[1 TO 10}意为1<=age<10
- age:[1 TO ]意为age>=1
- age:[* TO 10]意为age<=10
- 算数符号写法
- age:>=1
- age:(>=1 && <=10)或者age:(+>=1 + <=10)
通配符查询
- ? 代表1个字符,* 代表0或多个字符
- name:t?m
- name:tom*
- name:t*m
- 通配符匹配执行效率低,且占用较多内存,不建议使用
- 如无特殊需求,不要将?/*放在最前面,放在最前面会检索全部文档,效率最低,内存易oom
模糊匹配 fuzzy query
- name:roam~1 匹配与roam查1个character的词,比如foam roams等
- 以 character 字符为单位进行差异比较
近似度查询 proximity search
- "fox quick"~5 匹配5个单位差异的文档
- 以 term 为单位进行差异比较,比如"quick fox" "quick brown fox"都会被匹配


2. Request Body Search 【推荐使用!!!功能比URI Search更强大!!!】
将查询语句通过http request body发送到es,主要包含如下参数:
- query符合Query DSL语法的查询语句
- from,size 用于分页查询
- timeout 指定超时时间,默认不超时
- sort 排序
Source filtering
过滤返回结果中source中的字段,主要有如下几种方式:

Query DSL
基于JSON定义的查询语言,主要包含如下两种类型:
- 字段类查询
- 如term,match,range等,只针对某一个字段进行查询
- 复合查询
- 如bool查询等,包含一个或多个字段类查询或者复合查询语句
字段类查询
字段类查询主要包括以下两类:
- 全文匹配
- 针对text 类型的字段进行全文检索,会对查询语句先进行分词处理,如match,match_phrase等query类型
- 单词匹配
- 不会对查询语句做分词处理,直接去匹配字段的倒排索引,如term,terms,range等query类型
Match Query
-
对字段作全文检索,最基本和常用的查询类型,API示例如下:

-
Match Query执行流程:
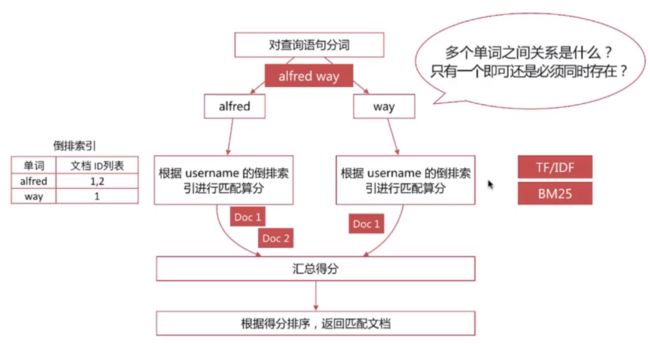
-
通过operator参数可以控制单词间的匹配关系,可选项为or和and

-
通过minimum_should_match参数可以控制需要匹配的单词数

Match Phrase Query
-
对字段作检索,对单词有顺序要求,API示例如下:
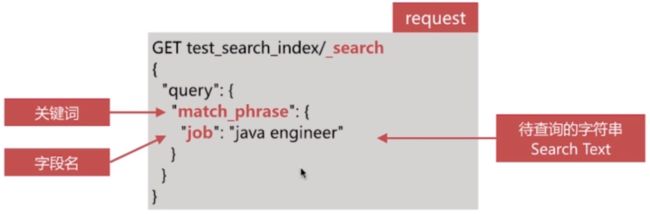 匹配job字段包含java engineer单词,且java在engineer前面的文档
匹配job字段包含java engineer单词,且java在engineer前面的文档 -
通过slop参数可以控制单词间的间隔
 slop以term为单位
slop以term为单位
Query String Query
- 类似于URI Search中的q参数查询

Simple Query String Query
- 类似Query String,但是会忽略错误的查询语法,并且仅支持部分查询语法
- 其常用的逻辑符号如下,不能使用AND、OR、NOT 等关键词:
-
+代指AND -
|代指OR -
-代指NOT
-

Term Query
将查询语句作为整个单词进行查询,即不对查询语句做分词处理,常用于查询keyword类型字段,如下所示:

Terms Query
一次传入多个单词进行查询,如下所示:

Range Query
范围查询主要针对数值和日期类型,如下所示:
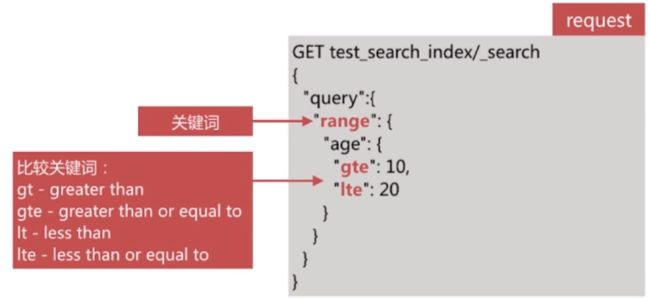

-
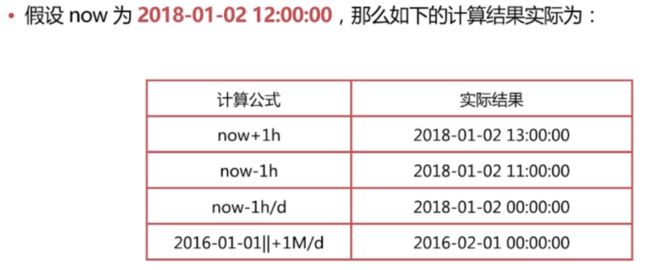
Date Math 针对日期提供的一种更友好地计算方式,格式如下:
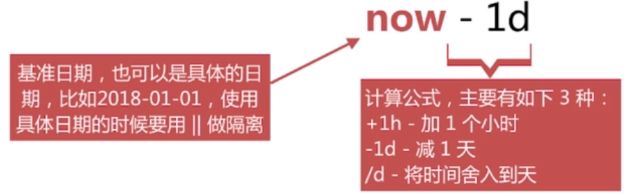 Date Math
Date Math

复合查询
复合查询是指包含字段类查询或复合查询(复合查询里面可以包含复合查询)的类型,主要包括以下几类:
- constant_score query
- bool query
- dis_max query
- function_score query
- boosting query
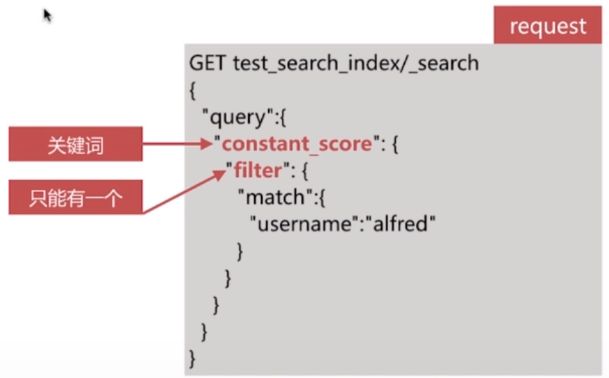
constant_score query
该查询将其内部的查询结果文档得分都设定为1或者boost的值
- 多用于结合bool 查询实现自定义得分
bool query
- 布尔查询由一个或多个布尔子句组成,主要包含如下4个:
- filter 只过滤符合条件的文档,不计算相关性得分
- must 文档必须符合must中的所有条件,会影响相关性得分
- must_not 文档必须不符合must_not中的所有条件
- should 文档可以符合should中的条件,会影响相关性得分

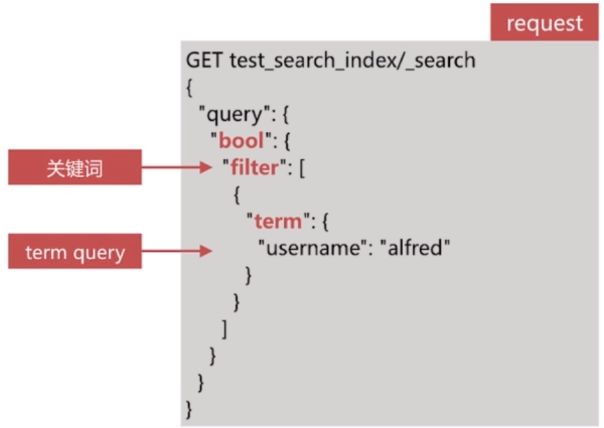
filter
- Filter 查询只过滤符合条件的文档,不会进行相关性算分
- es针对filter会有智能缓存,因此其执行效率很高
- 做简单匹配查询且不考虑算分时,推荐使用 filter 替代 query 等
must
- 文档必须符合must中的所有条件,会影响相关性得分

must_not
- 文档必须不符合must_not中的所有条件

should
- 文档可以符合should中的条件,会影响相关性得分
- Should 使用分两种情况:
- bool 查询中只包含should,不包含 must 查询
- 只包含should时,文档必须满足至少一个条件
-
minimum_should_match 可以控制满足条件的个数或者百分比

- bool 查询中同时包含 should 和 must 查询
-
同时包含should和must时,文档不必满足should中的条件,但是如果满足条件,会增加相关性得分

-
- bool 查询中只包含should,不包含 must 查询
Query Context VS Filter Context
当一个查询语句位于Query或者Filter上下文时,es执行的结果会不同,对比如下:


3. Count API
获取符合条件的文档数,endpoint 为 _count

七、分布式
1. 分布式特性
- es支持集群模式,是一个分布式系统,其好处主要有两个:
- 增大系统容量,如内存、磁盘,使得es集群可以支持PB级的数据
- 提高系统可用性,即使部分节点停止服务,整个集群依然可以正常服务
- es集群由多个es实例组成
- 不同集群通过集群名字来区分,可通过cluster.name 进行修改,默认为elasticsearch
- 每个es实例本质上是一个JVM进程,且有自己的名字,通过node.name 进行修改
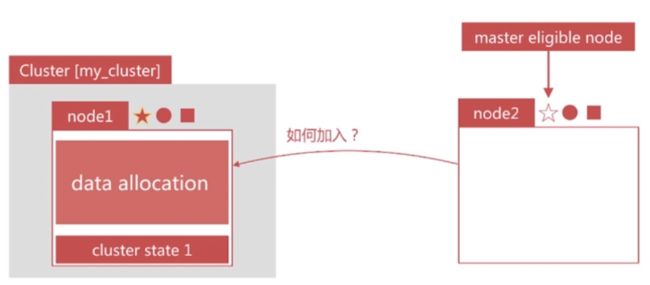
2. 构建集群
启动单节点
运行如下命令可以启动一个es节点实例:
bin/elasticsearch -E cluster.name=my_cluster -E node.name=node1

再启动一个新的es节点,构建一个由node1和node2 2个节点组成的集群my_cluster
bin/elasticsearch -E cluster.name=my_cluster -E node.name=node2
集群状态 Cluster State
es 集群相关的数据称为cluster state,主要记录如下信息:
- 节点信息,比如节点名称、连接地址等
- 索引信息,比如索引名称、配置等

Master Node 主节点
- 可以修改
cluster state的节点称为master节点,一个集群只能有一个 -
cluster state存储在每个节点上,master 维护最新版本并同步给其他节点 -
master节点是通过集群中所有节点选举产生的,可以被选举的节点称为master- eligible节点,相关配置如下:- node.master:true

创建索引后,cluster state 的版本将更新

Coordinating Node 协调节点
处理请求的节点即为coordinating 节点,该节点为所有节点的默认角色,不能取消
- 路由请求到正确的节点处理,比如创建索引的请求转发(Redis是重定向)到
master节点

Data Node 数据存储节点
存储数据的节点即为data节点,默认节点都是data类型,相关配置如下:
- node.data:true

3. 副本与分片
提高系统可用性
- 服务可用性
- 2个节点的情况下,允许其中1个节点停止服务
- 数据可用性
- 引入副本(Replication)解决
- 每个节点上都有完备的数据
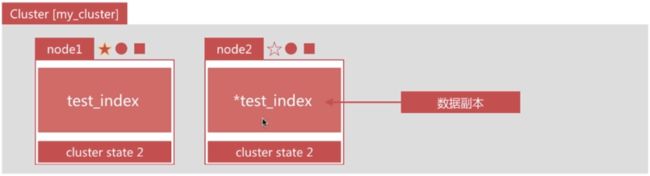
副本
ES中的副本不是对面向节点的副本,而是面向分片的副本,副本分片的数据由主分片同步,可以有多个,从而提高读取的吞吐量,且可以随时修改副本数量。
增大系统容量
-
如何将数据分布于所有节点上?
- 引入分片(Shard)解决问题
-
分片是es支持PB级数据的基石
- 分片存储了部分数据,可以分布于任意节点上
- 分片数在索引创建时指定且后续不允许再更改,默认为5个
- 分片有主分片和副本分片之分,以实现数据的高可用
- 副本分片的数据由主分片同步,可以有多个,从而提高读取的吞吐量,且可以随时修改副本数量
分片
分片数的设定很重要,需要提前规划好
- 过小会导致后续无法通过增加节点实现水平扩容
- 过大会导致一个节点上分布过多分片,造成资源浪费,同时会影响查询性能

此时增加副本数是否能提高test_index的读取吞吐量?
不能。因为新增的副本也是分布在这3个节点上,还是利用了同样的资源。如果要增加吞吐量,还需要新增节点。
此时增加节点是否能提高test_index的数据容量?
不能。因为创建索引时指定了3个分片,已经分布在3台节点上,新增的节点无法利用。
4. 集群运行状态
Cluster Health
通过如下api可以查看集群健康状况,包括以下三种:
- green健康状态,指所有主副分片都正常分配
- yellow指所有主分片都正常分配,但是有副本分片未正常分配
- red有主分片未分配

5. 故障转移
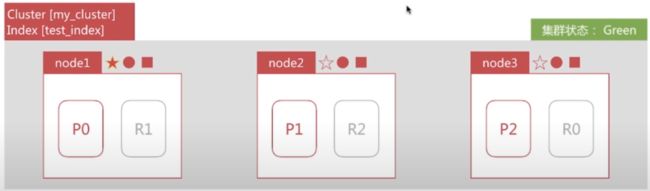
- 集群由3个节点组成,如下所示,此时集群状态是green
-
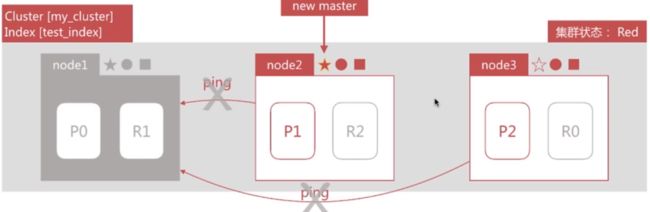
node1 所在机器宕机导致服务终止,此时集群会如何处理?
-
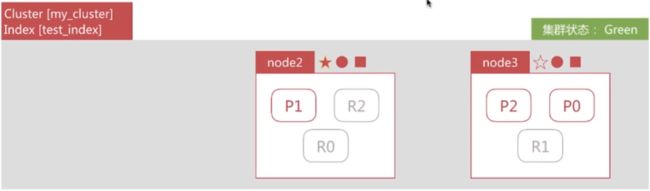
node2和node3发现node1无法响应一段时间后会发起master选举,比如这里选择node2为master节点。此时由于主分片P0下线,集群状态变为Red。
-
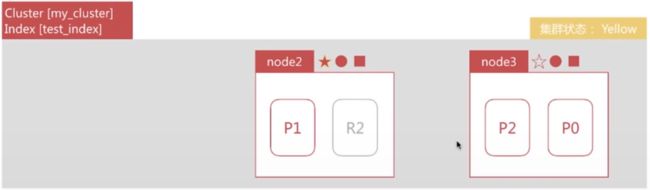
node2发现主分片P0未分配,将R0提升为主分片。此时由于所有主分片都正常分配,集群状态变为Yellow。
-
node2为P0和P1生成新的副本,集群状态变为绿色
-
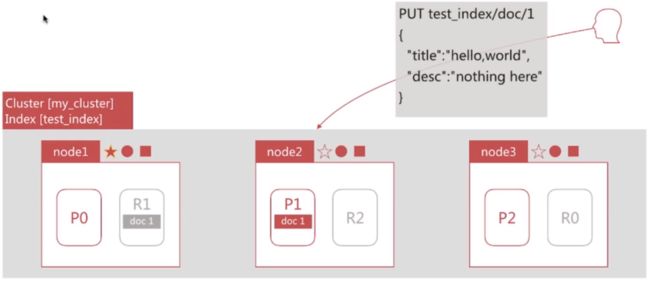
6. 文档分布式存储
-
文档最终会存储在分片上,如下图所示:
-
Document1最终存储在分片P1上
-
-
Document1是如何存储到分片P1的?选择P1的依据是什么?
- 需要文档到分片的映射算法
-
目的
- 使得文档均匀分布在所有分片上,以充分利用资源
-
算法
- 随机选择或者round-robin轮询算法?
- 不可取,因为需要维护文档到分片的映射关系,成本巨大
- 根据文档值实时计算对应的分片!
- 随机选择或者round-robin轮询算法?
文档到分片的映射算法
es通过如下的公式计算文档对应的分片:
shard=hash(routing) % number_of_primary_shards- hash 算法保证可以将数据均匀地分散在分片中
- routing是一个关键参数,默认是文档id,也可以自行指定
- number_of_primary_shards是主分片数
该算法与主分片数相关,这也是分片数一旦确定后便不能更改的原因
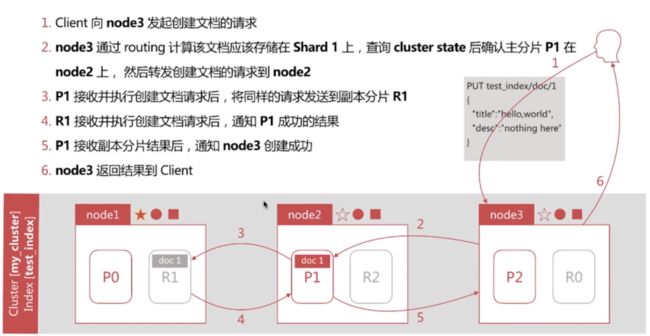
文档创建的流程
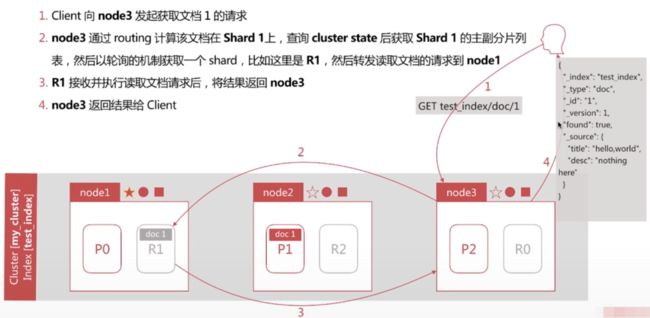
文档读取的流程
文档批量创建的流程
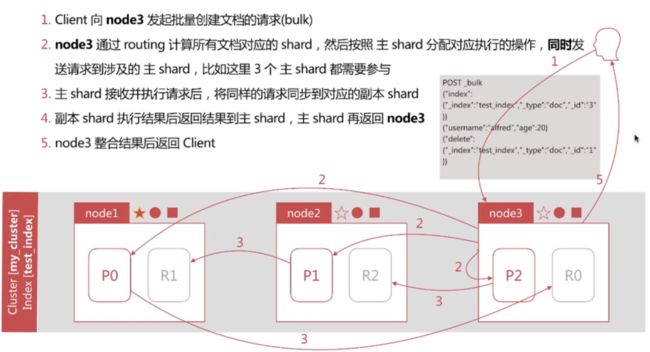
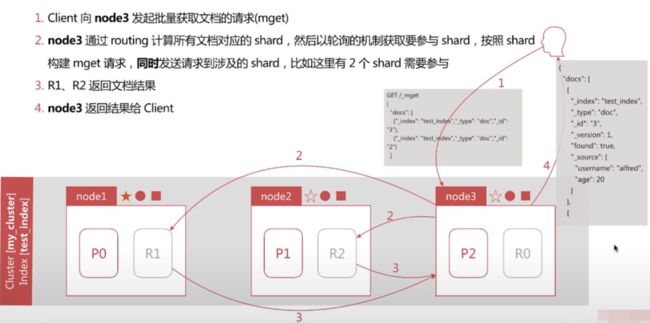
文档批量读取的流程
7. 脑裂问题
脑裂问题,英文为 split-brain,是分布式系统中的经典网络问题
-
3个节点组成的集群,突然 node1的网络和其他两个节点中断

node2与node3会重新选举 master,比如node2成为了新 master,此时会更新cluster state
node1自己组成集群后,也会更新 cluster state
同一个集群有两个master,而且维护不同的cluster state,网络恢复后无法选择正确的master
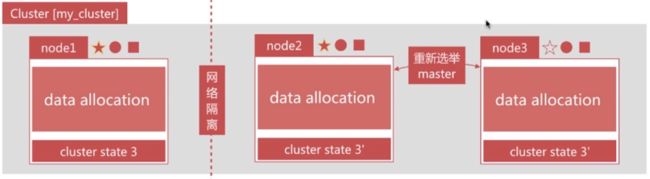
解决方案
解决方案为仅在可选举master-eligible节点数大于等于quorum时才可以进行 master
选举
-
quorum=master-eligible节点数/2+1,例如3个master-eligible节点时,quorum为2。 - 配置
discovery.zen.minimum_master_nodes: quorum即可避免脑裂
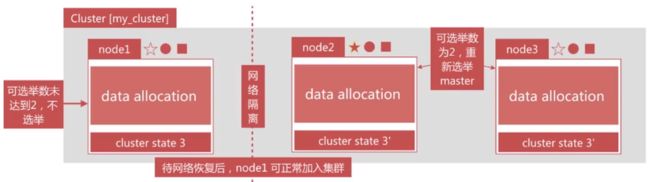
8. shard详解
倒排索引的不可变更
- 倒排索引一旦生成,不能更改
- 其好处如下:
- 不用考虑并发写文件的问题,杜绝了锁机制带来的性能问题
- 由于文件不再更改,可以充分利用文件系统缓存,只需载入一次,只要内存足够,对该文件的读取都会从内存读取,性能高
- 利于生成缓存数据
- 利于对文件进行压缩存储,节省磁盘和内存存储空间
-
坏处为需要写入新文档时,必须重新构建倒排索引文件,然后替换老文件后,新文档才能被检索,导致文档实时性差
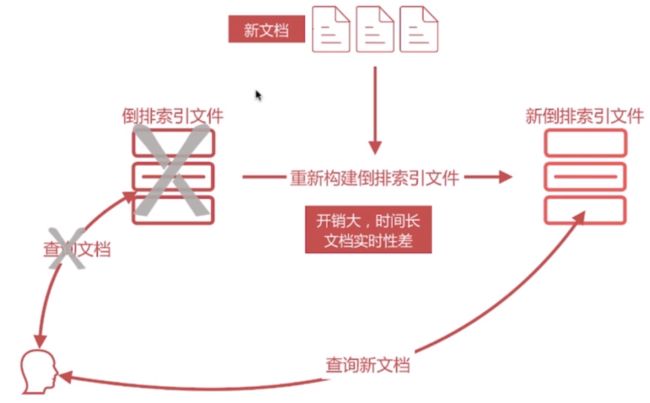
文档搜索实时性
-
解决方案是新文档直接生成新的倒排索引文件,查询的时候同时查询所有的倒排文件,然后做结果的汇总计算即可
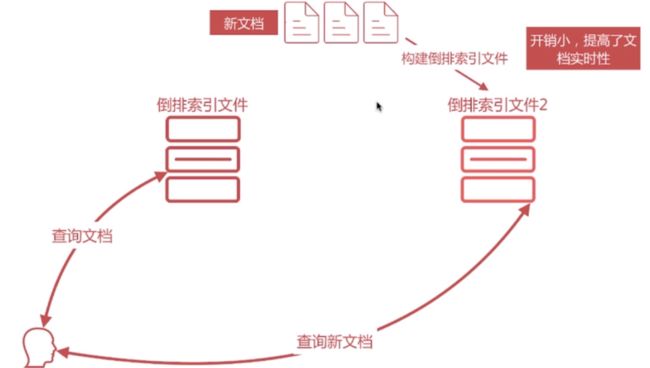
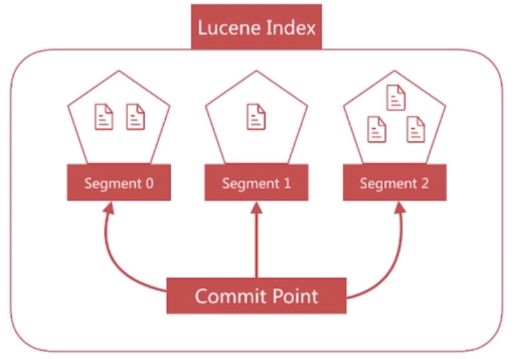
- Lucene 便是采用了这种方案,它构建的单个倒排索引称为
segment,合在一起称为Index,与ES中的Index概念不同。 - Lucene 会有一个专门的文件来记录所有的
segment信息,称为commit point
文档搜索实时性 - refresh
-
segment写入磁盘的过程依然很耗时,可以借助文件系统缓存的特性,先将segment在缓存中创建并开放查询来进一步提升实时性,该过程在 es 中被称为refresh。 - 在
refresh之前文档会先存储在一个buffer中,refresh时将 buffer中的所有文档清空并生成segment
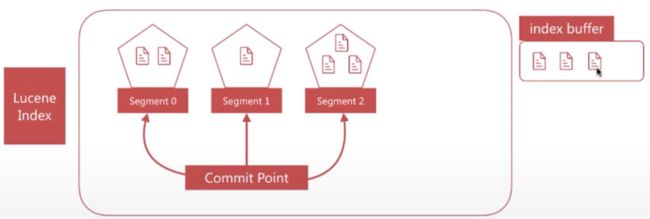 refresh发生前
refresh发生前
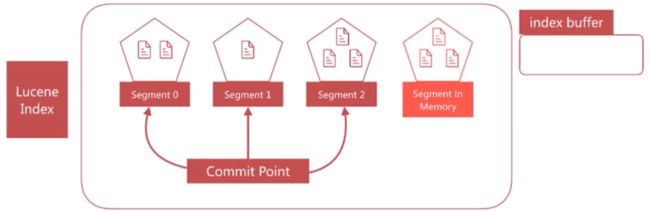 refresh发生后
refresh发生后 - es默认每1秒执行一次
refresh,因此文档的实时性被提高到1秒,这也是es被称为近实时(Near Real Time)的原因
refresh 发生的时机主要有如下几种情况:
- 间隔时间达到时,通过
index.settings.refresh_interval来设定,默认是1秒 - index.bufer 占满时,其大小通过
indices.memory.index_buffer_size设置,默认为jvm heap的10%,所有shard共享 - flush发生时也会发生refresh
文档搜索实时性 - translog
- 如果在内存中的 segment 还没有写入磁盘前发生了宕机,那么其中的文栏档就无法恢复了,如何解决这个问题?
- es引入
translog机制。写入文档到buffer时,同时将该操作写入translog。
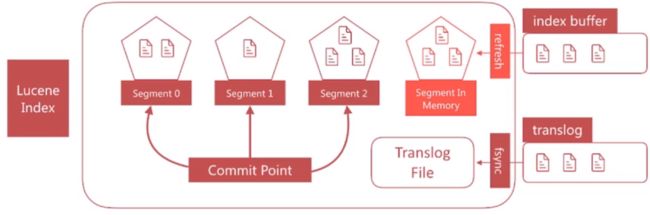
-
translog文件会即时写入磁盘(fsync),6.x默认每个请求都会落盘,可以修改为每5秒写一次,这样风险便是丢失5秒内的数据,相关配置为index.translog.* - es启动时会检查
translog文件,并从中恢复数据
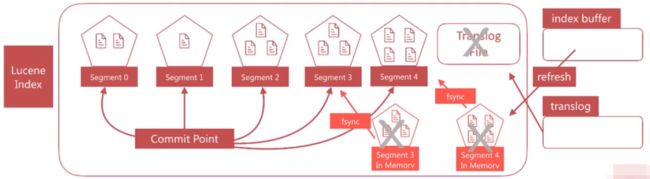
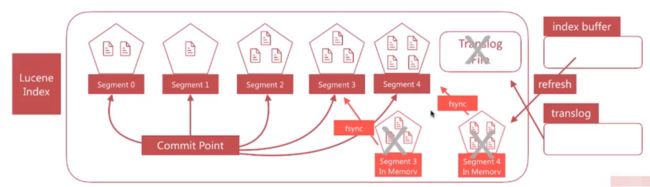
文档搜索实时性 - flush
flush负责将内存中的segment写入磁盘,主要做如下的工作:
- 将 translog 写入磁盘、
- 将 index buffer 清空,其中的文档生成一个新的 segment,相当于一个refresh操作
- 更新commit point 并写入磁盘
- 执行fsync操作,将内存中的segment写入磁盘
-
删除旧的translog文件
flush发生的时机主要有如下几种情况:
- 间隔时间达到时,默认是30分钟,5.x之前可以通过
index.translog.flush threshold period修改,之后无法修改 - translog 占满时,其大小可以通过
index.translog.flush threshold size控制,默认是512mb,每个 index 有自己的 translog
文档搜索实时性 - 删除与更新文档
- segment一旦生成就不能更改,那么如果你要删除文档该如何操作?
- Lucene专门维护一个.del的文件,记录所有已经删除的文档,注意.del上记录的是文档在Lucene内部的id
- 在查询结果返回前会过滤掉.del中的所有文档
- 更新文档如何进行呢?
- 首先删除文档,然后再创建新文档
Segment Merging
- 随着segment的增多(es默认每秒refresh一次,每次refresh后都会生成新的segement),由于一次查询的segment数(查询所有的segement做汇总)增多,查询速度会变慢
- es 会定时在后台进行 segment merge的操作,减少segment的数量
- 通过force_merge api可以手动强制做 segment merge的操作
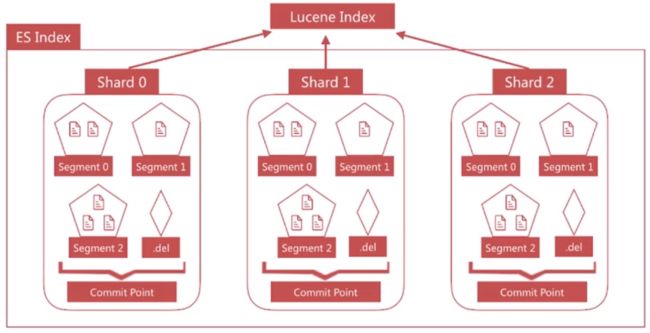
ES Index与Lucene Index的对照整体视角
八、深入了解Search的运行机制
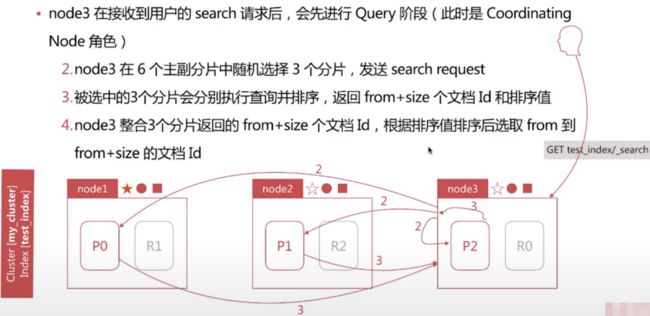
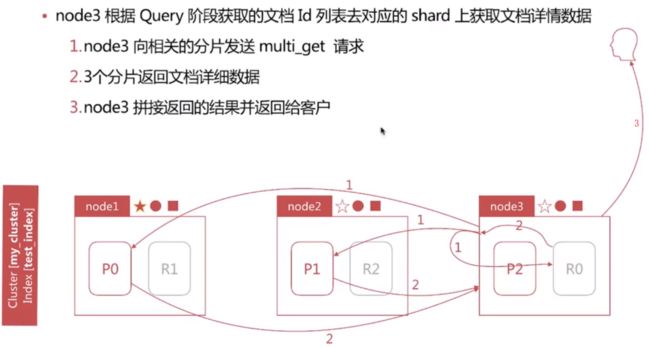
1. Query-Then-Fetch
Search执行的时候实际分两个步骤运作的
- Query阶段
- Fetch阶段
Query阶段
Fetch阶段
2. 相关性算分问题
相关性算分在shard与shard间是相互独立的,也就意味着同一个Term的IDF等值在不同shard上是不同的。
文档的相关性算分和它所处的shard相关
在文档数量不多时,会导致相关性算分严重不准的情况发生
解决方案
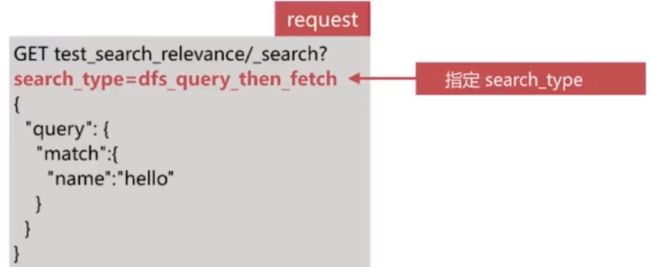
一是设置分片数为1个,从根本上排除问题,在文档数量不多的时候可以考虑该方案,比如百万到干万级别的文档数量
二是使用DFS Query-then-Fetch 查询方式
DFS Query-then-Fetch是在拿到所有文档后再重新完整的计算一次相关性算分,耗费更多的cpu和内存,执行性能也比较低下,一般不建议使用。使用方式如下:
3. 排序
es默认会采用相关性算分排序,用户可以通过设定sorting参数来自行设定排序规则
单字段排序

多字段排序

字符串类型排序
按照字符串排序比较特殊,因为es有text和keyword两种类型
针对text类型排序

针对keyword类型排序

排序原理
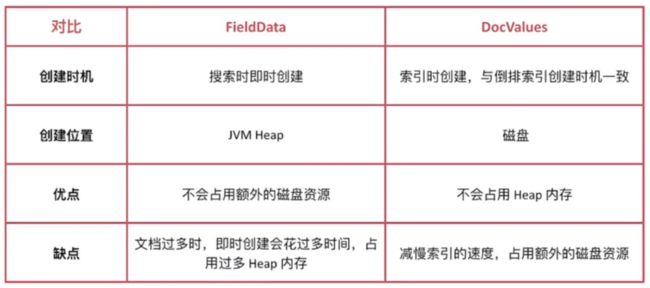
排序的过程实质是对字段原始内容排序的过程,这个过程中倒排索引无法发挥作用,需要用到正排索引,也就是通过文档ld和字段快速得到字段原始内容,然后对字段原始内容排序。
通过文档ld和字段快速得到字段原始内容,ES对此提供了2种实现方式:
- fielddata 默认禁用
- doc values 默认启用,除了text类型
Fielddata
Fielddata 默认是关闭的,可以通过如下api开启:
- 此时字符串是按照分词后的term排序,往往结果很难符合预期
- 一般是在对分词做聚合分析的时候开启

DocValues
Doc Values默认是启用的,可以在创建索引的时候关闭:
- 如果后面要再开启 doc values,需要做reindex操作
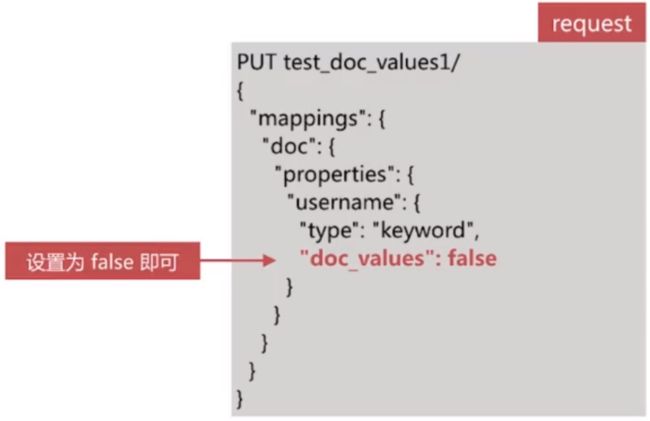
docvalue_fields
可以通过该字段获取 fielddata或者doc values中存储的内容

4. 分页与遍历
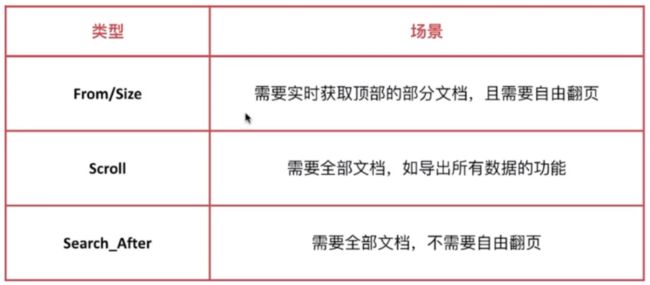
es 提供了3种方式来解决分页与遍历的问题:
- from/size
- scroll
- search_after
from/size
最常用的分页方案
- from 指明开始位置
- size 指明获取总数

深度分页问题
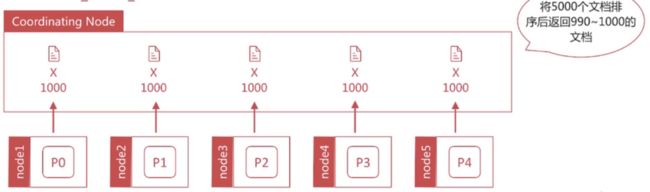
深度分页是一个经典的问题:在数据分片存储的情况下如何获取前1000个文档?
- 获取从990~1000的文档时,会在每个分片上都先获取1000个文档,然后再由Coordinating Node聚合所有分片的结果后再排序选取前1000个文档
- 页数越深,处理文档越多,占用内存越多,耗时越长。尽量避免深度分页,es通过index.max_result_window 限定最多到10000条数据
- 各大搜索引擎也都有此问题,google最多展示100页搜索结果,百度最多76页搜索结果
scroll
遍历文档集的api,以快照的方式来避免深度分页的问题
- 不能用来做实时搜索,因为数据不是实时的
- 尽量不要使用复杂的 sort 条件,使用 _doc 最高效
- 使用稍嫌复杂
使用方法
- 第一步需要发起1个scroll search,如下所示:
es在收到该请求后会根据查询条件创建文档Id合集的快照
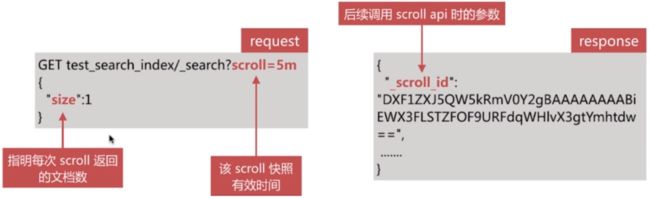
- 第二步调用scroll search的api,获取文档集合,如下所示:
不断迭代调用直到返回hits.hits数组为空时停止
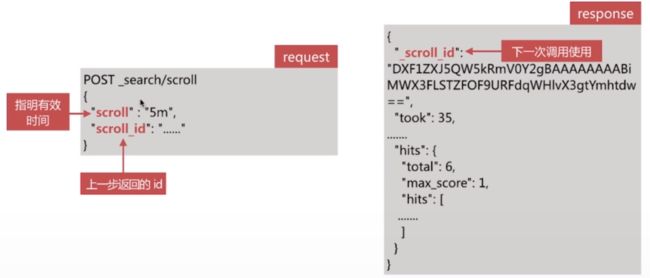
- 过多的scroll 调用会占用大量内存,可以通过clear api删除过多的scroll快照:
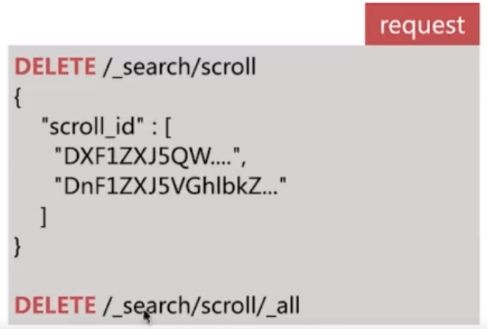
Search_After
避免深度分页的性能问题,提供实时的下一页文档获取功能
- 缺点是不能使用from参数,即不能指定页数
- 只能下一页,不能上一页
- 使用简单
使用方法
- 第一步为正常的搜索,但要指定 sort值,并保证值唯一
- 第二步为使用上一步最后一个文档的 sort 值进行查询

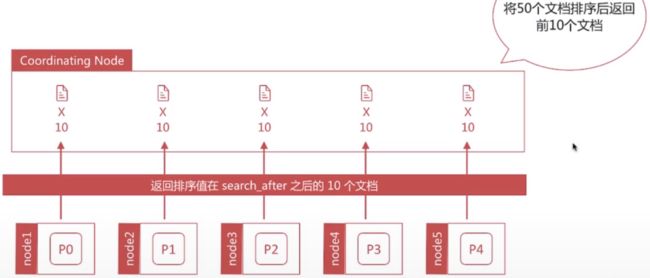
如何避免深度分页问题?
通过唯一排序值定位将每次要处理的文档数都控制在size内
应用场景
九、聚合分析 Aggregations
1. 什么是聚合分析
搜索引擎用来回答如下问题:
- 请告诉我地址为上海的所有订单?
- 请告诉我最近1天内创建但没有付款的所有订单?
聚合分析可以回答如下问题:
- 请告诉我最近1周每天的订单成交量有多少?
- 请告诉我最近1个月每天的平均订单金额是多少?
- 请告诉我最近半年卖的最火的前5个商品是哪些?
聚合分析,英文为 Aggregation,是es除搜索功能外提供的针对 es 数据做统计分析的功能
- 功能丰富,提供 Bucket、Metric、Pipeline 等多种分析方式,可以满足大部分的分析需求
- 实时性高,所有的计算结果都是即时返回的,而 hadoop 等大数据系统一般都是
T+1级别的
2. 聚合分析api

3. 聚合分析分类
为了便于理解,es将聚合分析主要分为如下4类:
- Bucket,分桶类型,类似SQL中的GROUP BY语法
- Metric,指标分析类型,如计算最大值、最小值、平均值等等
- Pipeline,管道分析类型,基于上一级的聚合分析结果进行再分析
- Matrix,矩阵分析类型
Metric 聚合分析
主要分如下两类:
- 单值分析,只输出一个分析结果
- min 最小,max 最大,avg 平均,sum 求和
- cardinality 数目
- 多值分析,输出多个分析结果
- stats,extended stats
- percentile,percentile rank
- top hits

Metric 聚合分析 - Min

Metric 聚合分析 - Max

Metric 聚合分析 - Avg

Metric 聚合分析 - Sum

Metric 聚合分析 - Cardinality

Metric 聚合分析 - Stats

Metric 聚合分析 - Extended Stats

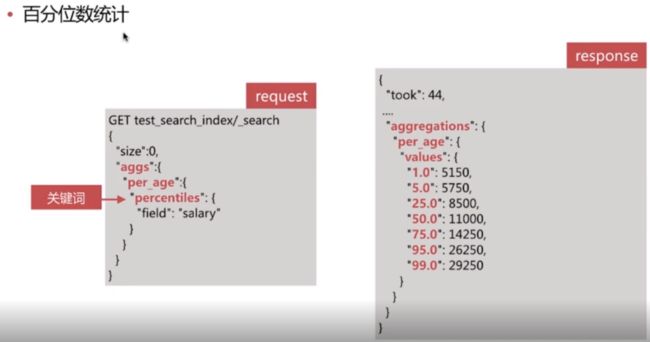
Metric 聚合分析 - Percentile
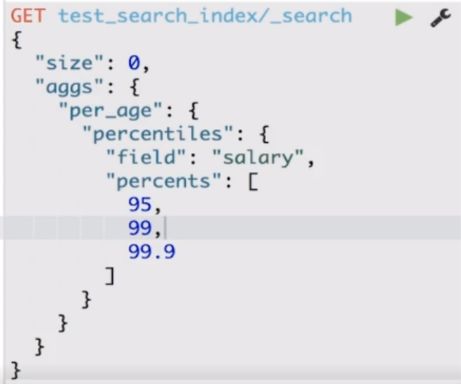
Metric 聚合分析 - Percentile Rank

Metric 聚合分析 - Top Hits

Bucket 聚合分析
Bucket,意为桶,即按照一定的规则将文档分配到不同的桶中,达到分类分析的目的
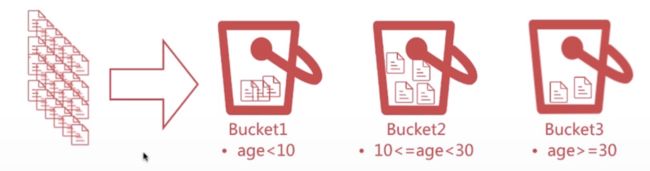
按照Bucket的分桶策略,常见的Bucket聚合分析如下:
- Terms
- Range
- Date Range
- Histogram
- Date Histogram
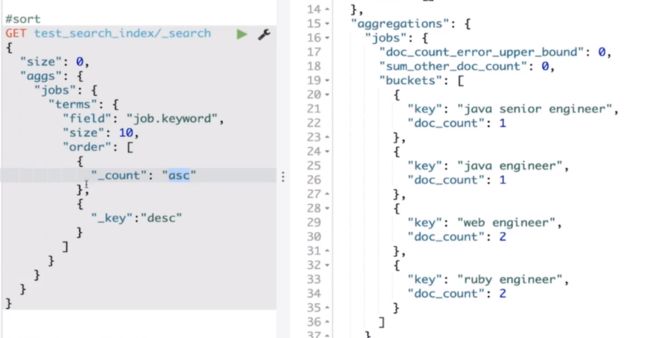
聚合分析 - Terms

-
Size
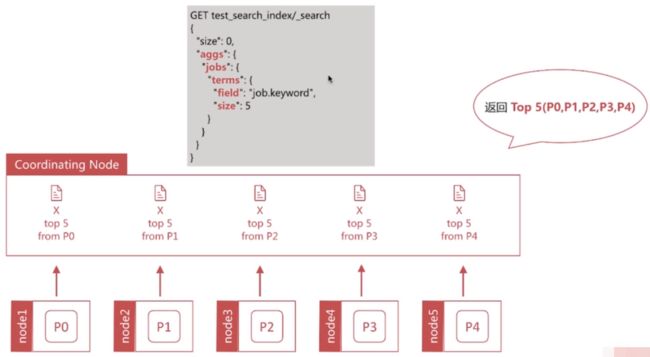
size参数表示从每个分片上返回_count值最大的前size个分桶,最终在Coordinating Node节点汇总所有分片返回的分桶结果,因此无法保证返回的前size个分桶数据一定是_count值最大的分桶,更多介绍:Terms 聚合的执行流程
Bucket 聚合分析 - Range

Bucket 聚合分析 - Date Range

Bucket 聚合分析 - Historgram

Bucket 聚合分析 - Date Historgram

Bucket + Metric 聚合分析
Bucket 聚合分析允许通过添加子分析来进一步进行分析,该子分析可以是 Bucket 也可以是 Metric。这也使得 es 的聚合分析能力变得异常强大。
分桶再分桶

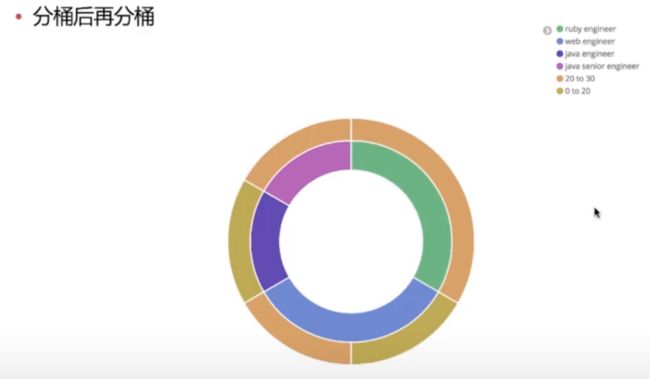
分桶后进行指标分析

Pipeline 聚合分析
针对聚合分析的结果再次进行聚合分析,而且支持链式调用,可以回答如下问题:

Pipeline的分析结果会输出到原结果中,根据输出位置的不同,分为以下两类:
- Parent结果内嵌到现有的聚合分析结果中
- Derivative
- Moving Average
- Cumulative Sum
- Sibling 结果与现有聚合分析结果同级
- Max/Min/Avg/Sum Bucket
- Stats/Extended Stats Bucket
- Percentiles Bucket
Pipeline 聚合分析 Sibling - Min Bucket

Pipeline 聚合分析 Sibling - Max Bucket

Pipeline 聚合分析 Sibling - Percentiles Bucket

Pipeline 聚合分析 Parent - Derivative

Pipeline 聚合分析 Parent - Moving Average

Pipeline 聚合分析 Parent - Cumulative Sum

4. 作用范围
es 聚合分析默认作用范围是query的结果集,可以通过如下的方式改变其作用范围:
- filter
- post_filter
- global

作用范围 - filter

作用范围 - post-filter

作用范围 - global

5. 排序
可以使用自带的关键数据进行排序,比如:
- _count 文档数
- key 按照 key 值排序
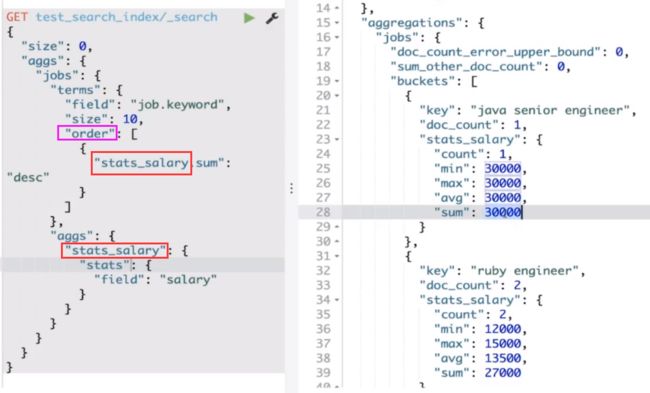
6. 计算精准度问题
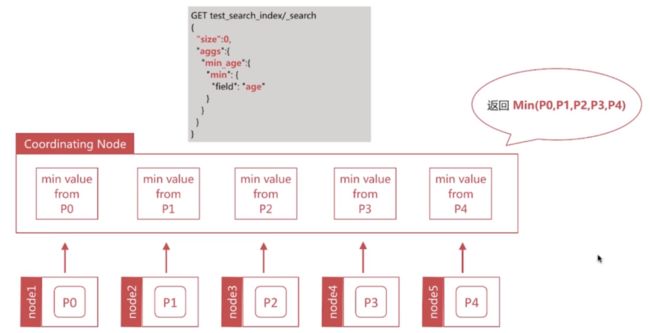
Min 聚合的执行流程
Terms 聚合的执行流程
Terms 并不总是准确
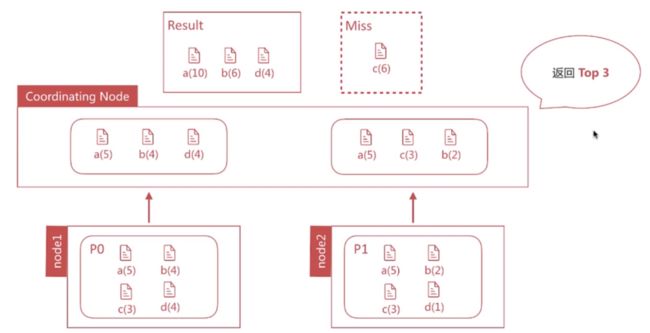
Terms 不准确的原因
数据分散在多Shard上,Coordinating Node 无法得悉数据全貌
Terms 不准确的解决方法
设置Shard数为1,消除数据分散的问题,但无法承载大数据量
-
合理设置 Shard_Size大小,即每次从Shard上额外多获取数据,以提升准确度

Shard_Size 大小的设定方法
- Shard_Size 默认大小如下:
- shard_size = (size * 1.5) + 10
- 通过调整 Shard_Size 的大小降低 doc_count_error_upper_bound 来提升准确度
- 增大了整体的计算量,从而降低了响应时间
terms 聚合返回结果中有如下两个统计值:
- doc_count_error_upper_bound 被遗漏的 term 可能的最大值
- sum_other_doc_count 返回结果 bucket 的 term 外其他 term 的文档总数
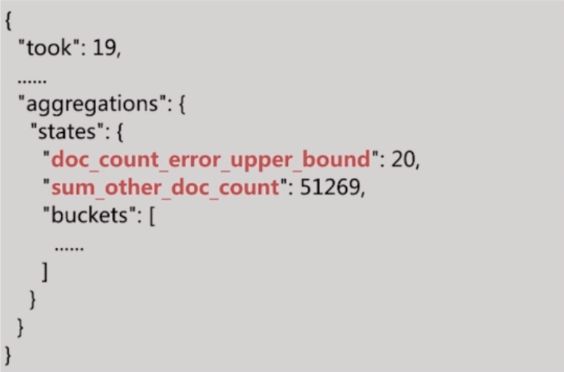

- 设定 show_term_doc_count_error 可以查看每个 bucket 误算的最大值

近似统计算法
在ES的聚合分析中,Cardinality 和 Percentile 分析使用的是近似统计算法
- 结果是近似准确的,但不一定精准
- 可以通过参数的调整使其结果精准,但同时也意味着更多的计算时间和更大的性能消耗
十、数据建模
1. 什么是数据建模
英文为Data Modeling,为创建数据模型的过程
数据模型(Data Model)
- 对现实世界进行抽象描述的一种工具和方法
- 通过抽象的实体及实体之间联系的形式去描述业务规则,从而实现对现实世界的映射
2. 数据建模的过程
- 概念模型
- 确定系统的核心需求和范围边界,设计实体和实体间的关系
- 逻辑模型
- 进一步梳理业务需求,确定每个实体的属性、关系和约束等
- 物理模型
- 结合具体的数据库产品,在满足业务读写性能等需求的前提下确定最终的定义
- Mysql、MongoDB、elasticsearch 等
- 第三范式
3. 数据建模的意义
重视数据建模
- 牵一发而动全身
4. ES中的数据建模
ES是基于Lucene以倒排索引为基础实现的存储体系,不遵循关系型数据库中的范式约定
Mapping 字段的相关设置
- enbaled
- true | false
- 仅存储,不做搜索或聚合分析
- index
- true | false
- 是否构建倒排索引
- index options
- docs I freqs I positions l offsets
- 存储倒排索引的哪些信息
- norms
- true | false
- 是否存储归一化相关参数,如果字段仅用于过滤和聚合分析,可关闭
- doc_values
- true | false
- 是否启用doc_values,用于排序和聚合分析
- field data
- false l true
- 是否为text类型启用fielddata,实现排序和聚合分析
- store
- false l true
- 是否单独存储该字段值,默认false
- coerce
- true | false
- 是否开启自动数据类型转换功能,比如字符串转为数字、浮点转为整型等
- multifields 多字段
- 灵活使用多字段特性来解决多样的业务需求
- dynamic
- true I false | strict
- 控制 mapping 自动更新
- date_detection
- true I false
- 是否自动识别日期类型
Mapping 字段属性的设定流程
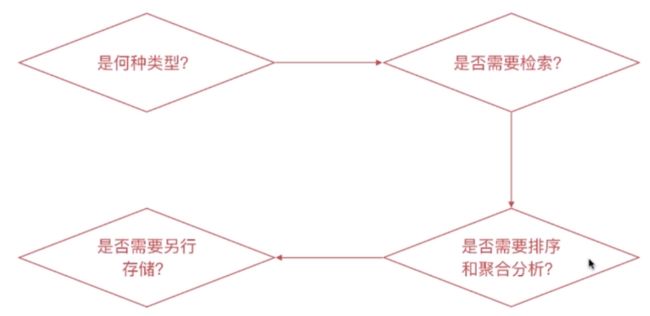
是何种类型?
- 字符串类型
- 需要分词则设定为text类型,否则设置为keyword类型
- 枚举类型
- 基于性能考虑将其设定为keyword类型,即便该数据为整型
- 数值类型
- 尽量选择贴近的类型,比如byte即可表示所有数值时,即选用byte,不要用long
- 其他类型
- 比如布尔类型、日期、地理位置数据等
是否需要检索?
- 完全不需要检索、排序、聚合分析的字段
- enabled 设置为false
- 不需要检索的字段
- index 设置为false
- 需要检索的字段,可以通过如下配置设定需要的存储粒度
- index_options 结合需要设定
- norms 不需要归一化数据时关闭即可
是否需要排序和聚合分析?
不需要排序或者聚合分析功能
- doc_values设定为false
- fielddata 设定为false
是否需要另行存储?
是否需要专门存储当前字段的数据?
- store 设定为 true,即可存储该字段的原始内容(与 _source 中的不相关)
- 一般结合_source的 enabled 设定为 false 时使用
实例
博客文章 blog_index
- 标题 title
- 发布日期 publish_date
- 作者 author
- 摘要 abstract
- 内容 content 内容非常大
- 网络地址 url
blog_index的mapping设置如下:
PUT blog_index
{
"mappings": {
"_source": {
"enabled": false
},
"properties": {
"title": {
"type": "text",
"fields": {
"kw": {
"type": "keyword"
}
},
"store": true
},
"publish_date": {
"type": "date",
"store": true
},
"author": {
"type": "keyword",
"store": true
},
"abstract": {
"type": "text",
"store": true
},
"content": {
"type": "text",
"store": true
},
"url": {
"type": "keyword",
"norms": false,
"ignore_above": 100,
"store": true,
"doc_values": false
}
}
}
}
如上设置后,_source中不会存储原始值,查询时指定要查询的字段,每个分片查询时就不会返回content字段(字段内容较大,占用内存大),提高了查询效率
GET /blog_index/_search
{
"stored_fields": [
"title",
"publish_date",
"author",
"abstract",
"url"
],
"query": {
"match": {
"content": "good"
}
},
"highlight": {
"fields": {
"content": {}
}
}
}
ES中关联关系处理
ES不擅长处理关系型数据库中的关联关系(底层存储的倒排索引,倒排索引并不适合处理关联关系),比如文章表 blog 与评论表 comment 之间通过 blog_id 关联,在ES中可以通过如下两种手段变相解决:
- Nested Object
- Parent / Child
例如:
评论 Comment
- 文章Id blogid
- 评论人username
- 评论日期 date
- 评论内容 content

关联关系处理之 Nested Object
1.直接将comment整合到blog中

2.查询结果不符合要求

3.错误原因:Comments默认是Object Array,存储结构类似下面的形式

4.Nested Object 可以解决这个问题

5.Nested查询语法

6. Nested Object Array的存储结构

关联关系处理之 Parent/Child
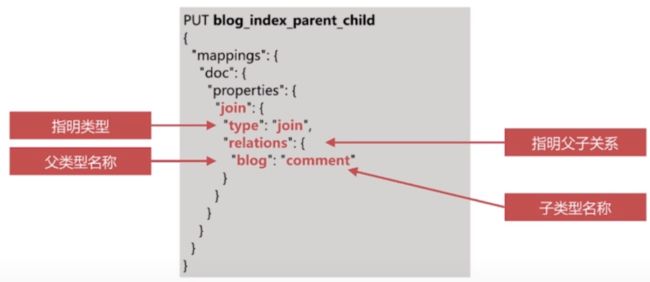
ES还提供了类似关系数据库中 join 的实现方式,使用join数据类型实现
1.创建索引时mapping配置
2.创建父/子文档

3. 常见query 语法
- parent_id 返回某父文档的子文档
- has_child 返回包含某子文档的父文档
- has_parent 返回包含某父文档的子文档
parent_id 查询:返回某父文档的子文档

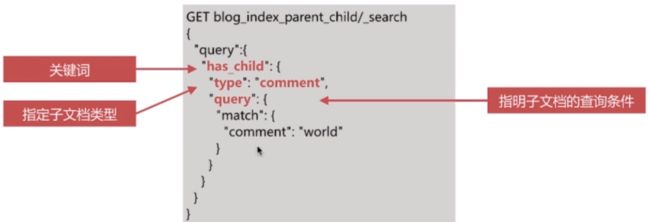
has_child 查询:返回包含某子文档的父文档
has_parent 查询:返回包含某父文档的子文档

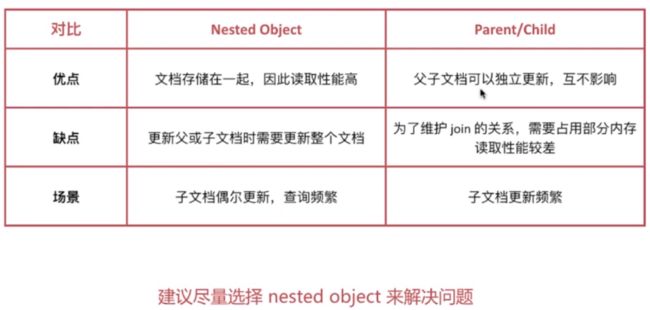
Nested Object vs Parent/Child
Reindex
指重建所有数据的过程,一般发生在如下情况:
- mapping 变更,比如字段类型变化、分词器字典更新等
- setting 变更,比如分片数更改等
- 迁移数据
ES提供了现成的API用于完成该工作
- _update_by_query 在现有索引上重建
- _reindex 在其他索引上重建
Reindex - Update By Query API

Reindex - Reindex API


Reindex - Task Management API
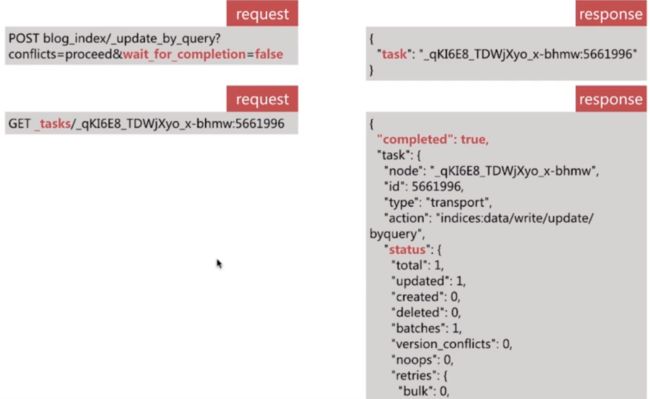
- 数据重建的时间受源索引文档规模的影响,当规模越大时,所需时间越多,此时需要通过设定url参数
wait_for_completion为false来异步执行,ES以 task 来描述此类执行任务 - ES提供了 Task API 来查看任务的执行进度和相关数据
5. ES中数据模型的一些建议
数据模型版本管理
- 对Mapping进行版本管理
- 包含在代码或者以专门的文件进行管理,添加好注释,并加入Git等版本管理仓库中,方便回顾
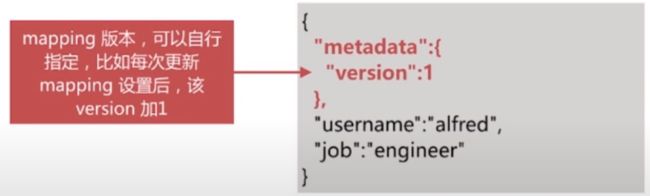
-
为每个增加一个metadata字段,在其中维护一些文档相关的元数据,方便对数据进行管理
防止字段过多
- 字段过多主要有如下的坏处:
- 难于维护,当字段成百上干时,基本很难有人能明确知道每个字段的含义
- mapping 的信息存储在 cluster state 里面,过多的字段会导致 mapping 过大,最终导致更新变慢
- 通过设置
index.mapping.total_fields.limit可以限定索引中最大字段数,默认是1000 - 可以通过 key/value 的方式解决字段过多的问题,但并不完美
- 一般字段过多的原因是由于没有高质量的数据建模导致的,比如 dynamic 设置为true
- 考虑拆分多个索引来解决问题
key/value方式详解

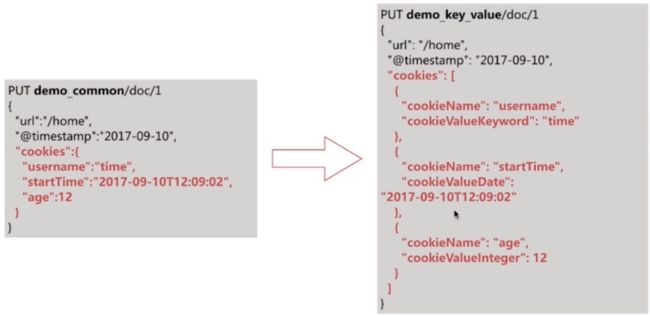

key/value方式的弊端
- 虽然通过这种方式可以极大地减少Field数目,但也有一些明显的坏处
- query语句复杂度飙升,且有一些可能无法实现,比如聚合分析相关的
- 不利于在 Kibana 中做可视化分析
十一、集群调优建议
1. 生产环境集群搭建建议 Set up Elasticsearch
系统设置要到位 Important System Configuration
-
ES设置尽量简洁
- elasticsearch.yml 中尽量只写必备的参数,其他可以通过api动态设置的参数都通过api来设定 Important Elasticsearch configuration
- 随着ES的版本升级,很多网络流传的配置参数已经不再支持,因此不要随便复制别人的集群配置参数
elasticsearch.yml 中建议设定的基本参数
cluster.name
node.name
node.master/node.data/node.ingest
network.host 建议显示指定为内网ip,不要偷懒直接设为0.0.0.0
discovery.zen.ping.unicast.hosts 设定集群其他节点地址
discovery.zen.minimum_master_nodes 一般设定为2
path.data/path.log
除上述参数外再根据需要增加其他的静态配置参数
- 动态设定的参数有transient和persistent两种设置,前者在集群重启后会丢失,后者不会,但两种设定都会覆盖 elasticsearch.yml中的配置
PUT /_cluster/settings
{
"persistent":{
"discovery.zen.minimum_master_nodes":2
},
"transient":{
"indices.store.throttle.max_bytes_per_sec":"50mb"
}
}
- 关于JVM内存设定
- 不要超过31GB,预留一半内存给操作系统,用来做文件缓存
- 具体大小根据该node要存储的数据量来估算,为了保证性能,在内存和数据量间有一个建议的比例
- 搜索类项目的比例建议在 1:16 以内
- 日志类项目的比例建议在 1:48 ~ 1:96
- 假设总数据量大小为1TB,3个 node,1个副本,那么每个 node 要存储的数据量为 2TB/
3=666GB,即700GB左右,做20%的预留空间,每个node 要存储大约850GB的数据- 如果是搜索类项目,每个node内存大小为850GB/16=53GB,大于31GB。31*16=496,即每个node 最多存储496GB数据,所以需要至少5个node
- 如果是日志类型项目,每个node内存大小为850GB/48=18GB,因此3个节点足够
2. 写性能优化
ES 写数据过程
- refresh
- translog
- flush
ES 写数据 - refresh
-
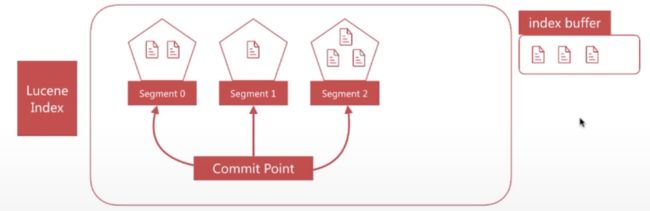
segment 写入磁盘的过程依然很耗时,可以借助文件系统缓存的特性,先将 segment 在缓存中创建并开放查询来进一步提升实时性,该过程在 es 中被称为 refresh。
-
在 refresh 之前文档会先存储在一个 buffer 中,refresh 时将 buffer 中的所有文档清空并生成 segment
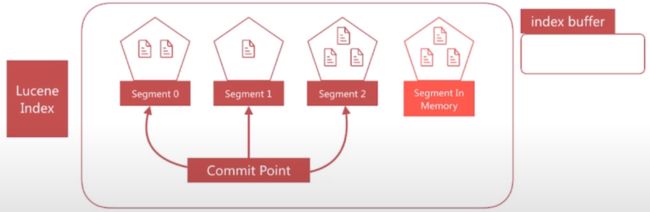
- es默认每1秒执行一次 refresh,因此文档的实时性被提高到1秒,这也是 es 被称为近实时(Near Real Time)的原因
ES写数据 - translog
- 如果在内存中的segment还没有写入磁盘前发生了宕机,那么其中的文档就无法恢复了,如何解决这个问题?
- es 引入 translog 机制。写入文档到 buffer 时,同时将该操作写入 translog。
- translog 文件会即时写入磁盘(fsync),6.x默认每个请求都会落盘,可以修改为每5秒写一次,这样风险便是丢失5秒内的数据,相关配置为index.translog.*
-
es 启动时会检查 translog 文件,并从中恢复数据
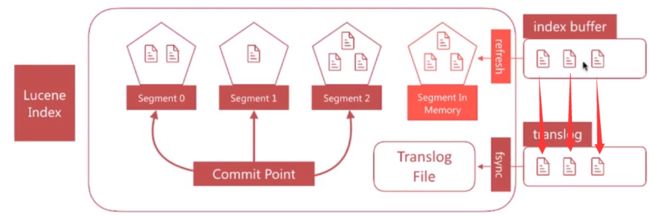
ES 写数据 - flush
- flush 负责将内存中的 segment 写入磁盘,主要做如下的工作:
- 将 translog 写入磁盘
- 将 index buffer 清空,其中的文档生成一个新的 segment,相当于一个 refresh 操作
- 更新 commit point 并写入磁盘
- 执行 fsync 操作,将内存中的 segment 写入磁盘
- 删除旧的 translog 文件
写性能优化
- 目标是增大写吞吐量 - EPS(Events Per Second)越高越好
- 优化方案
- 客户端:多线程写,批量写
- ES:在高质量数据建模的前提下,主要是在 refresh、translog 和 flush 之间做文章
写性能优化 - refresh
- 目标为降低refresh的频率
- 增大refresh_interval,降低实时性,以增大一次 refresh 处理的文档数,默认是1s,设置为-1直接禁止自动refresh
- 增大index buffer size,参数为indices.memory.index_buffer_size(静态参数,需要设定在elasticsearch.yml中),默认为10%
写性能优化 - translog
- 目标是降低 translog 写磁盘的频率,从而提高写效率,但会降低容灾能力
- index.translog.durability 设置为 async,index.translog.sync_interval 设置需要的大小,比如120s,那么 translog 会改为每120s写一次磁盘
- index.translog.flush_threshold_size 默认为512mb,即 translog 超过该大小时会触发一次 flush,那么调大该大小可以避免 flush 的发生
写性能优化 - flush
- 目标为降低flush的次数,在6.x可优化的点不多,多为es自动完成
写性能优化 - 其他
- 副本设置为0,写入完毕再增加
- 合理地设计shard数,并保证 shard 均匀地分配在所有 node 上,充分利用所有 node 的资源
- index.routing.allocation.total_shards_per_node 限定每个索引在每个node上可分配的总主副分片数
- 5个 node,某索引有10个主分片,1个副本,上述值应该设置为多少?
- (10+10)/5=4
- 实际要设置为5个,防止在某个node下线时,分片迁移失败的问题
案例 - 日志场景写性能优化
- 主要为index级别的设置优化,以日志场景举例,一般会有如下的索引设定:

3. 读性能优化
读性能主要受以下几方面影响:
- 数据模型是否符合业务模型?
- 数据规模是否过大?
- 索引配置是否优化?
- 查询语句是否优化?
读性能优化 - 数据建模
- 高质量的数据建模是优化的基础
- 将需要通过script脚本动态计算的值提前算好作为字段存到文档中
- 尽量使得数据模型贴近业务模型
读性能优化 - 数据规模
- 根据不同的数据规模设定不同的SLA
- 上万条数据与上千万条数据性能肯定存在差异
读性能优化 - 索引配置调优
- 索引配置优化主要包括如下:
- 根据数据规模设置合理的主分片数,可以通过测试得到最适合的分片数
- 设置合理的副本数目,不是越多越好
读性能优化 - 查询语句调优
- 查询语句调优主要有以下几种常见手段:
- 尽量使用Filter上下文,减少算分的场景,由于Filter有缓存机制,可以极大提升查询性能
- 尽量不使用Script进行字段计算或者算分排序等
- 结合profile、explain API分析慢查询语句的症结所在,然后再去优化数据模型
4. 其他优化
如何设定Shard数?
- ES的性能基本是线性扩展的,因此我们只要测出1个Shard的性能指标,然后根据实际性能需求就能算出需要的Shard数。比如单Shard写入eps是10000,而线上eps需求是50000,那么你需要5个shard。(实际还要考虑副本的情况)
- 测试1个Shard的流程如下:
- 搭建与生产环境相同配置的单节点集群
- 设定一个单分片零副本的索引
- 写入实际生产数据进行测试,获取写性能指标
- 针对数据进行查询请求,获取读性能指标
- 压测工具可以采用 esrally
- 压测的流程还是比较复杂,可以根据经验来设定。如果是搜索引擎场景,单Shard大小不要超过15GB,如果是日志场景,单Shard大小不要超过50GB(Shard越大,查询性能越低)
- 此时只要估算出你索引的总数据大小,然后再除以上面的单Shard大小也可以得到分片
5. 监控
X-Pack Monitoring
- 官方推出的免费集群监控功能
- kibana7.0可以自动安装x-pack