38.机器学习应用-工作流梯度提升决策树回归分类算法
1、简介
GBT(Gradient-Boosted Trees)或GBDT(Gradient-Boosted Decision Trees)
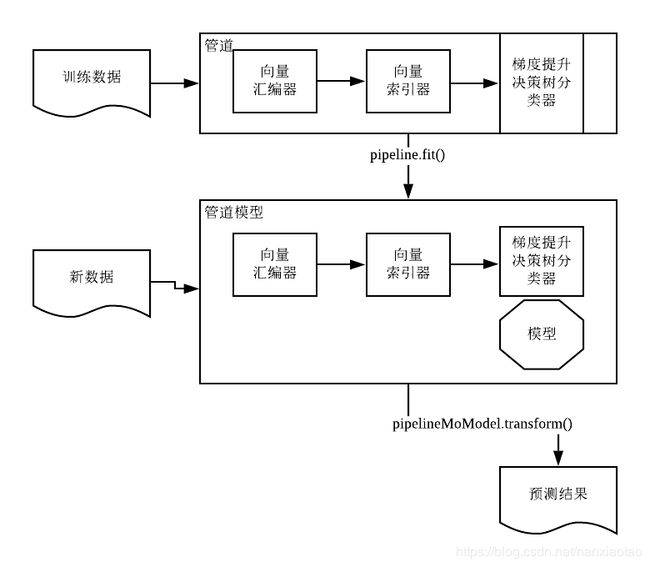
二、基于Spark ML的实现
import sys
from pyspark.sql.functions import udf
from pyspark.sql.functions import col
from pyspark.sql import SQLContext
from pyspark import SparkConf, SparkContext
from pyspark.sql.session import SparkSession
from pyspark.ml import Pipeline
from pyspark.ml.feature import StringIndexer, VectorIndexer,VectorAssembler
from pyspark.ml.regression import DecisionTreeRegressor
from pyspark.ml.evaluation import BinaryClassificationEvaluator
from pyspark.ml.tuning import ParamGridBuilder,TrainValidationSplit
from pyspark.ml.tuning import CrossValidator
from pyspark.sql.types import StringType,StructField,StructType
from pyspark.ml.evaluation import MulticlassClassificationEvaluator
from pyspark.ml.evaluation import RegressionEvaluator
from pyspark.ml.regression import GBTRegressor
def SetLogger( sc ):
logger = sc._jvm.org.apache.log4j
logger.LogManager.getLogger("org"). setLevel( logger.Level.ERROR )
logger.LogManager.getLogger("akka").setLevel( logger.Level.ERROR )
logger.LogManager.getRootLogger().setLevel(logger.Level.ERROR)
def SetPath(sc):
global Path
if sc.master[0:5]=="local" :
Path="file:/home/hduser/pythonwork/PythonProject/"
else:
Path="hdfs://master:9000/user/hduser/"
def CreateSparkContext():
sparkConf = SparkConf() \
.setAppName("MLPiplineGBTRegressor") \
.set("spark.ui.showConsoleProgress", "false")
sc = SparkContext(conf = sparkConf)
print ("master="+sc.master)
SetLogger(sc)
SetPath(sc)
return (sc)
def replace_question(x):
return ("0" if x=="?" else x)
if __name__ == "__main__":
replace_question= udf(replace_question)
print("MLPiplineGBTRegressor")
print("========initing the sparkContext========")
sc=CreateSparkContext()
#sqlContext=sc.getOrCreate()
#sqlContext=SparkSession.Builder.getOrCreate(s);
#import the data
print("========initing the sqlContext========")
sqlContext=SQLContext(sc)
print("========reading the data========")
hour_df= sqlContext.read.format('csv') \
.option("header", 'true').load(Path+"data/hour.csv")
hour_df=hour_df.drop("instant").drop("dteday") \
.drop('yr').drop("casual").drop("registered")
hour_df= hour_df.select([ col(column).cast("double").alias(column)
for column in hour_df.columns])
#print(row_df.take(5))
print("========generate the train datasets and test datasets========")
train_df, test_df = hour_df.randomSplit([0.7, 0.3])
train_df.cache()
test_df.cache()
featuresCols = hour_df.columns[:-1]
vectorAssembler = VectorAssembler(inputCols=featuresCols, outputCol="aFeatures")
vectorIndexer = VectorIndexer(inputCol="aFeatures", outputCol="features", maxCategories=24)
gbt = GBTRegressor(labelCol="cnt",featuresCol= 'features')
gbt_pipeline = Pipeline(stages=[vectorAssembler,vectorIndexer,gbt])
print("========start to training========")
gbt_pipelineModel = gbt_pipeline.fit(train_df)
print("========start to transforming========")
predicted_df=gbt_pipelineModel.transform(test_df)
print("========评估模型的准确率========")
evaluator = RegressionEvaluator(metricName="rmse", labelCol='cnt', predictionCol='prediction')
rmse = evaluator.evaluate(predicted_df)
print("rms:"+str(rmse))
print("使用TrainValidation进行训练评估找出最佳模型")
paramGrid = ParamGridBuilder()\
.addGrid(gbt.maxDepth, [ 5,10,15,25])\
.addGrid(gbt.maxBins, [25,35,45,50])\
.build()
tvs = TrainValidationSplit(estimator=gbt,evaluator=evaluator,
estimatorParamMaps=paramGrid,trainRatio=0.8)
tvs_pipeline = Pipeline(stages=[vectorAssembler,vectorIndexer ,tvs])
tvs_pipelineModel =tvs_pipeline.fit(train_df)
bestModel=tvs_pipelineModel.stages[2].bestModel
predictions = tvs_pipelineModel.transform(test_df)
rmse= evaluator.evaluate(predictions)
print("rmse:"+str(rmse))
print("使用crossValidation进行训练评估找出最佳模型")
paramGrid = ParamGridBuilder() \
.addGrid(gbt.maxDepth, [ 5,10])\
.addGrid(gbt.maxBins, [25,40])\
.addGrid(gbt.maxIter, [10, 50])\
.build()
cv = CrossValidator(estimator=gbt, evaluator=evaluator,
estimatorParamMaps=paramGrid, numFolds=3)
cv_pipeline = Pipeline(stages=[vectorAssembler, vectorIndexer, cv])
cv_pipelineModel = cv_pipeline.fit(train_df)
cvm=cv_pipelineModel.stages[2]
gbestModel=cvm.bestModel
evaluator = RegressionEvaluator(metricName="rmse",
labelCol='cnt', predictionCol='prediction')
rmse = evaluator.evaluate(predicted_df)
print("rmse:"+str(rmse))
19/06/02 17:17:25 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
]0;IPython: pythonwork/PythonProjectMLPiplineGBTRegressor
========initing the sparkContext========
master=spark://master:7077
========initing the sqlContext========
========reading the data========
========generate the train datasets and test datasets========
========start to training========
========start to transforming========
========评估模型的准确率========
rms:76.5312809344