[行为识别]RPAN:An end-to-end recurrent pose-attention network for action recognition
这篇文章是来自中科院深圳先进院乔宇老师,ICCV2017年的oral文章《RPAN:An End-to-End Recurrent Pose-Attention Network for Action Recognition in Videos》。这篇文章的出发点是当前行为识别的一大流行方向:RNN。与之前的video-level category 训练RNN不相同。这篇文章提出了引入pose-attention的RNN。文章总结共有以下几个贡献点:
- 不同于之前的pose-related action recognition,这篇文章是端到端的RNN,而且是spatial-temporal evolutionos of human pose
- 不同于独立的学习关节点特征(human-joint features),这篇文章引入的pose-attention机制通过不同语义相关的关节点(semantically-related human joints)分享attention参数,然后将这些通过human-part pooling层联合起来
- 视频姿态估计,通过文章的方法可以给视频进行粗糙的姿态标记。(这个方法还挺不错)。
一、网络结构
整个网络框架可以分成三个大的部分:
- 特征生成部分:Conv Feature cube from CNN
- 姿态注意机制:Pose-Attention Mechanism
- LSTM:RNN网
下面是整体网络结构图。
![[行为识别]RPAN:An end-to-end recurrent pose-attention network for action recognition_第1张图片](http://img.e-com-net.com/image/info8/1994e18929484e2ea0a87c83af08fe6e.jpg)
1.1 Convolution Feature Cube from CNN
作者采用了 two-stream CNN[1]的网络框架,生成了convolution cubes。包含空间和时间上的。这里可以参考 下面列的参考文献[1],或者直接看之前的文章。Two –Stream CNN for Action Recognition in Videos
1.2 Pose Attention Mechanism(姿态注意机制)
Step1:
经过上述two-stream cnn后生成了 K1 x K2 x dc的特征图,文章中叫convolutional cube。然后作者定义了一个Ct,表示第t个视频帧在不同空间位置上的特征向量。空间图是K1xK2的大小,共dc个通道。所以Ct是K1xk2个dc维的向量。Ct的定义如下。
![]()
Step2:
作者定义了一些关节点,总共有13个。然后由这13个关节点,作者定义了5个身体的part。定义如下图所示。
![[行为识别]RPAN:An end-to-end recurrent pose-attention network for action recognition_第2张图片](http://img.e-com-net.com/image/info8/63549c0e1b534e2b9ad1c5660e2f5816.jpg)
- 首先,作者计算了每个关节点在每个空间点(K1xK2的大小)上的打分
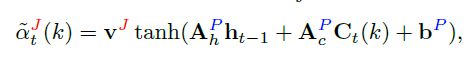
然后进行了归一化。
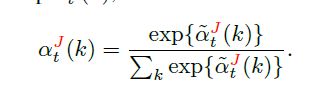
- 根据关节点特征,然后生成part的特征
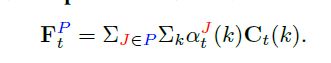
Step3:
经过pooling层,将所有part特征整合到一起。使用的方法就是简单的Max,Mean or Concat。请参考上图。
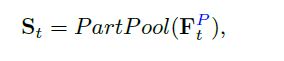
1.3 LSTM
最后将St输入到LSTM网络中。
![[行为识别]RPAN:An end-to-end recurrent pose-attention network for action recognition_第3张图片](http://img.e-com-net.com/image/info8/68d6653240884f33933a1e5475786708.jpg)
1.4 Loss Function
这里作者做了一个联合Loss Function,成为端到端的训练。
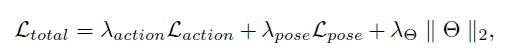
其中的theta是模型参数的衰减。
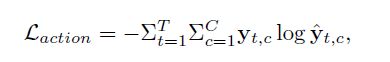
action Loss是一个交叉熵,标签yt是一个one-hot label。
![]()
重点是这里的pose loss function。其中的M就是作者他们提出的一种标记方法得到的(Head maps for all the joints)。
二、实验结果
2.1 Pose Attention Mechanism
Case1:
首先,作者测试了姿态注意机制的作用。画出了没有attention机制的时候测试结果的混淆矩阵,然后画出了有attention机制时候的测试结果的混淆矩阵。显然有attention机制的时候,效果要好。
![[行为识别]RPAN:An end-to-end recurrent pose-attention network for action recognition_第4张图片](http://img.e-com-net.com/image/info8/2dfad886d4ec407b8b3319281401489b.jpg)
Case2:
接着,作者测试了以下不同Human-part-pooling方式的影响。
![[行为识别]RPAN:An end-to-end recurrent pose-attention network for action recognition_第5张图片](http://img.e-com-net.com/image/info8/daf76e3c25e745f5ba5531a68205691d.jpg)
2.2 Different CNNs
作者还着重测试了不同CNNs网络对于性能的影响。
![[行为识别]RPAN:An end-to-end recurrent pose-attention network for action recognition_第6张图片](http://img.e-com-net.com/image/info8/55d7031c24904046a0fbb35cd86331ac.jpg)
2.3 最终结果比较
最后,作者测试了之前的state of art 和 RPAN网络进行了对比。
![[行为识别]RPAN:An end-to-end recurrent pose-attention network for action recognition_第7张图片](http://img.e-com-net.com/image/info8/3b0021b1e95b474f95287cd7301e4667.jpg)
参考文献
[1] Simonyan K, Zisserman A. Two-stream convolutional networks for action recognition in videos[C]//Advances in neural information processing systems. 2014: 568-576.
[2] Wang L, Xiong Y, Wang Z, et al. Towards good practices for very deep two-stream convnets[J]. arXiv preprint arXiv:1507.02159, 2015.
[3] Du W, Wang Y, Qiao Y. Rpan: An end-to-end recurrent pose-attention network for action recognition in videos[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 3725-3734.
<个人网页blog已经上线,一大波干货即将来袭:https://faiculty.com/>
/* 版权声明:公开学习资源,只供线上学习,不可转载,如需转载请联系本人 .*/