Android SparseArray和LruCache
Android SparseArray和LruCache
- 一 HashMap
- 二 SparseArray
- 三 LinkedHashMap
- 四 LruCache
一 HashMap
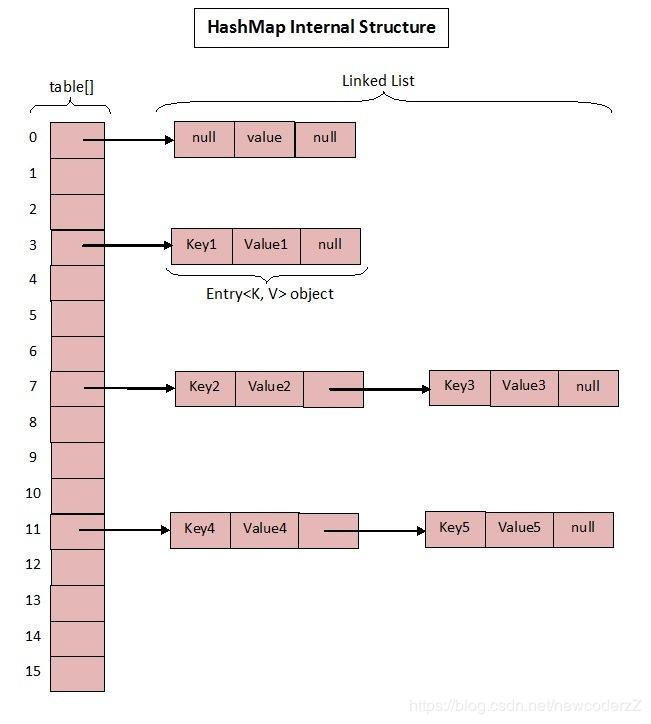
HashMap是数组和链表的结合体,被称为链表散列.
HashMap插入的时候,
- 1、先根据 key 计算出 hashcode
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
- 2、根据计算出的 hashcode 定位出所在桶。
- 3、如果桶是一个链表则需要遍历判断里面的 hashcode、key 是否和传入 key 相等,如果相等则进行覆盖,并返回原来的值。如果桶是空的,说明当前位置没有数据存入;新增一个 Entry 对象写入当前位置。
当然以上插入是JDK1.8之前的HashMap的实现方式,JDK1.8当同一个桶的链表长度太长时,链表会进化成红黑树,然后还要按照红黑树的插入规则来操作。
在JDK1.6,JDK1.7中,HashMap采用位桶+链表实现,即使用链表处理冲突,同一hash值的链表都存储在一个链表里。但是当位于一个桶中的元素较多,即hash值相等的元素较多时,通过key值依次查找的效率较低。而JDK1.8中,HashMap采用位桶+链表+红黑树实现,当链表长度超过阈值(8)时,将链表转换为红黑树,这样大大减少了查找时间。
- JDK1.7 HashMap结构
- JDK1.8 HashMap结构

(图片来源来网络,侵权必删)
影响HashMap性能的两个因素,capcity(容量)和loadFactor(加载因子)。容量太大、加载因子太小就会造成空间的浪费,容量太小或者加载因子太大,会造成HashMap的插入和查找效率降低,并且还会导致HashMap扩容频繁,更加影响性能。默认的capcity是16,加载因子是0.75。
都说到HashMap了,这里稍微聊一下ConcurrentHashMap吧,其实我做Android开发的时候ConcurrentHashMap平时用的并不多,这里只是简单引用介绍一下。
和 HashMap 非常类似,唯一的区别就是其中的核心数据如 value ,以及链表都是 Volatile 修饰的,保证了获取时的可见性。
原理上来说:ConcurrentHashMap 采用了分段锁技术,其中 Segment 继承于 ReentrantLock。不会像 HashTable 那样不管是 put 还是 get 操作都需要做同步处理,理论上 ConcurrentHashMap 支持 CurrencyLevel (Segment 数组数量)的线程并发。每当一个线程占用锁访问一个 Segment 时,不会影响到其他的 Segment。
ConcurrentHashMap 的 get 方法是非常高效的,因为整个过程都不需要加锁。
JDK1.8抛弃了原有的 Segment 分段锁,而采用了 CAS + synchronized 来保证并发安全性
二 SparseArray
SparseArrays map integers to Objects. Unlike a normal array of Objects,
there can be gaps in the indices. It is intended to be more memory
efficientthan using a HashMap to map Integers to Objects, both because
it avoidsauto-boxing keys and its data structure doesn't rely on an
extra entry object for each mapping.
SparseArray是int和Object的映射,它比HashMap有更高的内存效率。
- 1、避免了自动装箱(auto-boxing ),
- 2、SparseArray的每次映射(map)也不需要依赖额外的Entry块(HashMap的插入和查找需要一个Entry来间接实现的),SparseArray不需要开辟内存空间来额外存储外部映射,从而节省内存。
SparseArray,翻译过来就是稀疏数组,看到稀疏两个字,我就在想这个玩意和稀疏矩阵有关系吗?查看了一下源码和网上介绍SparseArray的文章,还真是,其实SparseArray就是稀疏矩阵,并且用三元组来表示的。

(借用网上的一张图,侵权必删)
从图中可以看出,对于数组A来说,其实它只有7个有效数据,其他位置都是空的,因此就造成了空间的极大浪费,这个时候就需要给数组A来换一种表示方式了。三元组顾名思义就是有三个元数据的数组,元数据就是 ( i , j , v a l u e ) (i, j, value) (i,j,value)的形式。稀疏矩阵转换成三元组后,i和j就表示数据原来在数组A中的位置信息(第 i 行,第 j 列),value就是 A [ i ] [ j ] A[i][j] A[i][j] 的值。这样就大大节省了空间。
那么SparseArray是如何做的呢?SparseArray的一个item就是和HashMap类似的,(key,value)的形式。然后它有两个数组,
private int[] mKeys;
private Object[] mValues;
private int mSize;
mKeys数组来存放key,mValues用来存放value。每次插入或者查找都是通过二分法找到要插入或者查找的key在数组mKeys中的下标position,要插入或者查找的value就存储在数组mValues中对应的postion位置,即 v a l u e = m V a l u e s [ p o s i t i o n ] value = mValues[position] value=mValues[position]
因为SparseArray的插入和删除实现都是用二分查找实现的,因此时间效率上要比HashMap要低。总结来说就是SparseArray相对于HashMap牺牲了部分效率来换取空间的优化。数据量小于1000选着SparseArray比较好。
三 LinkedHashMap
LinkedHashMap继承与HashMap,所以HashMap拥有的功能,LinkedHashMap也都拥有。那么LinkedHashMap有哪些HashMap不具有的功能呢?我们都知道HashMap是无序的,当我们希望有顺序地去存储key-value时,就需要使用LinkedHashMap了。而LinkedHashMap本身其实还是一个双向循环链表。看图

总结
- LinkedHashMap是继承于HashMap,是基于HashMap和双向链表来实现的。
- HashMap无序;LinkedHashMap有序,可分为插入顺序和访问顺序两种。如果是访问顺序,那put和get操作已存在的Entry时,都会把Entry移动到双向链表的表尾(其实是先删除再插入)。
- LinkedHashMap存取数据,还是跟HashMap一样使用的Entry[]的方式,双向链表只是为了保证顺序。
- LinkedHashMap是线程不安全的。
四 LruCache
LruCache,(Least Recently Used cache),LRU是近期最少使用的算法,它的核心思想是当缓存满时,会优先淘汰那些近期最少使用的缓存对象。简单来说就是近期使用频繁的对象优先级会比较高,使用不频繁的对象则优先级低。
LruCache内部维护了一个LinkedHashMap,而更新Object的使用优先级的实现其实主要是在LinkedHashMap中实现的,LinkedHashMap的构造函数
public LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder)
前两个参数和HashMap是一样的,第三个参数accessOrder,表示LinkedHashMap是顺序访问,当对已存在LinkedHashMap中的Entry进行get和put操作时,会把Entry移动到双向链表的表尾(其实是先删除,再插入)。这里就相当于最近访问的优先级高,所以LruCache正式利用了LinkedHashMap的这种特性。