Spark数据倾斜问题
Spark数据倾斜问题
- 1.数据倾斜问题现象
- 2. 原因分析
- 2.1 数据问题
- 2.2 spark使用问题
- 3. 数据层面分析
- 4. 解决方案
1.数据倾斜问题现象
现象1:多数task执行速度较快,少数task执行时间非常长,一直卡在某一个stage达几小时或者几分钟之久,或者等待很长时间后提示你内存不足,执行失败。

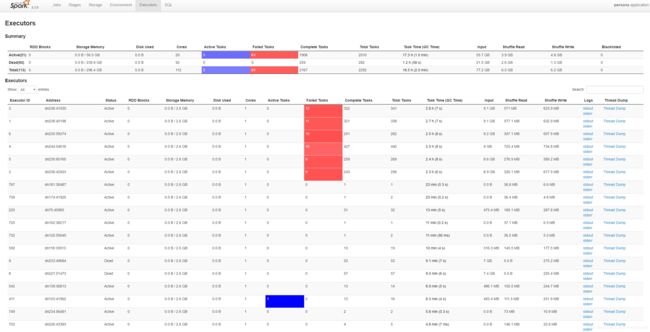
图中可以很明显的看出是卡在reduceByKey的算子上。
现象2:Consider boosting spark.yarn.executor.memoryOverhead.
很幸运,昨天因为数据倾斜导致某task执行缓慢,今天任务直接失败,虽然不是同一个地方,原因还是数据倾斜.
# 错误代码
2019-01-24 07:56:34 ERROR YarnScheduler:70 - Lost executor 1552 on dn233: Container killed by YARN for exceeding memory limits. 13.0 GB of 13 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead.
2019-01-24 08:08:40 ERROR YarnScheduler:70 - Lost executor 1692 on dn222: Container killed by YARN for exceeding memory limits. 13.0 GB of 13 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead.
2019-01-24 08:12:11 ERROR YarnScheduler:70 - Lost executor 1587 on dn207: Container killed by YARN for exceeding memory limits. 13.0 GB of 13 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead.
2019-01-24 08:12:11 ERROR TaskSetManager:70 - Task 232 in stage 95.0 failed 4 times; aborting job
Traceback (most recent call last):
File "/home/workspace/***/push/push.py", line 195, in <module>
result_rdd = run_push_game()
File "/home/workspace/***/push/push.py", line 178, in run_push_game
print_n_rdd(result_rdd, 'result_rdd')
File "/logs/workspace/***/push/utils.py", line 102, in print_n_rdd
print "\n\n\n%s----------logName: %s--------------------count:%d \n" % (time_info(), name, rdd.count())
File "/home/workspace/spark-2.3.0-bin-hadoop2.6/python/lib/pyspark.zip/pyspark/rdd.py", line 1056, in count
File "/home/workspace/spark-2.3.0-bin-hadoop2.6/python/lib/pyspark.zip/pyspark/rdd.py", line 1047, in sum
File "/home/workspace/spark-2.3.0-bin-hadoop2.6/python/lib/pyspark.zip/pyspark/rdd.py", line 921, in fold
File "/home/workspace/spark-2.3.0-bin-hadoop2.6/python/lib/pyspark.zip/pyspark/rdd.py", line 824, in collect
File "/home/workspace/spark-2.3.0-bin-hadoop2.6/python/lib/py4j-0.10.6-src.zip/py4j/java_gateway.py", line 1160, in __call__
File "/home/workspace/spark-2.3.0-bin-hadoop2.6/python/lib/pyspark.zip/pyspark/sql/utils.py", line 63, in deco
and returns value, otherwise it returns Null.
File "/home/workspace/spark-2.3.0-bin-hadoop2.6/python/lib/py4j-0.10.6-src.zip/py4j/protocol.py", line 320, in get_return_value
py4j.protocol.Py4JJavaError: An error occurred while calling z:org.apache.spark.api.python.PythonRDD.collectAndServe.
: org.apache.spark.SparkException: Job aborted due to stage failure: Task 232 in stage 95.0 failed 4 times, most recent failure: Lost task 232.2 in stage 95.0 (TID 5930, dn207, executor 1587): ExecutorLostFailure (executor 1587 exited caused by one o
f the running tasks) Reason: Container killed by YARN for exceeding memory limits. 13.0 GB of 13 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead.
Driver stacktrace:
标重点:
ExecutorLostFailure (executor 1587 exited caused by one of the running tasks)
Reason: Container killed by YARN for exceeding memory limits. 13.0 GB of 13 GB physical memory used.
Consider boosting spark.yarn.executor.memoryOverhead.
So what should I do make sure that my data are (roughly) balanced across partitions?
-解决方案:repartition(),进行重新分区
scala> val data = sc.parallelize(1 to 3, 3).mapPartitions { it => (1 to it.next * 1000).iterator }
data: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[6] at mapPartitions at <console>:24
scala> data.mapPartitions { it => Iterator(it.toSeq.size) }.collect.toSeq
res1: Seq[Int] = WrappedArray(1000, 2000, 3000)
scala> data.repartition(3).mapPartitions { it => Iterator(it.toSeq.size) }.collect.toSeq
res2: Seq[Int] = WrappedArray(1999, 2001, 2000)
scala> data.repartition(6).mapPartitions { it => Iterator(it.toSeq.size) }.collect.toSeq
res3: Seq[Int] = WrappedArray(999, 1000, 1000, 1000, 1001, 1000)
scala> data.repartition(12).mapPartitions { it => Iterator(it.toSeq.size) }.collect.toSeq
res4: Seq[Int] = WrappedArray(500, 501, 501, 501, 501, 500, 499, 499, 499, 499, 500, 500)
2. 原因分析
常见于各种shuffle操作,例如reduceByKey,groupByKey,join等操作。
2.1 数据问题
- key本身分布不均匀(包括大量的key为空)
- key的设置不合理
2.2 spark使用问题
- shuffle时的并发度不够
- 计算方式有误
3. 数据层面分析
# 在进行reduceByKey之前,把key映射出来,单独分析,就是统计各key的数据记录数,排序。下面是一个伪代码
rdd.map(lambda x: (x[0],1)).reduceBykey(_+_).sortByKey(false).take(10)
>>>[1161529, 504254, 368048, 293200, 208376, 193276, 190625, 170100, 119908, 119233, 117858, 116640, 92415, 92070, 80352, 77372, 74008, 69575, 65780, 61731, 61402, 56448, 55815, 55796, 55660, 54725, 53790, 53312, 53185, 52920, 48400, 47880, 47040, 46551, 45486, 45375, 45124, 44944, 44496, 43904, 43904, 43890, 43740, 42760, 42421, 42334, 42250, 42029, 41760, 41690, 41665, 40992, 40824, 39933, 39312, 38304, 37908, 37856, 36960, 36600, 36414, 36366, 36300, 36240, 36000, 35904, 35739, 35359, 35032, 34596, 34344, 33687, 33640, 32964, 32630, 32436, 31978, 31416, 31360, 30996, 30800, 30628, 30600, 30250, 30210,...
综上分析,每个key对应的记录数差距还是非常大的,多则116万,少则20-30条,造成严重的数据倾斜。
4. 解决方案
Spark在做Shuffle时或者分组时,默认使用HashPartitioner(非Hash Shuffle)对数据进行分区,也就是对key取hash,如果某一个key包含的记录数非常多,就会造成该区的记录数极其的多,导致数据倾斜,执行缓慢。这里就是要对同样的key采用随机数的方法,变成不同的key,处理过程中再进行分区的时候,就能解决分到同一个区。
如果使用reduceByKey因为数据倾斜造成运行失败的问题。具体操作如下:
- 将原始的 key 转化为 key + 随机值(例如Random.nextInt)
- 对数据进行 reduceByKey(func)
- 将 key + 随机值 转成 key
- 再对数据进行 reduceByKey(func)
具体代码
import random
# 更具数据量的大小和倾斜程度适当调节10000这个数的大小,就是对id后面加个数字字符串
.map(lambda x: (x[0]+'_%s' % random.randint(1, 10000), x[1]))