前言
mysql 是我工作中常用的数据库,不过仅限于 SQL 操作,通过阿里云的 RDS 可以快速生成一个实例,对于其原理并不甚了解,所以闲暇之余了解了一下,并记录下来,与大家共享、交流。
目录
-
- 前言
- 目录
- 一、MySQL复制技术
- 1. 复制的用途
- 2. 复制存在的问题
- 3. 复制的原理
- 4. 复制技术
- 二、MySQL 主从复制的实现
- 1. 安装并启动
- 2. 编辑配置文件
- 3. 配置主从复制
- 4. 测试宕机
- 三、双主复制
- 四、读写分离
- 1. 安装包准备和环境配置
- 2. 配置 mycat 虚拟数据库
- 3. 总结
- 后记
一、MySQL复制技术
1. 复制的用途
- 实时灾备,用于故障切换
- 可创建读写分离,提供更好的查询服务
- 把备份等操作都放在从服务器上进行,减少对业务的影响
2. 复制存在的问题
- 主库宕机后,数据可能丢失
- 从库只有一个sql Thread,主库写压力大时,复制很可能延时
- 一主多从,从机不宜过多,主服务器需要同时向多台服务器中写入数据,压力会很大,这个时候推荐使用集群技,这个我之后会试做,在此不做描述
至于宕机后怎么做,复制延迟怎么解决,就不提了,因为我也没遇到过,不敢信口胡说。网上有好多大神给出了这些问题的解决方案,需要时可借鉴一下。
3. 复制的原理
- MySQL 主从复制(replication)是一个异步的复制过程。从一个实例(Master)复制到另一个实例(Slave),整个过程需要由 Master 上的 IO 进程 和 Slave 上的 Sql 进程 与 IO 进程 共同完成。
- 首先 Master 端必须打开 binary log(bin-log),因为整个复制过程实际上就是 Slave 端从 Master 端获取相应的二进制日志,然后在本地完全顺序的执行日志中所记录的各种操作。
原理图如下:

主从复制过程:
1. Slave 端的 IO 进程连接上 Master,向 Master 请求指定日志文件的指定位置(或者从最开始的日志)之后的日志内容;
2. Master 接收到来自 Slave 的 IO 进程的请求后,负责复制的 IO 进程根据 Slave 的请求信息,读取相应日志内容,返回给 Slave 的IO进程,并将本次请求读取的 bin-log 文件名及位置一起返回给 Slave 端;
3. Slave 端的 IO 进程接收到信息后,将接收到的日志内容依次添加到 Slave 端的 relay-log(中继日志) 文件的最末端,并将读取到的 Master 端的 bin-log 的文件名和位置记录到 master-info 文件中,以便在下一次读取的时候能够清楚的告诉 Master :”我需要从某个 bin-log 的哪个位置开始往后的日志内容,请发给我”;
4. Slave 端的 Sql 进程检测到 relay-log (中继日志)中新增加了内容后,会马上解析 relay-log 的内容成为在 Master 端真实执行时候的那些可执行的内容,并在本地执行。
>
过程产生三个线程(thread):
两个 IO线程:主库会创建一个线程,用来发送 binlog 内容到从库;从库I/O线程读取主库的 binlog 输出线程发送的更新并拷贝这些更新到本地文件,其中包括 relay-log(中继日志) 文件
一个 SQL线程:SQL负责将中继日志应用到 slave 数据库中,完成 AB (主从)复制数据同步。
主从复制的方式:
1) 同步复制:
Master 服务器操作完成,当操作作为事件写入二进制日志,传递给 slave,存放到中继日志中,然后在本地执行完操作,即反馈同步成功
2) 半同步复制:
主库在执行完客户端提交的事务后不是立刻返回给客户端,而是等待至少一个从库接收到并写到relay log中才返回给客户端。
该功能不是 mysql 官方提供的,是5.5版本时由 google 研发半同步补丁后支持,需要 semi 插件
3) 异步复制:
主库在执行完客户端提交的事务后会立即将结果返给给客户端,并不关心从库是否已经接收并处理
4. 复制技术
传统复制技术
主从复制,默认是通过pos复制(postion),就是说在日志文档里,将用户进行的每一项操作都进行编号(pos),每一个event都有一个起始编号,一个终止编号。我们在配置主从复制时从节点时,要输入master的log_pos值就是这个原因,要求它从哪个pos开始同步数据库里的数据,这是传统复制技术。基于GDIT的复制技术(MySQL5.6 版本之后才出现)
gtid: global transaction id (全局事务编号)
启用 GTID 功能之后,MySQL服务器在二进制日志文件中记录每一个操作时,每一个操作都有一个唯一的ID,就叫作GTID,它由 server_uuid + gtid 组成。
这里参考Groot的博客讲解的很明白。GTID 的优、缺点:
这里参考了张冲andy的博客,总结的比较好。
二、MySQL 主从复制的实现
我在搭建了一个 LAMP 架构的模拟QQ农场后,想起主从复制的问题,所以在此基础上,创建了从主机,过程记录在此。
这次就是一个测试学习的过程,所以一切从简,基于 centos7.4 的系统环境,全部用网络源安装所需资源包(数据库是我自定义的 repo,是 MySQL5.7.18 版本)。
1. 安装并启动
安装
master 端,检查是否安装了 mariadb 数据库,有的话先用命令rpm -e --nodeps mariadb...卸载
slave 端,方法同 master 端。
启动
systemctl start mysqld && systemctl enable mysqld
查看启动状态
2. 编辑配置文件
mkdir -p /mydata/binlog/master
chown -R mysql.mysql /mydata # 这一步很重要,否则mysql重启失败
vim /etc/my.cnf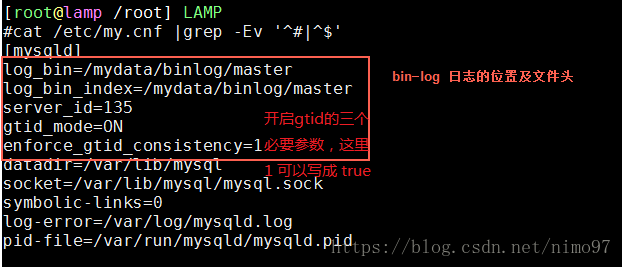
master 端和 slave 端的 server_id 不可一样,一般用 ipv4 的 IP 末位来标志。
- 重启 mysqld 服务。
systemctl restart mysqld
3. 配置主从复制
# 将 slave 端的库内容与 master 端同步,执行如下步骤
master 端:
mysqldump -uroot -p --all-databases >> /root/all.sql
slave 端:
mysql -uroot -p < all.sql

# 在master端为slave授权
mysql> grant replication slave on *.* to 'slave'@'$IP' identified by 'password';
# 从slave端登陆测试
mysql -uslave -p -h $IP
# master端查询一些参数
mysql> select @@server_uuid; # 这里的值和slave端不可一致,有的人用克隆机做的,这样的话修改其中一台机器的这个值就可以了
mysql> show master status;
mysql> show binlog events in "File列的值";# slave 端部署
mysql> select @@server_uuid; # 确认与master端不一样
mysql> show global variables like "%gtid%"; # 确认gtid已经开启
mysql> change master to
-> MASTER_HOST='192.168.40.135',
-> MASTER_USER='slave',
-> MASTER_PASSWORD='...',
-> MASTER_AUTO_POSITION=1;
mysql> start slave;
mysql> show slave status;
以下是slave端的操作: 

到此就可以做测试了,在 master 端执行 DML(data manipulation language) 语句,在slave端看到数据的同步即是成功了。 


4. 测试宕机
停掉slave的 mysql 服务,在master端执行DML(data manipulation language) 语句,重启slave端的服务,发现数据是同步的。 
master 停掉 mysql 服务,应用切换到从数据库,可以用 keepalived 来配置并实现,在此不做描述。
三、双主复制
本次测试不需要双主,不过这个功能的实现也很容易,就当做几条命令的笔记在这了。
实现了上面的操作,双主复制就很好操作了,如下:
# 在master端给自己授权
mysql> grant replication slave on *.* to 'master'@'192.168.40.%' identified by 'password';
# 在slave端
mysql> show master status;
查得 log_file 和 log_pos 的值
# 指定master主机
mysql> change master to
-> MASTER_HOST='192.168.40.138', # slave 端的地址
-> MASTER_USER='master',
-> MASTER_PASSWORD='...',
-> MASTER_LOG_FILE="slave.000001",
-> MASTER_LOG_POS=154;
mysql> start slave;
mysql> show slave status;
测试双主复制,略…
四、读写分离
实现读写分离的中间件有好多,例如:
mysql-proxy
Atlas —— 360
amoeba ——— 阿里的
mycat
…
本次测试操作,读写分离应用中间件 mycat 实现。
1. 安装包准备和环境配置
- GitHub 上下载 mycat
- java 官网下载 jdk
- 配置服务
# 卸载系统自带jdk
rpm -qa | grep -E 'gcj|jdk'
rpm -e --nodeps java-1.8.0-openjdk-headless java-1.8.0-openjdk java-1.7.0-openjdk java-1.7.0-openjdk-headless
# 解压到 /usr/local 目录下
tar -xf filename -C /usr/local/java
tar -xf filename -C /usr/local/mycat
# 创建用户
useradd -s /sbin/nologin -M mycat
chown -R mycat.mycat /usr/local/mycat
chown -R root.root /usr/local/java
# 配置全局变量
vim /etc/profile
[root@lamp /root] LAMP
# tail -5 /etc/profile
export JAVA_HOME=/usr/local/java
export MYCAT_HOME=/usr/local/mycat
export PATH=$PATH:$JAVA_HOME/bin
# 创建软连接
ln -s /usr/local/mycat/bin/mycat /usr/bin/mycat
# 启动服务
mycat start
netstat -antp | grep -E "8066|9066"





2. 配置 mycat 虚拟数据库
# 备份原配置文件,以防修改出错,事实上我是出错了,查了好久
cd /usr/local/mycat
cp conf/server.xml{,.bak}
cp conf/schema.xml{,.bak}
vim conf/server.xml
80 <user name="nimo">
81 <property name="password">123property>
82 <property name="schemas">discuzproperty>
...
93 user>
这里只保留一组<user>标签,这就是我出问题的地方,当时我保留了原配置文件里的,后来备注掉之后,就可以启动了。
vim conf/schema.xml
1
2
3 <mycat:schema xmlns:mycat="http://io.mycat/">
4
5 <schema name="discuz" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1">
6 schema>
7 <dataNode name="dn1" dataHost="localhost1" database="discuz" />
8 <dataHost name="localhost1" maxCon="1000" minCon="10" balance="1"
9 writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
10 <heartbeat>select user()heartbeat>
11
12 <writeHost host="hostM1" url="localhost:3306" user="discuz"
13 password="Www.1.com">
14
15 <readHost host="hostS2" url="192.168.40.138:3306" user="discuz" password="Www.1.com" />
16 writeHost>
17
18 dataHost>
19 mycat:schema>
原配置文件注释掉的内容全被我删掉了,每个标签里的值都是关键,但是我没时间详细备注了,后期如有时间再来补上。
# 重启服务
mycat restart
netstat -antp | grep -E "8066|9066"




3. 总结
整个学习、操作、测试流程做完,有点儿温故知新的感觉,对 mysql 工作原理和性能实现有了较深的理解,也学习了网友大神们的心得,姑且算是促进了技能的成长和发展吧。
做到这我想到了接下来该进行的内容,Python 与 mysql 的结合,在工作中的应用该是怎样的?
后记
本文断断续续写完,由于我还有自己的工作,部分内容未能全面表述,甚至可能存在严重的错误,以后有时间再来弥补。也欢迎各路大神来交流指正。