如何用 Python 和循环神经网络(RNN)做中文文本分类?

本文为你展示,如何使用 fasttext 词嵌入预训练模型和循环神经网络(RNN), 在 Keras 深度学习框架上对中文评论信息进行情感分类。
疑问
回顾一下,之前咱们讲了很多关于中文文本分类的内容。
你现在应该已经知道如何对中文文本进行分词了。
你也已经学习过,如何利用经典的机器学习方法,对分词后的中文文本,做分类。
你还学习过,如何用如何用Python和机器学习训练中文文本情感分类模型?》一文中采用过的某商户的点评数据。
我把它放在了一个 github repo 中,供你使用。
请点击这个链接,访问咱们的代码和数据。
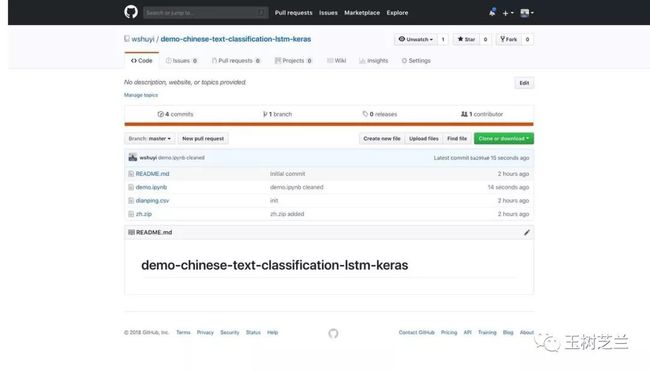
我们的数据就是其中的 dianping.csv 。你可以点击它,看看内容。
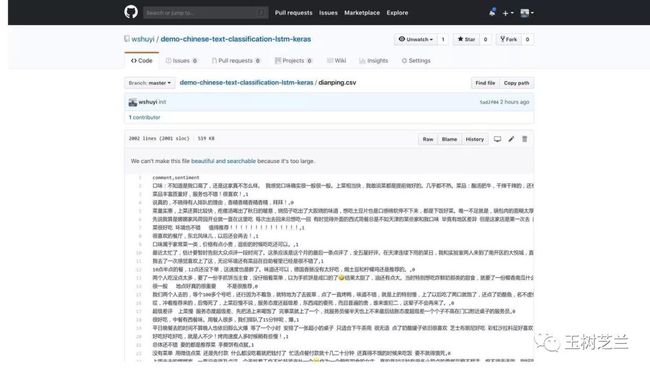
每一行是一条评论。评论内容和情感间,用逗号分隔。
1 代表正向情感,0 代表负面情感。
环境
要运行深度学习,你需要有 GPU 或者 TPU 的支持。
我知道,它们不便宜。
好在,Google 为咱们提供了免费的云端运行环境,叫做 Google Colab 。我曾经在《如何免费云端运行Python深度学习框架?》一文中,为你介绍过它。现在,它不止支持 GPU 了,还包含了 TPU 的选项。
注意,请使用 Google Chrome 浏览器来完成以下操作。
因为你需要安装一个浏览器插件插件,叫做 Colaboratory ,它是 Google 自家的插件,只能在 Chrome 浏览器中,才能运行。
点击这个链接,安装插件。
把它添加到 Google Chrome 之后,你会在浏览器的扩展工具栏里面,看见下图中间的图标:
安装它做什么用?
它的好处,是让你可以直接把看到的 Github 源代码,一键挪到 Google Colab 深度学习环境中来使用。
回到本范例的github repo 主页面,打开其中的 demo.ipynb 文件。
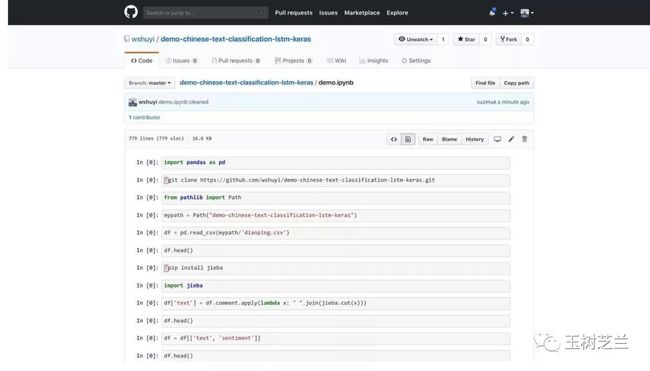
然后,点击刚刚安装的 Colaboratory 扩展图标。Google Chrome 会自动帮你开启 Google Colab,并且装载这个 ipynb 文件。
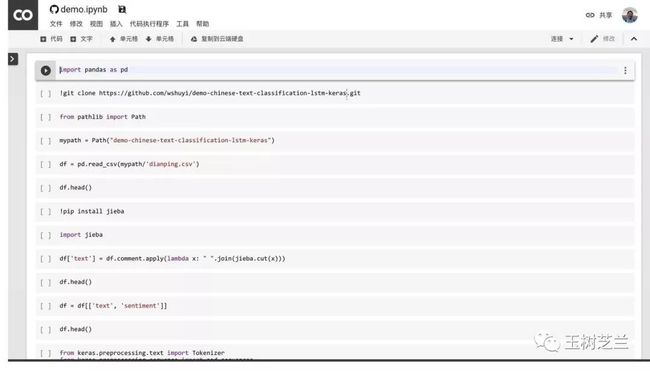
点击菜单栏里面的“代码执行程序”,选择“更改运行时类型”。

在出现的对话框中,确认选项如下图所示。
点击“保存”即可。
下面,你就可以依次执行每一个代码段落了。
注意第一次执行的时候,可能会有警告提示。

出现上面这个警告的时候,点击“仍然运行”就可以继续了。
如果再次出现警告提示,反勾选“在运行前充值所有代码执行程序”选项,再次点击“仍然运行”即可。
环境准备好了,下面我们来一步步运行代码。
预处理
首先,我们准备好 Pandas ,用来读取数据。
import pandas as pd
我们从前文介绍的github repo里面,下载代码和数据。
!git clone https://github.com/wshuyi/demo-chinese-text-classification-lstm-keras.git
下面,我们调用 pathlib 模块,以便使用路径信息。
from pathlib import Path
我们定义自己要使用的代码和数据文件夹。
mypath = Path("demo-chinese-text-classification-lstm-keras")
下面,从这个文件夹里,把数据文件打开。
df = pd.read_csv(mypath/'dianping.csv')
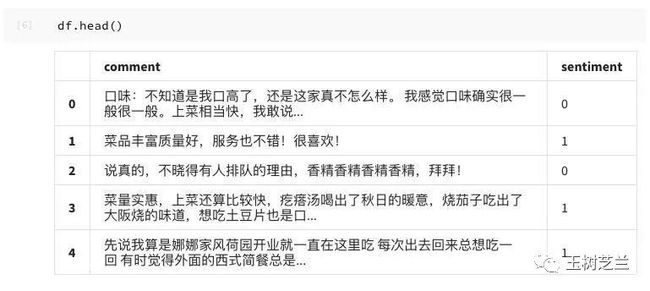
看看头几行数据:
df.head()
读取正确,下面我们来进行分词。
我们先把结巴分词安装上。
!pip install jieba
安装好之后,导入分词模块。
import jieba
对每一条评论,都进行切分:
df['text'] = df.comment.apply(lambda x: " ".join(jieba.cut(x)))
因为一共只有2000条数据,所以应该很快完成。
Building prefix dict from the default dictionary ...
Dumping model to file cache /tmp/jieba.cache
Loading model cost 1.089 seconds.
Prefix dict has been built succesfully.
再看看此时的前几行数据。
df.head()
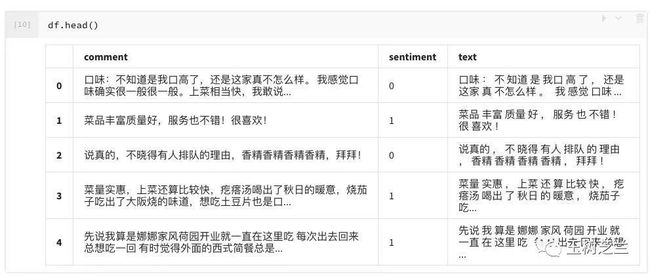
如图所示,text 一栏下面,就是对应的分词之后的评论。
我们舍弃掉原始评论文本,只保留目前的分词结果,以及对应的情感标记。
df = df[['text', 'sentiment']]
看看前几行:
df.head()

好了,下面我们读入一些 Keras 和 Numpy 模块,为后面的预处理做准备:
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
import numpy as np
系统提示我们,使用的后端框架,是 Tensorflow 。
Using TensorFlow backend.
下面我们要设置一下,每一条评论,保留多少个单词。当然,这里实际上是指包括标点符号在内的“记号”(token)数量。我们决定保留 100 个。
然后我们指定,全局字典里面,一共保留多少个单词。我们设置为 10000 个。
maxlen = 100
max_words = 10000
下面的几条语句,会自动帮助我们,把分词之后的评论信息,转换成为一系列的数字组成的序列。
tokenizer = Tokenizer(num_words=max_words)
tokenizer.fit_on_texts(df.text)
sequences = tokenizer.texts_to_sequences(df.text)
看看转换后的数据类型。
type(sequences)
显示为:
list
可见, sequences 是列表类型。
我们看看第一条数据是什么。
sequences[:1]
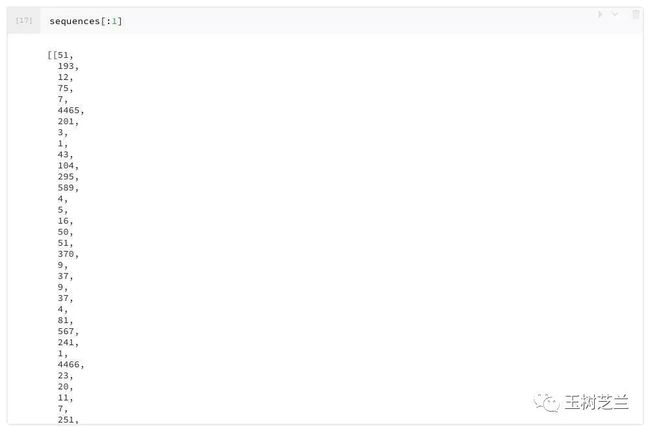
评论语句中的每一个记号,都被转换成为了一个大字典中对应的序号。字典的长度我们前面已经规定了,最多10000条。
但是这里有个问题——评论句子有长有短,其中包含的记号个数不同啊。
我们探索一下,只看最前面5句话,包含多少个记号(token)。
for sequence in sequences[:5]:
print(len(sequence))
150
12
16
57
253
果然,不仅长短不一,而且有的还超出我们想要的句子长度。
没关系,用 pad_sequences 方法裁长补短,我们让它统一化:
data = pad_sequences(sequences, maxlen=maxlen)
再看看这次的数据:
data
array([[ 2, 1, 74, ..., 4471, 864, 4],
[ 0, 0, 0, ..., 9, 52, 6],
[ 0, 0, 0, ..., 1, 3154, 6],
...,
[ 0, 0, 0, ..., 2840, 1, 2240],
[ 0, 0, 0, ..., 19, 44, 196],
[ 0, 0, 0, ..., 533, 42, 6]], dtype=int32)
那些长句子,被剪裁了;短句子,被从头补充了若干个 0 。整齐规范。
我们还希望知道,这些序号分别代表什么单词,所以我们把这个字典保存下来。
word_index = tokenizer.word_index
看看索引的类型。
type(word_index)
dict
类型验证通过。看看内容:
print(word_index)

没问题了。
中文评论数据,已经被我们处理成一系列长度为 100 ,其中都是序号的序列了。下面我们要把对应的情感标记,存储到标记序列 labels 中。
labels = np.array(df.sentiment)
看一下其内容:
labels
array([0, 1, 0, ..., 0, 1, 1])
全部数据都已经备妥了。下面我们来划分一下训练集和验证集。
我们采用的,是把序号随机化,但保持数据和标记之间的一致性。
indices = np.arange(data.shape[0])
np.random.shuffle(indices)
data = data[indices]
labels = labels[indices]
看看此时的标记:
labels
array([0, 1, 1, ..., 0, 1, 1])
注意顺序已经发生了改变。
我们希望,训练集占 80% ,验证集占 20%。根据总数,计算一下两者的实际个数:
training_samples = int(len(indices) * .8)
validation_samples = len(indices) - training_samples
其中训练集包含多少数据?
training_samples
1600
验证集呢?
validation_samples
400
下面,我们正式划分数据。
X_train = data[:training_samples]
y_train = labels[:training_samples]
X_valid = data[training_samples: training_samples + validation_samples]
y_valid = labels[training_samples: training_samples + validation_samples]
看看训练集的输入数据:
X_train
array([[ 0, 0, 0, ..., 963, 4, 322],
[ 0, 0, 0, ..., 1485, 79, 22],
[ 1, 26, 305, ..., 289, 3, 71],
...,
[ 0, 0, 0, ..., 365, 810, 3],
[ 0, 0, 0, ..., 1, 162, 1727],
[ 141, 5, 237, ..., 450, 254, 4]], dtype=int32)
至此,预处理部分就算完成了。
词嵌入
下面,我们安装 gensim 软件包,以便使用 Facebook 提供的 fasttext 词嵌入预训练模型。
!pip install gensim
安装后,我们读入加载工具:
from gensim.models import KeyedVectors
然后我们需要把 github repo 中下载来的词嵌入预训练模型压缩数据解压。
myzip = mypath / 'zh.zip'
以 ! 开头的语句,代表 bash 命令。其中如果需要使用 Python 变量,前面需要加 $ 。
!unzip $myzip
Archive: demo-chinese-text-classification-lstm-keras/zh.zip
inflating: zh.vec
解压完毕。
下面我们读入词嵌入预训练模型数据。
zh_model = KeyedVectors.load_word2vec_format('zh.vec')
看看其中的第一个向量是什么:
zh_model.vectors[0]

这么长的向量,对应的记号是什么呢?
看看前五个词汇:
list(iter(zh_model.vocab))[:5]
['的', '', '在', '是', '年']
原来,刚才这个向量,对应的是标记“的”。
向量的维度是多少?也就是,一个向量中,包含多少个数字?
len(zh_model[next(iter(zh_model.vocab))])
300
看来, fasttext 用 300 个数字组成一个向量,代表一个记号(token)。
我们把这个向量长度,进行保存。
embedding_dim = len(zh_model[next(iter(zh_model.vocab))])
然后,以我们规定的字典最大长度,以及每个标记对应向量长度,建立一个随机矩阵。
embedding_matrix = np.random.rand(max_words, embedding_dim)
看看它的内容:
embedding_matrix
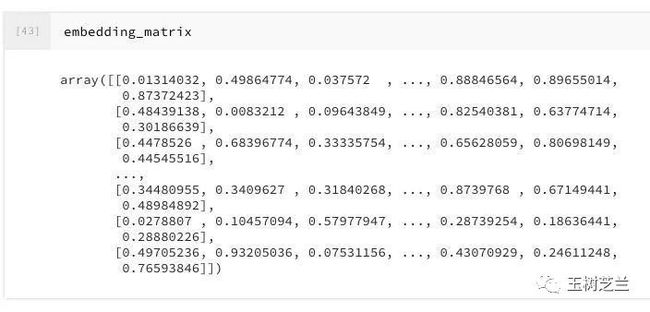
这个随机矩阵建立的时候,因为使用了 Numpy 的 random.rand 函数,默认都是从0到1的实数。
然而,我们刚才已经看过了“的”的向量表示,
请注意,其中的数字,在 -1 到 1 的范围中间。为了让我们随机产生的向量,跟它类似,我们把矩阵进行一下数学转换:
embedding_matrix = (embedding_matrix - 0.5) * 2
embedding_matrix
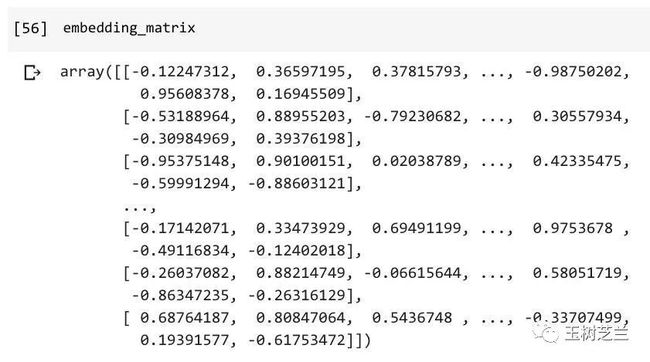
这样看起来,随机产生的数据,就和真正的预训练结果更相似了。
为什么做这一步呢?一会儿你就知道了。
我们尝试,对某个特定标记,读取预训练的向量结果:
zh_model.get_vector('的')

但是注意,如果你指定的标记,出现在自己任务文本里,却在预训练过程中没有出现,会如何呢?
试试输入我的名字:
zh_model.get_vector("王树义")
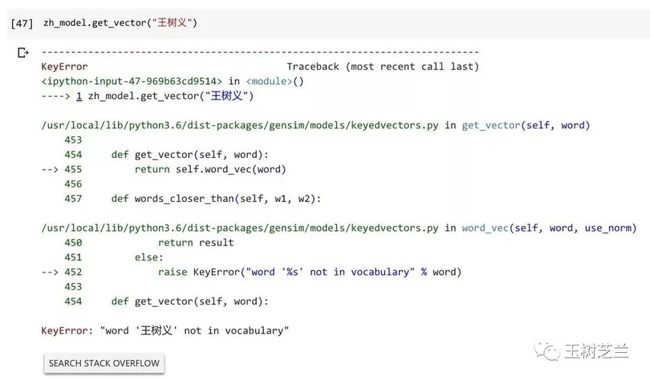
不好意思,因为我的名字,在 fasttext 做预训练的时候没有,所以获取词嵌入向量,会报错。
因此,在我们构建适合自己任务的词嵌入层的时候,也需要注意那些没有被训练过的词汇。
这里我们判断一下,如果无法获得对应的词向量,我们就干脆跳过,使用默认的随机向量。
for word, i in word_index.items():
if i < max_words:
try:
embedding_vector = zh_model.get_vector(word)
embedding_matrix[i] = embedding_vector
except:
pass
这也是为什么,我们前面尽量把二者的分布调整成一致。这样咱们对于没见过的词汇,也可以做成个以假乱真的分布,一起参加后面的模型训练过程。
看看我们产生的“混合”词嵌入矩阵:
embedding_matrix

模型
词嵌入矩阵准备好了,下面我们就要搭建模型了。
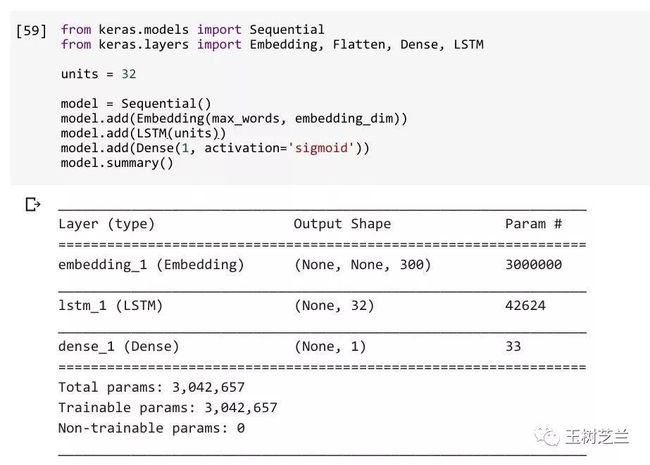
from keras.models import Sequential
from keras.layers import Embedding, Flatten, Dense, LSTM
units = 32
model = Sequential()
model.add(Embedding(max_words, embedding_dim))
model.add(LSTM(units))
model.add(Dense(1, activation='sigmoid'))
model.summary()
注意这里的模型,是最简单的顺序模型,对应的模型图如下:
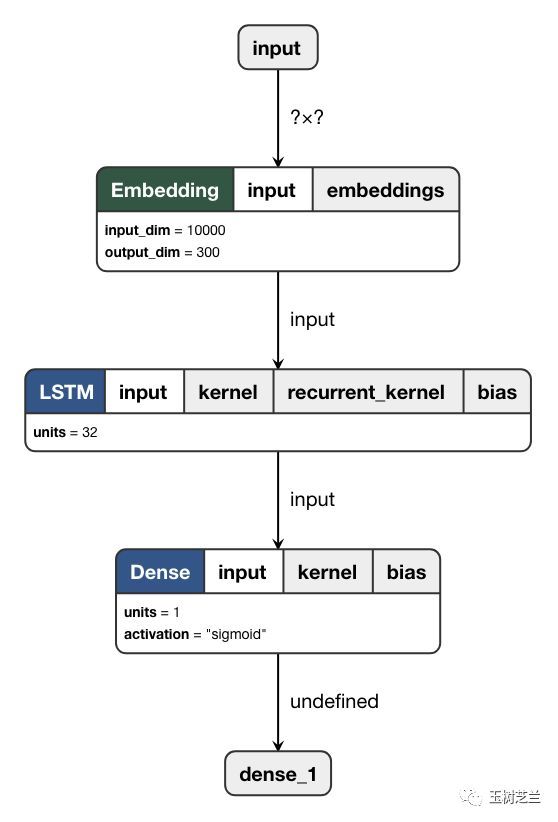
如图所示,我们输入数据通过词嵌入层,从序号转化成为向量,然后经过 LSTM (RNN 的一个变种)层,依次处理,最后产生一个32位的输出,代表这句评论的特征。
这个特征,通过一个普通神经网络层,然后采用 Sigmoid 函数,输出为一个0到1中间的数值。
Sigmoid 函数,大概长成这个样子:
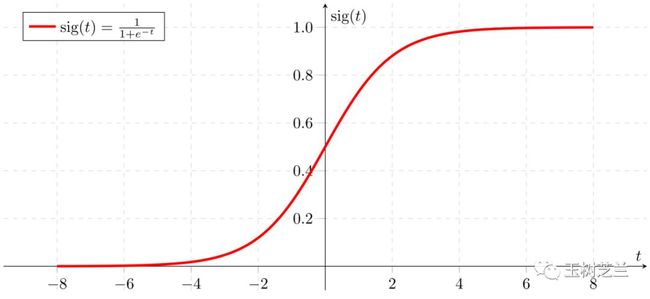
这样,我们就可以通过数值与 0 和 1 中哪个更加接近,进行分类判断。
但是这里注意,此处搭建的神经网络里,Embedding 只是一个随机初始化的层次。我们需要把刚刚构建的词嵌入矩阵导入。
model.layers[0].set_weights([embedding_matrix])
model.layers[0].trainable = False
我们希望保留好不容易获得的单词预训练结果,所以在后面的训练中,我们不希望对这一层进行训练,因而,trainable 参数设定为 False 。
因为是二元分类,因此我们设定了损失函数为 binary_crossentropy 。
我们训练模型,保存输出为 history ,并且把最终的模型结构和参数存储为 mymodel.h5 。
好了,开始训练吧:
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['acc'])
history = model.fit(X_train, y_train,
epochs=10,
batch_size=32,
validation_data=(X_valid, y_valid))
model.save("mymodel.h5")
机器认认真真,替我们跑了10个来回。
因为有 TPU 的帮助,所以这个过程,应该很快就能完成。

讨论
对于这个模型的分类效果,你满意吗?
如果单看最终的结果,训练集准确率超过 90%, 验证集准确率也超过 80%,好像还不错嘛。
但是,我看到这样的数据时,会有些担心。
我们把这些训练中获得的结果数值,用可视化的方法,显示一下:
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
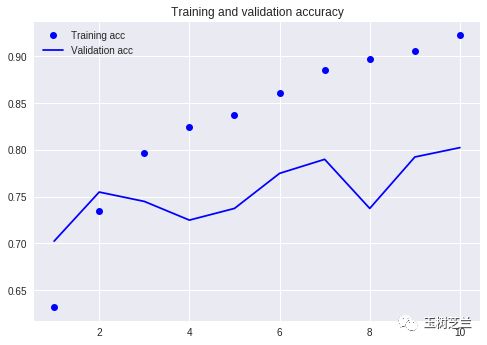
上图是准确率曲线。虚线是训练集,实线是验证集。我们看到,训练集准确率一路走高,但是验证集准确率在波动——即便最后一步刚好是最高点。
看下面的图,会更加清晰。
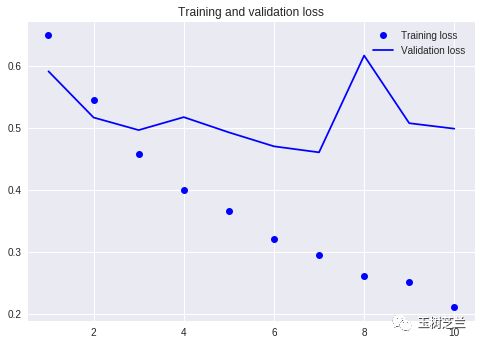
上图是损失数值对比。我们可以看到,训练集上,损失数值一路向下,但是,从第2个 epoch 开始,验证集的损失数值,就没有保持连贯的显著下降趋势。二者发生背离。
这意味着什么?
这就是深度学习中,最常见,也是最恼人的问题——过拟合(overfitting)。
《如何高效入门数据科学?》,里面还有更多的有趣问题及解法。
由于微信公众号外部链接的限制,文中的部分链接可能无法正确打开。如有需要,请点击文末的“阅读原文”按钮,访问可以正常显示外链的版本。
知识星球入口在这里:
