一. celery 简介
Celery 是一个专注于实时处理和任务调度的分布式任务队列, 同时提供操作和维护分布式系统所需的工具.. 所谓任务就是消息, 消息中的有效载荷中包含要执行任务需要的全部数据.
Celery 是一个分布式队列的管理工具, 可以用 Celery 提供的接口快速实现并管理一个分布式的任务队列.
Celery 本身不是任务队列, 是管理分布式任务队列的工具. 它封装了操作常见任务队列的各种操作, 我们使用它可以快速进行任务队列的使用与管理.
Celery 特性 :
- 方便查看定时任务的执行情况, 如 是否成功, 当前状态, 执行任务花费的时间等.
- 使用功能齐备的管理后台或命令行添加,更新,删除任务.
- 方便把任务和配置管理相关联.
- 可选 多进程, Eventlet 和 Gevent 三种模型并发执行.
- 提供错误处理机制.
- 提供多种任务原语, 方便实现任务分组,拆分,和调用链.
- 支持多种消息代理和存储后端.
- Celery 是语言无关的.它提供了python 等常见语言的接口支持.
二. celery 组件
1. Celery 扮演生产者和消费者的角色,
- Celery Beat : 任务调度器. Beat 进程会读取配置文件的内容, 周期性的将配置中到期需要执行的任务发送给任务队列.
- Celery Worker : 执行任务的消费者, 通常会在多台服务器运行多个消费者, 提高运行效率.
- Broker : 消息代理, 队列本身. 也称为消息中间件. 接受任务生产者发送过来的任务消息, 存进队列再按序分发给任务消费方(通常是消息队列或者数据库).
- Producer : 任务生产者. 调用 Celery API , 函数或者装饰器, 而产生任务并交给任务队列处理的都是任务生产者.
- Result Backend : 任务处理完成之后保存状态信息和结果, 以供查询.
Celery架构图
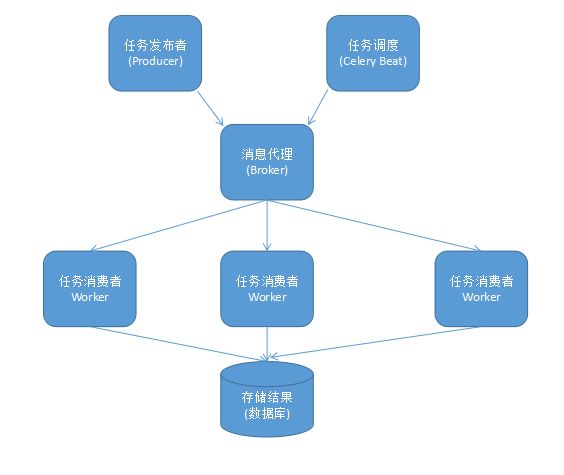
2. 产生任务的方式 :
- 发布者发布任务(WEB 应用)
- 任务调度按期发布任务(定时任务)
3. celery 依赖三个库: 这三个库, 都由 Celery 的开发者开发和维护.
- billiard : 基于 Python2.7 的 multisuprocessing 而改进的库, 主要用来提高性能和稳定性.
- librabbitmp : C 语言实现的 Python 客户端,
- kombu : Celery 自带的用来收发消息的库, 提供了符合 Python 语言习惯的, 使用 AMQP 协议的高级借口.
三. 选择消息代理
使用于生产环境的消息代理有 RabbitMQ 和 Redis, 官方推荐 RabbitMQ.
四. Celery 序列化
在客户端和消费者之间传输数据需要 序列化和反序列化. Celery 支出的序列化方案如下所示:
| 方案 | 说明 |
|---|---|
| pickle | pickle 是Python 标准库中的一个模块, 支持 Pyuthon 内置的数据结构, 但他是 Python 的专有协议. Celery 官方不推荐. |
| json | json 支持多种语言, 可用于跨语言方案. |
| yaml | yaml 表达能力更强, 支持的数据类型较 json 多, 但是 python 客户端的性能不如 json |
| msgpack | 二进制的类 json 序列化方案, 但比 json 的数据结构更小, 更快. |
五. 安装,配置与简单示例
Celery 配置参数汇总
| 配置项 | 说明 |
|---|---|
| CELERY_DEFAULT_QUEUE | 默认队列 |
| CELERY_BROKER_URL | Broker 地址 |
| CELERY_RESULT_BACKEND | 结果存储地址 |
| CELERY_TASK_SERIALIZER | 任务序列化方式 |
| CELERY_RESULT_SERIALIZER | 任务执行结果序列化方式 |
| CELERY_TASK_RESULT_EXPIRES | 任务过期时间 |
| CELERY_ACCEPT_CONTENT | 指定任务接受的内容类型(序列化) |
代码示例 :
# 安装
$ pip install celery, redis, msgpack
# 配置文件 celeryconfig.py
CELERY_BROKER_URL = 'redis://localhost:6379/1'
CELERY_RESULT_BACKEND = 'redis://localhost:6379/0'
CELERY_TASK_SERIALIZER = 'json'
CELERY_RESULT_SERIALIZER = 'json'
CELERY_TASK_RESULT_EXPIRES = 60 * 60 * 24 # 任务过期时间
CELERY_ACCEPT_CONTENT = ["json"] # 指定任务接受的内容类型.
# 初始化文件 celery.py
from __future__ import absolute_import
from celery import Celery
app = Celery('proj', include=["proj.tasks"])
app.config_from_object("proj.celeryconfig")
if __name__ == "__main__":
app.start()
# 任务文件 tasks.py
from __future__ import absolute_import
from proj.celery import app
@app.task
def add(x, y):
return x + y
# 启动消费者
$ celery -A proj worker -l info
# 在终端中测试
> from proj.tasks import add
> r = add.delay(2,4)
> r.result
6
> r.status
u"SUCCESS"
> r.successful()
True
> r.ready() # 返回布尔值, 任务执行完成, 返回 True, 否则返回 False.
> r.wait() # 等待任务完成, 返回任务执行结果.
> r.get() # 获取任务执行结果
> r.result # 任务执行结果.
> r.state # PENDING, START, SUCCESS
> r.status # PENDING, START, SUCCESS
# 使用 AsyncResult 方式获取执行结果.
# AsyncResult 主要用来存储任务执行信息与执行结果(类似 js 中的 Promise 对象),
> from celery.result import AsyncResult
> AsyncResult(task_id).get()
4
六. 调用任务的方法 :
1. delay
task.delay(args1, args2, kwargs=value_1, kwargs2=value_2)
2. apply_async
delay 实际上是 apply_async 的别名, 还可以使用如下方法调用, 但是 apply_async 支持更多的参数:
task.apply_async(args=[arg1, arg2], kwargs={key:value, key:value})
支持的参数 :
-
countdown : 等待一段时间再执行.
add.apply_async((2,3), countdown=5) -
eta : 定义任务的开始时间.
add.apply_async((2,3), eta=now+tiedelta(second=10)) -
expires : 设置超时时间.
add.apply_async((2,3), expires=60) -
retry : 定时如果任务失败后, 是否重试.
add.apply_async((2,3), retry=False) -
retry_policy : 重试策略.
- max_retries : 最大重试次数, 默认为 3 次.
- interval_start : 重试等待的时间间隔秒数, 默认为 0 , 表示直接重试不等待.
- interval_step : 每次重试让重试间隔增加的秒数, 可以是数字或浮点数, 默认为 0.2
- interval_max : 重试间隔最大的秒数, 即 通过 interval_step 增大到多少秒之后, 就不在增加了, 可以是数字或者浮点数, 默认为 0.2 .
自定义发布者,交换机,路由键, 队列, 优先级,序列方案和压缩方法:
task.apply_async((2,2), compression='zlib',
serialize='json',
queue='priority.high',
routing_key='web.add',
priority=0,
exchange='web_exchange')
七. 指定队列 :
Celery 默认使用名为 celery 的队列 (可以通过 CELERY_DEFAULT_QUEUE 修改) 来存放任务. 我们可以使用 优先级不同的队列 来确保高优先级的任务优先执行.
# 修改配置文件, 保证队列优先级
from kombu import Queue
CELERY_QUEUE = ( # 定义任务队列.
Queue('default', routing_key="task.#"), # 路由键 以 "task." 开头的消息都进入 default 队列.
Queue('web_tasks', routing_key="web.#") # 路由键 以 "web." 开头的消息都进入 web_tasks 队列.
)
CELERY_DEFAULT_EXCHANGE = 'tasks' # 默认的交换机名字为 tasks
CELERY_DEFAULT_EXCHANGE_KEY = 'topic' # 默认的交换机类型为 topic
CELERY_DEFAULT_ROUTING_KEY = 'task.default' # 默认的路由键是 task.default , 这个路由键符合上面的 default 队列.
CELERY_ROUTES = {
'proj.tasks.add': {
'queue': 'web_tasks',
'routing_key': 'web.add',
}
}
# 使用指定队列的方式启动消费者进程.
$ celery -A proj worker -Q web_tasks -l info # 该 worker 只会执行 web_tasks 中任务, 我们可以合理安排消费者数量, 让 web_tasks 中任务的优先级更高.
阅后即焚模式(transient):
from kombu import Queue
Queue('transient', routing_key='transient', delivery_mode=1)
八. 使用任务调度
使用 Beat 进程自动生成任务.
# 修改配置文件,
# 下面的任务指定 tasks.add 任务 每 10s 跑一次, 任务参数为 (16,16).
from datetime import timedelta
CELERYBEAT_SCHEDULE = {
'add': {
'task': 'proj.tasks.add',
'schedule': timedelta(seconds=10),
'args': (16, 16)
}
}
# crontab 风格
from celery.schedules import crontab
CELERYBEAT_SCHEDULE = {
"add": {
"task": "tasks.add",
"schedule": crontab(hour="*/3", minute=12),
"args": (16, 16),
}
}
# 启动 Beat 程序
$ celery beat -A proj
# 之后启动 worker 进程.
$ celery -A proj worker -l info
或者
$ celery -B -A proj worker -l info
使用自定义调度类还可以实现动态添加任务. 使用 Django 可以通过 Django-celery 实现在管理后台创建,删除,更新任务, 是因为他使用了自定义的 调度类 djcelery.schedulers.DatabaseScheduler .
九. 任务绑定, 记录日志, 重试
# 修改 tasks.py 文件.
from celery.utils.log import get_task_logger
logger = get_task_logger(__name__)
@app.task(bind=True)
def div(self, x, y):
logger.info(('Executing task id {0.id}, args: {0.args!r}'
'kwargs: {0.kwargs!r}').format(self.request))
try:
result = x/y
except ZeroDivisionError as e:
raise self.retry(exc=e, countdown=5, max_retries=3) # 发生 ZeroDivisionError 错误时, 每 5s 重试一次, 最多重试 3 次.
return result
当使用 bind=True 参数之后, 函数的参数发生变化, 多出了参数 self, 这这相当于把 div 编程了一个已绑定的方法, 通过 self 可以获得任务的上下文.
十. 信号系统 :
信号可以帮助我们了解任务执行情况, 分析任务运行的瓶颈. Celery 支持 7 种信号类型.
- 任务信号
- before_task_publish : 任务发布前
- after_task_publish : 任务发布后
- task_prerun : 任务执行前
- task_postrun : 任务执行后
- task_retry : 任务重试时
- task_success : 任务成功时
- task_failure : 任务失败时
- task_revoked : 任务被撤销或终止时
- 应用信号
- Worker 信号
- Beat 信号
- Eventlet 信号
- 日志信号
- 命令信号
不同的信号参数格式不同, 具体格式参见官方文档
代码示例 :
# 在执行任务 add 之后, 打印一些信息.
@after_task_publish
def task_send_handler(sender=None, body=None, **kwargs):
print 'after_task_publish: task_id: {body[id]}; sender: {sender}'.format(body=body, sender=sender)
十一. 子任务与工作流:
可以把任务 通过签名的方法传给其他任务, 成为一个子任务.
from celery import signature
task = signature('task.add', args=(2,2), countdown=10)
task
task.add(2,2) # 通过签名生成任务
task.apply_async()
还可以通过如下方式生成子任务 :
from proj.task import add
task = add.subtask((2,2), countdown=10) # 快捷方式 add.s((2,2), countdown-10)
task.apply_async()
自任务实现片函数的方式非常有用, 这种方式可以让任务在传递过程中财传入参数.
partial = add.s(2)
partial.apply_async((4,))
子任务支持如下 5 种原语,实现工作流. 原语表示由若干指令组成的, 用于完成一定功能的过程.
-
chain : 调用连, 前面的执行结果, 作为参数传给后面的任务, 直到全部完成, 类似管道.
from celery import chain res = chain(add.s(2,2), add.s(4), add.s(8))() res.get() 管道式: (add.s(2,2) | add.s(4) | add.s(8))().get() -
group : 一次创建多个(一组)任务.
from celery import group res = group(add.s(i,i) for i in range(10))() res.get() -
chord : 等待任务全部完成时添加一个回调任务.
res = chord((add.s(i,i) for i in range(10)), add.s(['a']))() res.get() # 执行完前面的循环, 把结果拼成一个列表之后, 再对这个列表 添加 'a'. [0,2,4,6,8,10,12,14,16,18,u'a'] -
map/starmap : 每个参数都作为任务的参数执行一遍, map 的参数只有一个, starmap 支持多个参数.
add.starmap(zip(range(10), range(10))) 相当于: @app.task def temp(): return [add(i,i) for i in range(10)] -
chunks : 将任务分块.
res = add.chunks(zip(range(50), range(50)),10)() res.get()
在生成任务的时候, 应该充分利用 group/chain/chunks 这些原语.
十二. 其他
关闭不想要的功能 :
@app.task(ignore_result=True) # 关闭任务执行结果.
def func():
pass
CELERY_DISABLE_RATE_LIMITS=True # 关闭限速.
根据任务状态执行不同操作 :
# tasks.py
class MyTask(Task):
def on_success(self, retval, task_id, args, kwargs):
print 'task done: {0}'.format(retval)
return super(MyTask, self).on_success(retval, task_id, args, kwargs)
def on_failure(self, exc, task_id, args, kwargs, einfo):
print 'task fail, reason: {0}'.format(exc)
return super(MyTask, self).on_failure(exc, task_id, args, kwargs, einfo)
# 正确函数, 执行 MyTask.on_success() :
@app.task(base=MyTask)
def add(x, y):
return x + y
# 错误函数, 执行 MyTask.on_failure() :
@app.task #普通函数装饰为 celery task
def add(x, y):
raise KeyError
return x + y
十三. Celery 管理命令
任务状态回调 :
| 参数 | 说明 |
|---|---|
| PENDING | 任务等待中 |
| STARTED | 任务已开始 |
| SUCCESS | 任务执行成功 |
| FAILURE | 任务执行失败 |
| RETRY | 任务将被 |
| REVOKED | 任务取消 |
| PROGRESS | 任务进行中 |
普通启动命令 :
$ celery -A proj worker -l info
使用 daemon 方式 multi :
$ celery multi start web -A proj -l info --pidfile=/path/to/celery_%n.pid --logfile=/path/to/celery_%n.log
# web 是对项目启动的标识,
# %n 是对节点的格式化用法.
%n : 只包含主机名
%h : 包含域名的主机
%d : 只包含域名
%i : Prefork 类型的进程索引,如果是主进程, 则为 0.
%I : 带分隔符的 Prefork 类型的进程索引. 假设主进程为 worker1, 那么进程池的第一个进程则为 worker1-1
常用 multi 相关命令:
$ celery multi show web # 查看 web 启动时的命令
$ celery multi names web # 获取 web 的节点名字
$ celery multi stop web # 停止 web 进程
$ celery multi restart web # 重启 web
$ celery multi kill web # 杀掉 web 进程
常用监控和管理命令 :
-
shell : 交互时环境, 内置了 Celery 应用实例和全部已注册的任务, 支持 默认解释器,IPython,BPython .
$ celery shell -A proj -
result : 通过 task_id 在命令行获得任务执行结果
$ celery -A proj result TASK_ID -
inspect active : 列出当前正在执行的任务
$ celery -A proj inspect active -
inspect stats : 列出 worker 的统计数据, 常用来查看配置是否正确以及系统的使用情况.
$ celery -A proj inspect stats
Flower web 监控工具
- 查看任务历史,任务具体参数,开始时间等信息;
- 提供图表和统计数据
- 实现全面的远程控制功能, 包括但不限于 撤销/终止任务, 关闭重启 worker, 查看正在运行任务
- 提供一个 HTTP API , 方便集成.
Flower 的 supervisor 管理配置文件:
[program:flower]
command=/opt/PyProjects/venv/bin/flower -A celery_worker:celery --broker="redis://localhost:6379/2" --address=0.0.0.0 --port=5555
directory=/opt/PyProjects/app
autostart=true
autorestart=true
startretries=3
user=derby
stdout_logfile=/var/logs/%(program_name)s.log
stdout_logfile_maxbytes=50MB
stdout_logfile_backups=30
stderr_logfile=/var/logs/%(program_name)s-error.log
stderr_logfile_maxbytes=50MB
stderr_logfile_backups=3
Celery 自带的事件监控工具显示任务历史等信息.
$ celery -A proj event
** 需要把 CELERY_SEND_TASK_SEND_EVENT = True 设置, 才可以获取时间.
使用自动扩展 :
$ celery -A proj worker -l info --autoscale=6,3 # 平时保持 3 个进程, 最大时可以达到 6 个.
Celery 命令汇总
$ celery --help
-A APP, --app APP
-b BROKER, --broker BROKER
--loader LOADER
--config CONFIG
--workdir WORKDIR
--no-color, -C
--quiet, -q
$ celery --help
+ Main:
| celery worker
| celery events
| celery beat
| celery shell
| celery multi
| celery amqp
+ Remote Control:
| celery status
| celery inspect --help
| celery inspect active
| celery inspect active_queues
| celery inspect clock
| celery inspect conf [include_defaults=False]
| celery inspect memdump [n_samples=10]
| celery inspect memsample
| celery inspect objgraph [object_type=Request] [num=200 [max_depth=10]]
| celery inspect ping
| celery inspect query_task [id1 [id2 [... [idN]]]]
| celery inspect registered [attr1 [attr2 [... [attrN]]]]
| celery inspect report
| celery inspect reserved
| celery inspect revoked
| celery inspect scheduled
| celery inspect stats
| celery control --help
| celery control add_consumer [exchange [type [routing_key]]]
| celery control autoscale [max [min]]
| celery control cancel_consumer
| celery control disable_events
| celery control election
| celery control enable_events
| celery control heartbeat
| celery control pool_grow [N=1]
| celery control pool_restart
| celery control pool_shrink [N=1]
| celery control rate_limit
| celery control revoke [id1 [id2 [... [idN]]]]
| celery control shutdown
| celery control terminate [id1 [id2 [... [idN]]]]
| celery control time_limit [hard_secs]
+ Utils:
| celery purge
| celery list
| celery call
| celery result
| celery migrate
| celery graph
| celery upgrade
+ Debugging:
| celery report
| celery logtool
+ Extensions:
| celery flower
十四. 在 Flask 中使用 Celery
Flask 文档: 基于 Celery 的后台任务
在 Flask 中使用 Celery
十五. 参考链接
Python Web开发实战