【论文翻译】-- Clipper: A Low-Latency Online Prediction Serving System
NSDI2017文章。
Clipper:一个低延迟在线预测服务系统。
翻译内容不见得是逐词或逐句翻译,很多是个人理解着翻译的,有不合适的地方欢迎评论指出。
本文内容涉及体系结构&机器学习。本人此前从事计算机视觉领域研究,读完这篇文章猜测作者应该是体系结构转行机器学习的,因为涉及到计算机视觉部分,文章出现的很多基础内容作者理解都有问题,而且内容写的不是十分严谨。因此,主要还是学习本文的结构思想,具体细节还是要辨证的看,不可盲目信任所谓的大牛啊,砖家啊之类的,毕竟这种交叉领域真想搞的那么明白恐怕要很多很多年的积累才行。
摘要
Machine learning is being deployed in a growing number of applications which demand real-time, accurate, and robust predictions under heavy query load. However, most machine learning frameworks and systems only address model training and not deployment.
机器学习正在越来越多的应用程序中进行部署,这些应用程序需要在繁重的查询负载下进行实时、准确、可靠的预测。 但是,大多数机器学习框架和系统仅针对模型训练而非部署。
In this paper, we introduce Clipper, a general-purpose low-latency prediction serving system.
在本文中,我们介绍了Clipper,一种通用的低延迟预测服务系统。
Interposing between end-user applications and a wide range of machine learning frameworks, Clipper introduces a modular architecture to simplify model deployment across frameworks and applications.
Clipper插入在终端用户应用和一系列深度学校框架中间,引入一个模块化的结构来简化框架和应用的模型部署。
Furthermore, by introducing caching, batching, and adaptive model selection techniques, Clipper reduces prediction latency and improves prediction throughput, accuracy, and robustness without modifying the underlying machine learning frameworks.
此外,通过引入 caching(缓存)、batching(批处理)、adaptive model selection techniques(模型适应选择技术),Clipper在不改变底层机器学习框架的前提下,降低了预测时延并且提高了预测通量、正确率、鲁棒性。
We evaluate Clipper on four common machine learning benchmark datasets and demonstrate its ability to meet the latency, accuracy, and throughput demands of online serving applications.
我们用4个通用机器学习数据集的benchmark进行评估,展示出了Clipper在时延、正确率、通量能力方面具有满足在线服务应用的能力。
Finally, we compare Clipper to the Tensorflow Serving system and demonstrate that we are able to achieve comparable throughput and latency while enabling model composition and online learning to improve accuracy and render more robust predictions.
最后,我们用Tensorflow 服务系统做比较,展示出Clipper在吞吐量和时延上有优势,同时模型组成和在线学习可以提高正确率并获得更好的鲁棒性。
1 Introduction
The past few years have seen an explosion of applications driven by machine learning, including recommendation systems [28, 60], voice assistants [18, 26, 55], and ad-targeting [3,27].
过去的几年里,大量机器学习应用涌向,包括推荐系统、语音助手、广告定向等。
These applications depend on two stages of machine learning: training and inference. Training is the process of building a model from data (e.g., movie ratings). Inference is the process of using the model to make a prediction given an input (e.g., predict a user’s rating for a movie).
这些应用依赖于两个阶段的机器学习:训练和推理。训练是利用数据建立模型的阶段;推理是使用训练好的模型对给定输入进行预测的阶段。
While training is often computationally expensive, requiring multiple passes over potentially large datasets, inference is often assumed to be inexpensive. Conversely, while it is acceptable for training to take hours to days to complete, inference must run in real-time, often on orders of magnitude more queries than during training, and is typically part of user-facing applications.
训练通常很耗费计算资源,可能需要多次传送大数据集;但推理过程通常不怎么耗费资源。训练过程需要几个小时甚至几天都是很正常的,相反地,推理过程通常是面向用户应用程序的一部分,必须要实时完成,且数据数量级比训练集要大。
For example, consider an online news organization that wants to deploy a content recommendation service to personalize the presentation of content. Ideally, the service should be able to recommend articles at interactive latencies (<100ms) [64], scale to large and growing user populations, sustain the throughput demands of flash crowds driven by breaking news, and provide accurate predictions as the news cycle and reader interests evolve.
举个栗子,假如有一个在线新闻组织想要部署一个内容推荐服务来个性化的展示内容。 理想情况下,服务应该在交互时延(<100ms)的时间内推荐文章,扩展到庞大且不断增长的用户数量时,仍然能维持因爆炸性新闻带来的瞬间拥堵通量需要,并提供准确预测如新闻周期和读者兴趣演变。
The challenges of developing these services differ between the training and inference stages.
部署这些服务的难度是不同于训练和预测阶段的。
On the training side, developers must choose from a bewildering array of machine learning frameworks with diverse APIs, models, algorithms, and hardware requirements.
训练时,开发人员必须从一系列令人眼花缭乱的机器学习框架中进行选择,框架含有不同的APIs、模型、算法和硬件需求。
Furthermore, they may often need to migrate between models and frameworks as new, more accurate techniques are developed. Once trained, models must be deployed to a prediction serving system to provide low-latency predictions at scale.
此外,开发人员可能经因新型更准确的技术被开发而常需要将模型在不同框架中迁移。一旦训练完成,模型必须被部署用于预测服务系统中提供低延时的大规模预测。
Unlike model development, which is supported by sophisticated infrastructure, theory, and systems, model deployment and prediction-serving have received relatively little attention.
不同于由复杂基础设施、理论和系统支持的模型开发阶段,模型部署阶段和预测服务记得很少收到关注。
Developers must cobble together the necessary pieces from various systems components, and must integrate and support inference across multiple, evolving frameworks, all while coping with ever-increasing demands for scalability and responsiveness.
开发人员必须从一堆系统单元中拼凑出必要的部件,并且必须集成和支持很多不断发展的框架,同时应对不断增长的可扩展性和响应规模。
As a result, the deployment, optimization, and maintenance of machine learning services is difficult and error-prone.
最终导致机器学习服务的部署、优化、维护都很困难且容易出错。
To address these challenges, we propose Clipper, a layered architecture system (Figure 1) that reduces the complexity of implementing a prediction serving stack and achieves three crucial properties of a prediction serving system: low latencies, high throughputs, and improved accuracy.
为了解决这些问题,我们提出Clipper,一层结构系统(如图1),以降低预测服务栈的实现难度并获得3个重要的属性:低延时、高通量、提升正确率。
Clipper is divided into two layers: (1) the model abstraction layer, and (2) the model selection layer.
Clipper可以细分为两个层:(1)模型抽象层;(2)模型选择层。
The first layer exposes a common API that abstracts away the heterogeneity of existing ML frameworks and models. Consequently, models can be modified or swapped transparently to the application.
第一层(模型抽象层)预留一个通用API,他抽象出现有机器学习框架和模型的异构型。因此,模型可以透明地修改或更换到应用程序。
The model selection layer sits above the model abstraction layer and dynamically selects and combines predictions across competing models to provide more accurate and robust predictions.
模型选择层在模型抽象层之上,可以动态选择或组合预测底层的竞争模型,以提供更准确更鲁棒的预测结构。
To achieve low latency, high throughput predictions, Clipper implements a range of optimizations. In the model abstraction layer, Clipper caches predictions on a permodel basis and implements adaptive batching to maximize throughput given a query latency target.
为了获得低延时、高通量的预测,Clipper 实现了一系列优化。 在模型抽象层中,Clipper 在预训练模型基础上获取预测结果并基于给定查询时延目标来实现自适应batch到最大通量。
In the model selection layer, Clipper implements techniques to improve prediction accuracy and latency.
在模型选择层,Clipper实现了一系列技术来增强预测准确率和降低时延。
To improve accuracy, Clipper exploits bandit and ensemble methods to robustly select and combine predictions from multiple models and estimate prediction uncertainty.
为了增加准确率,Clipper 利用bandit(老虎机)和ensemble(组合)方式来从多个模型和多不确定估计中鲁棒地选择和组合预测结果。
In addition, Clipper is able to adapt the model selection independently for each user or session.
此外,此外,Clipper能够为每个用户或会话自适应模型选择。
To improve latency, the model selection layer adopts a straggler mitigation technique to render predictions without waiting for slow models.
为了降低时延,模型选择层采用一种straggler mitigation的技术来给出预测结果,而不用等龟速的模型。
Because of this layered design, neither the end-user applications nor the underlying machine learning frameworks need to be modified to take advantage of these optimizations.
因为层级化设计,不论终端用户还是底层机器学习框架都不用修改就可以直接享有这些优化的优势。
We implemented Clipper in Rust and added support for several of the most widely used machine learning frameworks: Apache Spark MLLib [40], Scikit-Learn [51], Caffe [31], TensorFlow [1], and HTK [63].
我们用Rust(一种系统编程语言)实现了Clipper,同时还添加了集中应用很广泛的机器学习框架:Apache、Spark MLLib、Scikit-Learn、Caffe、Tensorflow、HTK。
While these frameworks span multiple application domains, programming languages, and system requirements, each was added using fewer than 25 lines of code.
尽管这些框架跨越多个应用领域、编程语言、系统需求,但添加过程都只需要不到25行代码。
We evaluate Clipper using four common machine learning benchmark datasets and demonstrate that Clipper is able to render low and bounded latency predictions (<20ms), scale to many deployed models even across machines, quickly select and adapt the best combination of models, and dynamically trade-off accuracy and latency under heavy query load. We compare Clipper to the Google TensorFlow Serving system [59], an industrial grade prediction serving system tightly integrated with the TensorFlow training framework.
我们用了4个常见机器学习数据集的benchmark来评估Clipper,结果显示Clipper可以在有限的低时延(<20ms)内完成预测;扩展到多机多模型部署时,Clipper能快速选择并且适应最好的模型组合,当查询两大时,还在正确率和低延时之间动态取舍。
We compare Clipper to the Google TensorFlow Serving system [59], an industrial grade prediction serving system tightly integrated with the TensorFlow training framework. We demonstrate that Clipper’s modular design and broad functionality impose minimal performance cost, achieving comparable prediction throughput and latency to TensorFlow Serving while supporting substantially more functionality.
我们将Clipper与Google TensorFlow服务系统进行了比较,Tensorflow服务系统是一个与TensorFlow培训框架紧密集成的工业级预测服务系统。 我们证明了Clipper的模块化设计和广泛的功能可以降低性能成本,实现与TensorFlow服务相当的预测吞吐量和延迟,同时支持更多功能。
In summary, our key contributions are:
总的来说,我们的主要贡献是:
A layered architecture that abstracts away the complexity associated with serving predictions in existing machine learning frameworks (§3).
一种分层体系结构,它抽离了现有机器学习框架中预测服务的复杂性(§3)。
A set of novel techniques to reduce and bound latency while maximizing throughput that generalize across machine learning frameworks (§4).
一组新技术用于减少和限制延迟同时最大化吞吐量,并涵盖很多机器学习框架(§4)。
A model selection layer that enables online model selection and composition to provide robust and accurate predictions for interactive applications (§5).
模型选择层,支持在线模型选择和组合,以便为交互式应用程序提供鲁棒且准确的预测(§5)。
2 Applications and Challenges
The machine learning life-cycle (Figure 2) can be divided into two distinct phases: training and inference.
机器学习的生命周期(图2)分为两个阶段:训练&推理。

Training is the process of estimating a model from data. Training is often computationally expensive requiring multiple passes over large datasets and can take hours or even days to complete.
训练是利用数据估计模型的过程。训练通常是耗费计算资源的,要看很多遍训练数据,可能需要几个小时甚至几天才能完成。
Much of the innovation in systems for machine learning has focused on model training with the development of systems like Apache Spark [65], the Parameter Server [38], PowerGraph [25], and Adam [14].
机器学习系统创新以开发模型训练系统为主,比如Apache Spark、Parameter Server、PowerGraph、Adam。
A wide range of machine learning frameworks have been developed to address the challenges of training.
为了解决训练问题,研究人员已经开发了一系列的机器学习框架。
Many specialize in particular models such as TensorFlow [1] for deep learning or Vowpal Wabbit [34] for large linear models. Others are specialized for specific application domains such as Caffe [31] for computer vision or HTK [63] for speech recognition.
一些是专用模型如深度学习专用的TensorFlow、大型线性模型专用的Vowpal Wabbit。另一些是特定应用领域如计算机视觉领域的Caffe、语音识别的HTK。
Typically, these frameworks leverage advances in parallel and distributed systems to scale the training process.
通常地,这些框架都是利用了并行分布式系统的优势来扩大训练过程的。
Inference is the process of evaluating a model to render predictions.
推理是利用预测结果评估模型的过程。
In contrast to training, inference does not involve complex iterative algorithms and is therefore generally assumed to be easy.
不同于训练,推理因不需要复杂周期性算法而看起来更简单一些。
As a consequence, there is little research studying the process of inference and most machine learning frameworks provide only basic support for offline batch inference – often with the singular goal of evaluating the model training algorithm.
结果导致大家都不研究推理过程。甚至大多数机器学习框架仅提供基础的离线批次推理——通常也只是用来评估训练模型的。
However, scalable, accurate, and reliable inference presents fundamental system challenges that will likely dominate the challenges of training as machine learning adoption increases.
但是,随着机器学习使用量的增加,可扩展的、精准的、可靠的推理系统很可能主导训练问题。(个人观点:我是没搞明白推理怎么就主导训练了,感觉作者这句话写的是乱七八糟。总之作者应该是想表达推理过程也非常重要。)
In this paper we focus on the less studied but increasingly important challenges of inference.
本文不咋关注训练,主要谈推理。
2.1 Application Workloads
To illustrate the challenges of inference and provide a benchmark on which to evaluate Clipper, we describe two canonical real-world applications of machine learning: object recognition and speech recognition.
为了说明推理的难点并提供用于评估Clipper的benchmark,我们描述了2个典型的机器学习应用:目标识别&语音识别。
Object Recognition 目标识别
Advances in deep learning have spurred rapid progress in computer vision, especially in object recognition problems – the task of identifying and labeling the objects in a picture. Object recognition models form an important building block in many computer vision applications ranging from image search to self-driving cars.
深度学习的发展也带动了计算机视觉的快速发展,尤其是目标识别问题——任务是识别并标记图像中的目标(个人理解:目标识别就是输入一张图片,输出图片主要内容也就是一个单词,即目标识别就干一件事。文中的identify&label说的让人感觉是目标检测一样,目标检测是干两件事,第一画框,第二写一个单词代表框里的东西是啥。)目标识别模型是其他很多计算机视觉应用从图像检索到无人驾驶汽车的基础。
As users interact with these applications, they provide feedback about the accuracy of the predictions, either by explicitly labeling images (e.g., tagging a user in an image) or implicitly by indicating whether the provided prediction was correct (e.g., clicking on a suggested image in a search). Incorporating this feedback quickly can be essential to eliminating failing models and providing a more personalized experience for users.
作为用户在和这些应用交互时,用户给预测结果提供反馈,反馈方式要么直接给出正确答案,要么只告诉应用它判断的结果对还是错。(个人理解:原文括号里的例子好像举跑偏了,不看括号内容挺好理解的,看了括号内容反倒不知道作者再说啥了,因此就忽略括号里面的内容吧)迅速整合这些用户反馈对消灭失败模型为用户提供个性化体验是十分重要的。
Benchmark Applications: We use the well studied MNIST [35], CIFAR-10 [32], and ImageNet [49] datasets to evaluate increasingly difficult object recognition tasks with correspondingly larger inputs. For each dataset, the prediction task requires identifying the correct label for an image based on its pixel values(这句是废话不翻译了). MNIST is a common baseline dataset used to demonstrate the potential of a new algorithm or technique, and both deep learning and more classical machine learning models perform well on MNIST. On the other hand, for CIFAR-10 and Imagenet, deep learning significantly outperforms other methods. By using three different datasets, we evaluate Clipper’s performance when serving models that have a wide variety of computational requirements and accuracies.
应用的Benchmark:用已经被玩烂了的MNIST、CIFAR10、ImageNet来评估Clipper在不同难度、不同数据量上的表现。一方面,MNIST是一个体现新算法和计算潜力常用的baseline(个人补充:MNIST早就没人玩了,3层网络正确率都能到98%+,早就没有人用MNIST证明自己的算法好了)并且,深度学习和经典机器学习模型都在MNIST上表现良好(个人补充:perform well有违事实,应该是perform very well 或者 extremely well)。另一方面,对于CIFAR10和Imagenet这两个数据集,基于深度学习的算法表现明显好于其他算法。通过这3个不同的数据集,我们可以在多种计算需求和正确率下评估Clipper服务模型的表现。
Automatic Speech Recognition 自动语音识别
语音识别这块先跳过吧,先主要看视觉这块。
2.2 Challenges 难点
Motivated by the above applications, we outline the key challenges of prediction serving and describe how Clipper addresses these challenges.
在上述应用的推动下,我们列出了预测服务的主要难点,并给出Clipper的解决方案。
Complexity of Deploying Machine Learning 机器学习部署的复杂性
There is a large and growing number of machine learning frameworks [1,7,13,16,31]. Each framework has strengths and weaknesses and many are optimized for specific models or application domains (e.g., computer vision).
机器学习框架太多了,并且越来越多。每种框架各有优劣,有的还有专门的应用领域(比如计算机视觉)。
Thus, there is no dominant framework and often multiple frameworks may be used for a single application (e.g., speech recognition and computer vision in automatic captioning).
因此,没有哪个框架能够独霸天下,一个应用中很有可能同时使用很多框架(如自动添加字幕任务中就同时应用了语音识别和计算机视觉框架)。
Furthermore, machine learning is an iterative process and the best framework may change as an application evolves over time (e.g., as a training dataset grows to require distributed model training).
此外,机器学习是一个循环过程,最合适的框架可能会随着时间而发生改变(例如,如果训练数据会随着时间增长,增长到一定程度就需要分布式训练)。
Although common model exchange formats have been proposed [47,48], they have never achieved widespread adoption because of the rapid and fundamental changes in state-of-the-art techniques and additional source of errors from parallel implementations for training and serving.
尽管已经有一些常见模型的格式转换方法(个人理解:原文的exchange format应该是指一个模型在不同框架之间的迁移,两个参考文献都是数据挖掘领域的,据我所知目前计算机视觉还没有特别好的模型在框架之间迁移的方法,多数都是重新写程序,重写训练模型),但是这些转换方法并没有得到广泛应用,原因是最先进的技术发展很快并且训练和推理服务并行实现由额外资源误差(这句话其实没太看懂,翻译的可能不对)。
Finally, machine learning frameworks are often developed by and for machine learning experts and are therefore heavily optimized towards model development rather than deployment. As a consequence of these design decisions, application developers are forced to accept reduced accuracy by forgoing the use of a model well-suited to the task or to incur the substantially increased complexity of integrating and supporting multiple machine learning frameworks.
最后,机器学习框架通常由机器学习专家开发,因此一直是注重开发优化而不是部署优化。这导致应用开发人员要么放弃使用合适的模型并接受正确率的下降,要么选择多框架组合同时大大提高了难度。
(个人疑问:作者好像任务框架的选择会影响最终的准确率,而作为一个曾经做算法的,我感觉一样的算法用不用的模型写出来应该是一样的啊,怎么会因为更换框架准确率就出现上升或下降那?一个模型最终的准确率不应该是模型结果和训练过结果决定吗,和框架有啥关系?)
Solution: Clipper introduces a model abstraction layer and common prediction interface that isolates applications from variability in machine learning frameworks (§4) and simplifies the process of deploying a new model or framework to a running application.
解决方法:Clipper搞了一个模型抽象层和一个通用预测接口用以隔离应用(§4),并简化新模型或框架的运行程序部署过程。
Prediction Latency and Throughput 预测的时延和通量
The prediction latency is the time it takes to render a prediction given a query. Because prediction serving is often on the critical path, predictions must both be fast and have bounded tail latencies to meet service level objectives [64].
预测时延是给定请求情况下预测所需时间。因为预测服务通常是个关键点,因此预测必须要快,要有尾延时限制以满足服务目标。
While simple linear models are fast, more sophisticated and often more accurate models such as support vector machines, random forests, and deep neural networks are much more computationally intensive and can have substantial latencies (50-100ms) [13] (see Figure 11 for details).
虽然简单的线性模型很快,但越复杂的模型往往有更高的精度,如支持向量机(SVM)、随机森林、深度神经网络都是计算密集型同时时延很大的算法(50-100ms)(具体见图11)。
In many cases accuracy can be improved by combining models but at the expense of stragglers and increased tail latencies.
许多情况下,精度可以通过组合模型来提高,但代价是尾延迟增大。
Finally, most machine learning frameworks are optimized for offline batch processing and not single-input prediction latency.
最后,大多数机器学习框架都仅优化了离线批处理预测而没有关注单输入预测时延。
Moreover, the low and bounded latency demands of interactive applications are often at odds with the design goals of machine learning frameworks.
此外,交互式应用的低且有界的时延需求经常和机器学习框架的设计目标有冲突。(个人不太理解冲突在哪)
The computational cost of sophisticated models can substantially impact prediction throughput.
复杂模型的计算代价很大程度上影响预测的通量。
For example, a relatively fast neural network which is able to render 100 predictions per second is still orders of magnitude slower than a modern web-server.
举个栗子,每秒可以预测100次神经网络已经是相对速度快的了,但是对于现代网络服务来讲这个速度还是慢了几个数量级。
While batching prediction requests can substantially improve throughput by exploiting optimized BLAS libraries, SIMD instructions, and GPU acceleration it can also adversely affect prediction latency.
尽管利用一些优化手段如BLAS库、SIMD、GPU加速等,批预测请求的通量已经得到提升,但是,这仍然对预测时延有不好的影响。
Finally, under heavy query load it is often preferable to marginally degrade accuracy rather than substantially increase latency or lose availability [3,23].
最后,在大量请求负载出现时,通常时选择略微降低正确率而不是选择大延迟或失去可用性。
(个人理解:目前如果遇见推理过程实时性高的情况下,通常采取略微降低精度以保证速度的方法。)
Solution: Clipper automatically and adaptively batches prediction requests to maximize the use of batch-oriented system optimizations in machine learning frameworks while ensuring that prediction latency objectives are still met (§4.3). In addition, Clipper employs straggler mitigation techniques to reduce and bound tail latency, enabling model developers to experiment with complex models without affecting serving latency (§5.2.2).
解决办法:Clipper 自适应预测请求以最大程度利用机器学习框架面向批处理的系统优化,同时保证在预测时延目标内完成预测。此外,Clipper 采用straggler mitigation(落后延缓)技术以减少和限制尾延迟,使模型开发人员能够试验复杂模型而不受服务延迟影响。
Model Selection
Model development is an iterative process producing many models reflecting different feature representations, modeling assumptions, and machine learning frameworks.
模型开发是一个迭代过程,这个过程衍生了许多模型以表达不同的特征、模型估计、机器学习框架等。
Typically developers must decide which of these models to deploy based on offline evaluation using stale datasets or engage in costly online A/B testing.
通常开发人员需要基于旧数据集的离线评估结果或使用代价很大的在线A/B测试决定部署哪些模型。
When predictions can influence future queries (e.g., content recommendation), offline evaluation techniques can be heavily biased by previous modeling results.
当预测结果会影响以后的请求时,离线评估技术中模型会受到之前的影响从而偏离正确预测结果。
Alternatively, A/B testing techniques [2] have been shown to be statistically inefficient — requiring data to grow exponentially in the number of candidate models.
又或者,A/B测试技术已经被证明是统计学无效的——要求数据在候选模型的数量上呈指数增长。
The resulting choice of model is typically static and therefore susceptible to changes in model performance due to factors such as feature corruption or concept drift [52]. In some cases the best model may differ depending on the context (e.g., user or region) in which the query originated.
由此产生的模型选择通常是静态的,因此可能会因feature corruption(不会翻译,也不知道啥意思)或概念漂移等因素而导致模型性能发生变化[52]。某些情况下,最有模型或许因请求源头的情况(如用户或区域)而有所不同。
Finally, predictions from more than one model can often be combined in ensembles to boost prediction accuracy and provide more robust predictions with confidence bounds.
最后,使用confidence bounds组合大于一个模型的预测结果以提高预测正确率来提高更鲁棒的预测是一个常用的手段。
Solution: Clipper leverages adaptive online model selection and ensembling techniques to incorporate feedback and automatically select and combine predictions from models that can span multiple machine learning frameworks.
解决方案:Clipper 使用自适应在线模型选择和组合技术来整合反馈,并自动从监控的多框架多模型中选择和组合预测结果。
2.3 Experimental Setup
Because we include microbenchmarks of many of Clipper’s features as we introduce them, we present the experimental setup now.
因为我们在之前的介绍里包含许多Clipper特征的微基准,所以我们现在提供实验设置。
For each of the three object recognition benchmarks, the prediction task is predicting the correct label given the raw pixels of an unlabeled image as input.
每个目标识别任务都是输入一张无标签的图像的原始像素,预测出对于图片正确的label。(输入图片,输出单词)
For the speech recognition benchmark, the prediction task is predicting the phonetic transcription of the raw audio signal. For this benchmark, we used the HTK Speech Recognition Toolkit [63] to learn Hidden Markov Models whose outputs are sequences of phonemes representing the transcription of the sound. Details about each dataset are presented in Table 1.
对于语音识别,预测任务是预测原始音频信号的语音转录(输入语音,输出文字)。 对于这个benchmark,我们使用HTK语音识别工具包[63]来学习隐马尔可夫模型,其输出是表示声音转录的音素序列。 表1列出了每个数据集的详细信息。

Unless otherwise noted, all experiments were conducted on a single server. All machines used in the experiments contain 2 Intel Haswell-EP CPUs and 256 GB of RAM running Ubuntu 14.04 on Linux 4.2.0. TensorFlow models were executed on a Nvidia Tesla K20c GPUs with 5 GB of GPU memory and 2496 cores. In the scaling experiment presented in Figure 6, the servers in the cluster were connected with both a 10Gbps and 1Gbps network. For each network, all the servers were located on the same switch. Both network configurations were investigated.
除非另有说明,所有实验均在单一服务器进行。所有实验涉及的机器包含2个Intel Haswell-EP CPUs和256 GB of RAM,使用基于 Linux 4.2.0的Ubuntu 14.04系统。TensorFlow模型在一个2496核5 GB显存的Nvidia Tesla K20c GPUs上完成。如图6在大规模实验中,集群中的服务器是用10Gbps和1Gbps两种网络连接的。对每种网络来说,所有服务器都连在同一个交换机上。两种网络配置都进行了实验。
3 System Architecture 系统结构
Clipper is divided into model selection and model abstraction layers (see Figure 1).
Clipper分成模型选择层(紫色)和模型抽象层(深绿色)两部分,如图1.

The model abstraction layer is responsible for providing a common prediction interface, ensuring resource isolation, and optimizing the query workload for batch oriented machine learning frameworks.
模型抽象层旨在提供通用模型接口,确保资源隔离、并且优化面向批处理的机器学习框架查询负载。
The model selection layer is responsible for dispatching queries to one or more models and combining their predictions based on feedback to improve accuracy, estimate uncertainty, and provide robust predictions.
模型选择层旨在基于反馈把查询调度到一个或多个组合组合预测以提高精度、估计不确定性并提供鲁棒性强的预测。
Before presenting the detailed Clipper system design we first describe the path of a prediction request through the system.
在介绍Clipper系统设计之前,我们先来说一下预测请求在系统中的路径。
Applications issue prediction requests to Clipper through application facing REST or RPC APIs.
应用程序通过面向应用的REST或RPC API向Clipper发出预测请求。
Prediction requests are first processed by the model selection layer.
预测请求首先被模型选择层处理。
Based on properties of the prediction request and recent feedback, the model selection layer dispatches the prediction request to one or more of the models through the model abstraction layer.
基于预测请求的属性和近期的反馈,模型选择层告诉模型抽象层要调度预测请求到一个还是多个模型。
The model abstraction layer first checks the prediction cache for the query before assigning the query to an adaptive batching queue associated with the desired model.
在将查询分配给相关联所需模型的自适应批处理队列之前,模型抽象层首先检查预测缓存。
The adaptive batching queue constructs batches of queries that are tuned for the machine learning framework and model.
自适应批处理队列构造针对机器学习框架和模型的查询批。
A cross language RPC is used to send the batch of queries to a model container hosting the model in its native machine learning framework.
跨语言RPC用于将查询批发送到对应这个查询批模型所属的机器学习框架的模型容器中。(其实就是每种框架都对应了一组查询批,看这个查询批里的模型是什么框架的,就送到能运行这个框架的机器上去)
To simplify deployment, we host each model container in a separate Docker container.
为了简化部署,我们将每种模型托管到一个Docker容器里。
After evaluating the model on the batch of queries, the predictions are sent back to the model abstraction layer which populates the prediction cache and returns the results to the model selection layer.
预测完查询批的模型后,预测结果被送回到模型抽象层,由模型抽象层加入预测缓存并返回结果给模型选择层。
The model selection layer then combines one or more of the predictions to render a final prediction and confidence estimate. The prediction and confidence estimate are then returned to the end-user application.
模型选择层再组合一个或多个预测结果以提供一个最终的预测和置信度估计。然后,最终预测结果和执行度被返回给终端应用。
Any feedback the application collects about the quality of the predictions is sent back to the model selection layer through the same application-facing REST/RPC interface.
应用收集关于预测结果质量的反馈被通过同样的面向应用的REST或RPC接口送回到模型选择层。
The model selection layer joins this feedback with the corresponding predictions to improve how it selects and combines future predictions.
模型选择层将此反馈与相应的预测结合在一起,以改进其选择和组合未来预测的方式。
We now present the model abstraction layer and the model selection layer in greater detail.
现在,我们详细地介绍模型抽象层和模型选择层。
4 Model Abstraction Layer 模型抽象层
The Model Abstraction Layer (Figure 1) provides a common interface across machine learning frameworks.
图1中的模型抽象层提供一个能对接机器学习框架的通用接口。
It is composed of a prediction cache, an adaptive querybatching component, and a set of model containers connected to Clipper via a lightweight RPC system.
模型抽象层由一个预测缓存、一个自适应批处理组件、一系列通过轻量级RPC系统连接在Clipper上的模型容器组成。
This modular architecture enables caching and batching mechanisms to be shared across frameworks while also scaling to many concurrent models and simplifying the addition of new frameworks.
这种模块化体系结构使缓存和批处理机制可以在各个框架之间共享,同时还可以扩展到许多并发模型并简化新框架的添加。
4.1 Overview 概况
At the top of the model abstraction layer is the prediction cache (§4.2). The prediction caches provides a partial pre-materialization mechanism for frequent queries and accelerates the adaptive model selection techniques described in §5 by enabling efficient joins between recent predictions and feedback.
在模型抽象层上面的是预测缓存(Sec.4.2)。预测缓存为频繁的查询提供一部分pre-materialization(预实现)机制,并通过使用有效的结合最近预测和反馈来加速自适应模型选择技术(Sec.5)。
The batching component (§4.3) sits below the prediction cache and aggregates point queries into mini-batches that are dynamically resized for each model container to maximize throughput. Once a mini-batch is constructed for a given model it is dispatched via the RPC system to the container for evaluation.
批处理组件(Sec.4.3)在预测缓存下面,并且将点查询合并到了mini-batch中,minibatch针对每个模型容器的最大吞吐量是动态大小的。一旦为一个给定模型组建了一个mini-batch,mini-batch会通过RPC系统分发给容器来做预测。
Models deployed in Clipper are each encapsulated within their own lightweight container (§4.4), communicating with Clipper through an RPC mechanism that provides a uniform interface to Clipper and simplifies the deployment of new models. The lightweight RPC system minimizes the overhead of the container-based architecture and simplifies cross-language integration.
Clipper中部署的模型每个都封装在他们自己的轻量容器中(Sec.4.4),容器通过RPC机制与Clipper通信,RPC机制提供一个标准接口来简化新模型的部署。轻量的RPC系统最大程度地减少了基于容器架构的开销,同时简化了跨语言 集成难度。
In the following sections we describe each of these components in greater detail and discuss some of the key algorithmic innovations associated with each.
在接下来的章节中,我们更细致地描述这些元组并讨论一些关键性的创新算法。
4.2 Caching (预测)缓存
(我理解的是:把之前使用过的模型就存储在预测缓存中,以后再有一样的模型预测则直接从预测缓存中读取内容。)
For many applications (e.g., content recommendation), predictions concerning popular items are requested frequently. By maintaining a prediction cache, Clipper can serve these frequent queries without evaluating the model. This substantially reduces latency and system load by eliminating the additional cost of model evaluation.
对于许多应用(例如,内容推荐),经常需要关于流行项目的预测。 通过维护预测缓存,Clipper可以为这些频繁的查询提供服务,而无需评估模型。 通过消除模型评估的额外成本,这大大减少了延迟和系统负载。
In addition, caching in Clipper serves an important role in model selection (§5). To select models intelligently Clipper needs to join the original predictions with any feedback it receives. Since feedback is likely to return soon after predictions are rendered [39], even infrequent or unique queries can benefit from caching.
此外,Clipper中的缓存在模型选择中起着重要作用(Sec.5)。 为了智能地选择模型,Clipper需要将原始预测与接收到的任何反馈结合起来。 由于反馈可能会在做出预测后很快返回[39],因此即使是不频繁或独一无二的查询也可以从缓存中受益。
For example, even with a small ensemble of four models (a random forest, logistic regression model, and linear SVM trained in Scikit-Learn and a linear SVM trained in Spark), prediction caching increased feedback processing throughput in Clipper by 1.6x from roughly 6K to 11K observations per second.
例如,一个由4种模型组成的小集合(随机森林、逻辑回归、基于Scikit-learn的线性支持向量机、基于Spark的线性支持向量机),预测缓存也将Clipper的反馈过程的吞吐量提高了1.6倍,大概从6k/s到11k/s。
The prediction cache acts as a function cache for the generic prediction function:
预测缓存是一个通用预测函数,类似一个函数(映射)缓存:
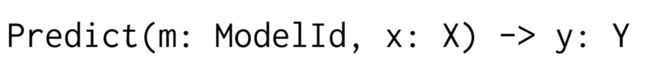
that takes a model id m along with the query x and computes the corresponding model prediction y.
预测缓存记录模型的id:m和查询x,计算出对应的预测y。
The cache exposes a simple non-blocking request and fetch API.
缓存暴露简单的非阻塞 请求 和 获取 两个接口(函数)。
When a prediction is needed, the request function is invoked which notifies the cache to compute the prediction if it is not already present and returns a boolean indicating whether the entry is in the cache.(此处怀疑文章里多写了一个not)
当有预测需求时,会调用请求函数,如果缓存里有相应的数据,则请求函数通知缓存计算预测结果,并返回一个布尔值来表示这个请求函数所请求的条目是否在缓存中存在。
The fetch function checks the cache and returns the query result if present.
获取函数检查缓存并返回查询结果如果缓存中存在请求条目。
Clipper employs an LRU eviction policy for the prediction cache, using the standard CLOCK [17] cache eviction algorithm. With an adequately sized cache, frequent queries will not be evicted and the cache serves as a partial pre-materialization mechanism for hot items.
Clipper的预测缓存采用LRU回收策略(从缓存中移除条目的策略),使用标准CLOCK缓存回收算法。为了充分利用缓存,频繁查询将不会被回收,同时缓存作为一部分的预实现机制为频繁查询服务。
However, because adaptive model selection occurs above the cache in Clipper, changes in predictions due to model selection do not invalidate cache entries.
但是,由于Clipper中自适应模型选择发生在缓存的上面,由模型选择导致的预测中的变化不会使缓存条目失效。
4.3 Batching 批处理(组件)
The Clipper batching component transforms the concurrent stream of prediction queries received by Clipper into batches that more closely match the workload assumptions made by machine learning frameworks while simultaneusly amortizing RPC and system overheads.
Clipper批处理组件将Clipper接收到的并发预测查询流转换为与机器学习框架所做的工作负载假设更为匹配的批处理,同时分摊RPC和系统开销。
Batching improves throughput and utilization of often costly physical resources such as GPUs, but it does so at the expense of increased latency by requiring all queries in the batch to complete before returning a single prediction.
批处理可以提高吞吐量和比较贵的物理资源(如GPU)的利用率,但这是以增加延迟为代价的,因为要等批中的所有查询都完成才能返回单个预测。
We exploit an explicitly stated latency service level objective (SLO) to increase latency in exchange for substantially improved throughput.
我们利用明确规定的延迟服务等级目标(SLO)来增加延迟,以换取吞吐量的大幅提高。
By allowing users to specify a latency objective, Clipper is able to tune batched query evaluation to maximize throughput while still meeting the latency requirements of interactive applications.
通过允许用户指定时延目标,Clipper能够调整批处理查询评估以最大化吞吐量,同时仍然满足交互式应用程序的延迟要求。
For example, requesting predictions in sufficiently large batches can improve throughput by up to 26x (the Scikit-Learn SVM in Figure 4) while meeting a 20ms latency SLO.
比如,足够大的批量预测请求可以将吞吐量提高多达26倍(图4中的Scikit-Learn SVM,第4列),同时满足20ms的延迟SLO。

Batching increases throughput via two mechanisms.
批处理通过两种机制提高了吞吐量。
First, batching amortizes the cost of RPC calls and internal framework overheads such as copying inputs to GPU memory.
第一,批处理可缓冲RPC调用的成本和内部框架的开销,例如将输入复制到GPU内存。
Second, batching enables machine learning frameworks to exploit existing data-parallel optimizations by performing batch inference on many inputs simultaneously (e.g., by using the GPU or BLAS acceleration).
第二,批处理使机器学习框架可以通过利用现有的数据并行优化,同时对多个输入执行批推理(例如通过使用GPU或BLAS加速)。
As the model selection layer dispatches queries for model evaluation, they are placed on queues associated with model containers.
当模型选择层调度查询以进行模型评估时,查询批将被放置在与模型容器关联的队列上。
Each model container has its own adaptive batching queue tuned to the latency profile of that container and a corresponding thread to process predictions.
每个模型容器都有自己的已经调整好延时配置文件的自适应批处理队列,并具有相应的线程来处理预测。
Predictions are processed in batches by removing as many queries as possible from a queue up to the maximum batch size for tat model container and sending the queries as a single batch prediction RPC to the container for evaluation.
预测是通过从队列中移除尽可能多的查询,直到该模型容器的极限最大批处理大小,然后将查询作为单个批处理预测RPC发送到容器以进行评估。
Clipper imposes a maximum batch size to ensure that latency objectives are met and avoid excessively delaying the first queries in the batch.
Clipper设置了最大的批处理大小,以确保满足目标延迟,并避免过度推迟批处理中的第一个查询。
Frameworks that leverage GPU acceleration such as TensorFlow often enforce static batch sizes to maintain a consistent data layout across evaluations of the model.
利用GPU加速的框架如Tensorflow通常强制使用将他batch_size以保持模型评估时的数据格式一致性。
These frameworks typically encode the batch size directly into the model definition in order to fully exploit GPU parallelism.
这些框架通常直接将batch_size编写再模型定义的代码里以便充分利用GPU并行性。(俗称的batch_size写死在程序里)
When rendering fewer predictions than the batch size, the input must be padded to reach the defined size, reducing model throughput without any improvement in prediction latency.
当给定的预测数据量比一个batch_size还小的时候,输入必须被填充成batch_size大小,这减小了模型的吞吐量,完全没有改善预测延时。
Careful tuning of the batch size should be done to maximize inference performance, but this tuning must be done offline and is fixed by the time a model is deployed.
为了尽可能的提高推理性能,需要仔细的调整一个合适的batch_size,但这个调整必须线下完成并在模型部署时一并完成(模型部署后就不可以更改了)。
However, most machine learning frameworks can efficiently process variable-sized batches at serving time.
但是,大多数机器学习框架可以在线上服务时有效的处理变化的batch_size。
Yet differences between the framework implementation and choice of model and inference algorithm can lead to orders of magnitude variation in model throughput and latency.
然而,框架的实现、模型的选择、推理算法等都会导致模型吞吐量和时延上有数量级的(非常大的)差异。
As a result, the latency profile – the expected time to evaluate a batch of a given size – varies substantially between model containers.
导致延时情况(latency profile)——评估一个给定大小的batch所需要的时间,会因模型容器的不同而不同。
For example, in Figure 3 we see that the maximum batch size that can be executed within a 20ms latency SLO differs by 241x between the linear SVM which does a very simple vector-vector multiply to perform inference and the kernel SVM which must perform a sequence of expensive nearest-neighbor calculations to evaluate the kernel.
例如图3中,使用最大batch size在20ms时延SLO中,简单矩阵乘法的linear SVM和要完成一系列近邻域计算的kernel SVM相差了241倍。

As a consequence, the linear SVM can achieve throughput of nearly 30,000 qps while the kernel SVM is limited to 200 qps under this SLO.
结果导致,通用在20ms的SLO时,linear SVM吞吐量达到30,000qps,而kernel SVM才200qps。
4.3.1 Dynamic Batch Size
We define the optimal batch size as the batch size that maximizes throughput subject to the constraint that the batch evaluation latency is under the target SLO.
我们把最优的batch_size定义为能够让目标吞吐量达到最大的batch_size,同时满足评估延时低于目标SLO的约束。
To automatically find the optimal maximum batch size for each model container we employ an additive-increase-multiplicative-decrease (AIMD) scheme.
为了为每个模型容器自动寻找最优的最大batch_size,我们采用一种AIMD(additive-increase-multiplicative-decrease)方案。
Under this scheme, we additively increase the batch size by a fixed amount until the latency to process a batch exceeds the latency objective.
AIMD方案中,我们以一个固定值累加batch_size直到处理一个batch的延时超过延时目标为止。
At this point, we perform a small multiplicative backoff, reducing the batch size by 10%.
此时,我们再给刚才的batch减小10%,这10%称作backoff。
Because the optimal batch size does not fluctuate substantially, we use a much smaller backoff constant than other Additive-Increase, Multiplicative-Decrease schemes [15].
最优batch_size的波动范围不会非常大(通常),因此我们使用的backoff比[15]文献的要小的多。
Early performance measurements (Figure 3) suggested a stable linear relationship between batch size and latency across several of the modeling frameworks.
前面的性能测试(图3)表明在几种模型框架中,batch_size和latency之间都是一个稳定的线性关系。
As a result, we also explored the use of quantile regression to estimate the 99th-percentile (P99) latency as a function of batch size and set the maximum batch size accordingly.
另外,我们还探索了使用分位数回归来估计第99百分位数(P99)的latency和batch_size之间的关系,并设置相应的最大batch_size。
We compared the two approaches on a range of commonly used Spark and Scikit-Learn models in Figure 4.
我们在常用的Spark和Scikit-Learn模型上的比较了百分位数回归(quantile regression)和自适应(本文提出)两个算法,如图4。(图4明显看出来自适应Adaptive算法的吞吐率更好,延时差不多quentile regression略好一点。)
Both strategies provide significant performance improvements over the baseline strategy of no batching, achieving up to a 26x throughput increase in the case of the Scikit-Learn linear SVM, demonstrating the performance gains that batching provides.
相对于不进行批处理的基准策略,这两种策略均提供了显着的性能改进,在Scikit-Learn线性SVM的情况下,吞吐量提高了26倍,这表明了批处理可提供性能提升。
While the two batching strategies perform nearly identically, the AIMD scheme is significantly simpler and easier to tune.
尽管两种批处理策略的性能几乎相同,但AIMD方案明显更简单且更易于调整。
Furthermore, the ongoing adaptivity of the AIMD strategy makes it robust to changes in throughput capacity of a model (e.g., during a garbage collection pause in Spark).
此外,AIMD策略的持续(ongoing)适应性使其对模型吞吐量的变化具有鲁棒性(例如,在Spark中的垃圾回收暂停期间)。
As a result, Clipper employs the AIMD scheme as the default.
最终,Clipper 采用AIMD作为默认方案。
4.3.2 Delayed Batching
Under moderate or bursty loads, the batching queue may contain less queries than the maximum batch size when the next batch is ready to be dispatched.
在中等或突发负载下,当下一个batch准备被调度时,批处理队列包含的查询可能少于最大批处理大小。
For some models, briefly delaying the dispatch to allow more queries to arrive can significantly improve throughput under bursty loads.
对于某些模型,短暂的推迟调度可以让更多的查询到来,以在突发复杂情况下改善吞吐量。
Similar to the motivation for Nagle’s algorithm [44], the gain in efficiency is a result of the ratio of the fixed cost for sending a batch to the variable cost of increasing the size of a batch.
与Nagle的算法动机类似,效率的提升是因为发送一个batch的花费是固定的,但是增加batch有效内容的比例了。
In Figure 5, we compare the gain in efficiency (measured as increased throughput) from delayed batching for two models.
在图5中,我们比较了两个模型的推迟批处理带来的效率提高(以增加的吞吐量来衡量)。
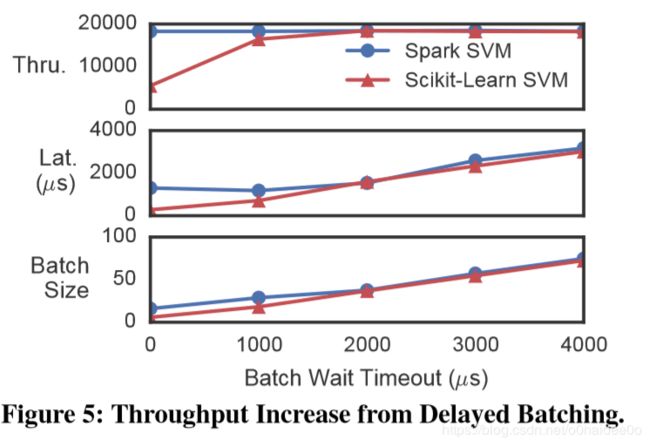
Delayed batching provides no increase in throughput for the Spark SVM because Spark is already relatively efficient at processing small batch sizes and can keep up with the moderate serving workload using batches much smaller than the optimal batch size.
推迟批处理不会为Spark SVM带来吞吐量的增加,因为Spark在处理小批量时已经比较高效,并且可以使用比最佳批量小得多的批处理来满足中等服务负载。
In contrast, the Scikit-Learn SVM has a high fixed cost for processing a batch but employs BLAS libraries to do efficient parallel inference on many inputs at once.
相比之下,Scikit-Learn SVM的批处理成本较高切固定,但同时使用BLAS库对多个输入进行并行推理也能有效(增大吞吐量)。
As a consequence, a 2ms batch delay provides a 3.3x improvement in throughput and allows the Scikit-Learn model container to keep up with the throughput demand while remaining well below the 10-20ms latency objectives needed for interactive applications.
因此,2毫秒的批处理推迟可将吞吐量提高3.3倍,并使Scikit-Learn模型容器能够满足吞吐量需求,同时仍远低于交互式应用程序所需的10到20毫秒延迟目标。
4.4 Model Containers 模型容器
Model containers encapsulate the diversity of machine learning frameworks and model implementations within a uniform “narrow waist” remote prediction API.
模型容器将多种机器学习框架和模型实现封装在了一个统一的“窄腰”远程预测API。
To add a new type of model to Clipper, model builders only need to implement the standard batch prediction interface in Listing 1. Clipper includes language specific container bindings for C++, Java, and Python.
要向Clipper添加一种新型的模型,模型构建者只需要实现Listing1中的标准批处理预测接口即可。Clipper包括针对C ++,Java和Python的语言特定的容器绑定。

Listing 1 :模型容器的通用批次预测接口。通过RPC接口调用批处理预测函数,以计算一批输入的预测。返回类型是嵌套列表,因为每个输入可能会产生多个输出。
The model container implementations for most of the models in this paper only required a few lines of code.
本文大多数模型的模型容器实现只需要几行代码。
To achieve process isolation, each model is managed in a separate Docker container.
为了实现处理时的隔离,每个模型都在单独的Docker容器中进行管理。
By placing models in separate containers, we ensure that variability in performance and stability of relatively immature state-of-the-art machine learning frameworks does not interfere with the overall availability of Clipper.
通过将模型放在单独的容器中,我们确保相对不成熟的最新机器学习框架的性能和稳定性方面的可变性不会干扰Clipper的整体可用性。
Any state associated with a model, such as the model parameters, is provided to the container during initialization and the container itself is stateless after initialization.
与模型相关的任何状态(例如模型参数)都在初始化期间提供给容器,并且初始化后容器本身是无状态的。
As a result, resource intensive machine learning frameworks can be replicated across multiple machines or given access to specialized hardware (e.g., GPUs) when needed to meet serving demand.
最后,资源密集型机器学习框架可以在多台机器之间复制,或者在需要时可以访问专用硬件(例如GPU)以满足服务需求。
4.4.1 Container Replica Scaling 容器副本规模
Clipper supports replicating model containers, both locally and across a cluster, to improve prediction throughput and leverage additional hardware accelerators.
Clipper支持在本地和跨集群复制模型容器,以提高预测吞吐量并利用其他硬件加速器。
Because different replicas can have different performance characteristics, particularly when spread across a cluster, Clipper performs adaptive batching independently for each replica.
因为不同的副本可能具有不同的性能特征,尤其是当分布在整个群集中时,Clipper会为每个副本独立执行自适应批处理。
In Figure 6 we demonstrate the linear throughput scaling that Clipper can achieve by replicating model containers across a cluster.
在图6中,我们展示了Clipper通过跨集群复制模型容器可以实现线性吞吐量提升。

With a four-node GPU cluster connected through a 10Gbps Ethernet switch, Clipper gets a 3.95x throughput increase from 19,500 qps when using a single model container running on a local GPU to 77,000 qps when using four replicas each running on a different machine.
一个4节点的GPU集群通过10Gbps以太网交换机相连,Clipper使吞吐量从用一个模型容器的19,500qps提高到使用4个副本的77,000qps,吞吐量提高了3.95倍。
Because the model containers in this experiment are computationally intensive and run on the GPU, GPU throughput is the bottleneck and Clipper’s RPC system can easily saturate the GPUs.
由于本实验中的模型容器是计算密集型的并且在GPU上运行,因此GPU吞吐量是瓶颈,Clipper的RPC系统可以轻松使GPU饱和。
However, when the cluster is connected through a 1Gbps switch, the aggregate throughput of the GPUs is higher than 1Gbps and so the network becomes saturated when replicating to a second remote machine.
但是,当群集通过1Gbps交换机连接时,GPU的总吞吐量高于1Gbps,因此当复制到第二台远程计算机时,网络将变得饱和。
As machine-learning applications begin to consume increasingly bigger inputs, scaling from handcrafted features to large images, audio signals, or even video, the network will continue to be a bottleneck to scaling out prediction serving applications.
随着机器学习应用程序开始消耗越来越大的输入,从手工提取特征到大图像,音频信号甚至视频,网络将继续成为扩展预测服务应用程序的瓶颈。
This suggests the need for research into efficient networking strategies for remote predictions on large inputs.
这表明需要研究有效的网络策略,以对大输入进行远程预测。
5 Model Selection Layer
The Model Selection Layer uses feedback to dynamically select one or more of the deployed models and combine their outputs to provide more accurate and robust predictions.
模型选择层使用反馈来动态选择一个或多个已部署模型,并组合其输出以提供更准确和可靠的预测。
By allowing many candidate models to be deployed simultaneously and relying on feedback to adaptively determine the best model or combination of models, the model selection layer simplifies the deployment process for new models.
通过允许同时部署许多候选模型并依靠反馈来自适应地确定最佳模型或模型组合,模型选择层简化了新模型的部署过程。
By continuously learning from feedback throughout the lifetime of an application, the model selection layer automatically compensates for failing models without human intervention.
通过在应用程序的整个生命周期中不断从反馈中学习,模型选择层可自动补偿失败的模型,而无需人工干预。
By combining predictions from multiple models, the model selection layer boosts application accuracy and estimates prediction confidence.
通过组合来自多个模型的预测,模型选择层可以提高应用程序的准确性并估计预测的可靠性。
There are a wide range of techniques for model selection and composition that span a tradeoff space of computational overhead and application accuracy.
有许多用于模型选择和组合的技术,它们跨越了计算开销和应用程序精度的折衷空间。(没太看懂这句话作者想说啥意思)
However, most of these techniques can be expressed with a simple select, combine, and observe API.
但是,大多数这些技术都可以通过简单的选择,组合和观察API来表达。
We capture this API in the model selection policy interface (Listing 2) which governs the behavior of the model selection layer and allows users to introduce new model selection techniques themselves.
我们在模型选择策略接口中捕获了该API(Listing 2),该接口控制模型选择层的行为,并允许用户自己引入新的模型选择技术。

The model selection policy (Listing 2) defines four essential functions as well as a few basic types. In addition to the query and prediction types X and Y, the state type S encodes the learned state of the selection algorithm.
模型选择策略(Listing 2)定义了四个基本功能以及一些基本类型。 除了查询和预测类型X和Y,状态类型S还对选择算法的学习状态进行编码。
The init function returns an initial instance of the selection policy state.
init函数返回选择策略状态的初始实例。
We isolate the selection policy state and require an initialization function to enable Clipper to efficiently instantiate many instances of the selection policy for finegrained contextualized model selection (§5.3).
我们隔离选择策略状态,并需要初始化函数来启动Clipper,以使Clipper能够有效地实例化选择策略的许多实例,以进行细粒度的上下文模型选择(Sec.5.3)。
The select and combine functions are responsible for choosing which models to query and how to combine the results.
选择(select)和合并(combine)函数负责选择要查询哪个模型以及如何合并结果。
In addition, the combine function can compute other information about the predictions. For example, in §5.2.1 we leverage the combine function to provide a prediction confidence score.
此外,合并(conbine)函数还可以计算有关预测的其他信息。例如,在Sec.5.2.1中,我们利用Combine函数来提供预测置信度得分。
Finally, the observe function is used to update the state S based on feedback from front-end applications.
最后,观察(observe)函数用于基于前端应用程序的反馈来更新状态S。
In the current implementation of Clipper we provide two generic model selection policies based on robust bandit algorithms developed by Auer et al. [6].
在Clipper的当前实现中,我们基于Auer等人开发的鲁棒的bendit算法提供了两种通用的模型选择策略。
These algorithms span a trade-off between computation overhead and accuracy.
这些算法需要在计算开销和准确性之间进行权衡。
The single model selection policy (§5.1) leverages the Exp3 algorithm to optimally select the best model based on noisy feedback with minimal computational overhead.
单一模型选择策略(Sec.5.1)利用Exp3算法,基于noisy feedback以最小的计算开销标准来最佳选择最佳模型。
The ensemble model selection policy (§5.2) is based on the Exp4 algorithm which adaptively combines the predictions to improve prediction accuracy and estimate confidence at the expense of increased computational cost from evaluating all models for each query.
集成模型选择策略(Sec.5.2)基于Exp4算法,该算法自适应地组合预测以提高预测精度和估计置信度,但以增加针对每个查询评估所有模型的计算成本为代价。
By implementing model selection policies that provide different cost-accuracy tradeoffs, as well as an API for users to implement their own policies, Clipper provides a mechanism to easily navigate the tradeoffs between accuracy and computational cost on a per-application basis.
通过实现提供不同成本准确性权衡的模型选择策略以及供用户实施自己的策略的API,Clipper提供了一种机制,可以轻松地在每个应用程序的基础上在准确性和计算成本之间进行权衡。
Furthermore, users can modify this choice over time as application workloads evolve and resources become more or less constrained.
此外,随着应用程序工作负载的发展以及资源或多或少地受到限制,用户可以随时间修改此选择。
5.1 Single Model Selection Policy单一模型选择策略
We can cast the model-selection process as a multi-armed bandit problem [43]. The multi-armed bandit1 problem refers the task of optimally choosing between k possible actions (e.g., models) each with a stochastic reward (e.g., feedback).
我们可以将模型选择过程看作一个multi-armed bandit(MAB,多臂赌博机)问题。MAB问题是指在k个可能的动作(例如模型)之间进行最佳选择的任务,每个动作都具有随机奖励(例如反馈)。
Because only the reward for the selected action can be observed, solutions to the multi-armed bandit problem must address the trade-off between exploring possible actions and exploiting the estimated best action.
由于只能观察到对选定行动(模型)的回报,因此多臂老虎机问题的解决方案必须解决在探索可能的行动(模型)与利用估计的最佳行动(模型)之间的权衡问题。
There are numerous algorithms for the multi-armed bandits problem with a wide range of trade-offs. In this work we first explore the use of the simple randomized Exp3 [6] algorithm which makes few assumptions about the problem setting and has strong optimality guarantees.
有很多算法可以解决多臂老虎机问题,并且进行广泛的权衡。 在这项工作中,我们首先探索简单随机Exp3 [6]算法的使用,该算法对问题的设置几乎没有假设,并且具有强大的最优性保证。
The Exp3 algorithm associates a weight si = 1 for each of the k deployed models and then randomly selects model i with probability pi = si/∑k j=1 sj. For each prediction ˆ y, Clipper observes a loss L(y, ˆ y) ∈ [0,1] with respect to the true value y (e.g., the fraction of words that were transcribed correctly during speech recognition). The Exp3 algorithm then updates the weight, si ← si exp(−ηL(y, ˆ y)/pi), corresponding to the selected model i. The constant η determines how quickly Clipper responds to recent feedback.
Exp3算法给k个部署的模型中的每一个模型关联一个权重Si=1,然后随机选择模型i,其概率是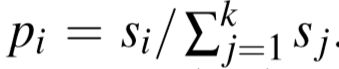 。对于每个预测结果
。对于每个预测结果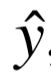 来说,Clipper观察对应于和真实值y(如,在语音识别过程中正确转录的单词比例)的损失即
来说,Clipper观察对应于和真实值y(如,在语音识别过程中正确转录的单词比例)的损失即 。然后Exp3算法给对应选择的第i模型更新权重
。然后Exp3算法给对应选择的第i模型更新权重 。常数η决定Clipper对反馈的响应速度。
。常数η决定Clipper对反馈的响应速度。
The Exp3 algorithm provides several benefits over manual experimentation and A/B testing, two common ways of performing model-selection in practice. Exp3 is both simple and robust, scaling well to model selection over a large number of models. It is a lightweight algorithm that requires only a single model evaluation for each prediction and thus performs well under heavy loads with negligible computational overhead. And Exp3 has strong theoretical guarantees that ensure it will quickly converge to an optimal solution.
Exp3算法比手动实验和A / B Testing(在实践中执行模型选择的两种常用方法)具有更多优势。 Exp3既简单又鲁棒,可以很好地扩展以选择大量模型。 它是一种轻量级算法,每个预测仅需进行一次模型评估,因此在繁重的负载下表现良好,而计算开销却可以忽略不计。 Exp3具有强大的理论保证,可确保快速收敛到最佳解决方案。
5.2 Ensemble Model Selection Policies 组合模型选择策略
It is a well-known result in machine learning [8,12,30,43] that prediction accuracy can be improved by combining predictions from multiple models. For example, bootstrap aggregation [9] (a.k.a., bagging) is used widely to reduce variance and thereby improve generalization performance.
众所周知,机器学习的预测正确率可以通过组合多个模型的预测结果来获得提升。例如,bootstrap aggregation算法(也称bagging算法)被广泛用于降低方差从而提高泛化能力。
More recently, ensembles were used to win the Netflix challenge [53], and a carefully crafted ensemble of deep neural networks was used to achieve state-of-the-art accuracy on the speech recognition corpus Google uses to power their acoustic models [30].
最近,Netflix比赛中获胜的就是使用了组合方法,并且精心组合了深度神经网络以用于语音识别语料库,谷歌使用组合增强了听觉模型,并获得顶级准确率。(说实话后半句没太看懂,感觉两句话合一块说了似的。)
The ensemble model selection policies adaptively combine the predictions from all available models to improve accuracy, rather than select individual models.
组合模型选择策略自适应地组合来自所有可用模型的预测以提高准确性,而不是选择单个模型。
In Clipper we use linear ensemble methods which compute a weighted average of the base model predictions.
在Clipper中,我们使用线性组合方法计算基础模型预测的加权平均值。
In Figure 7, we show the prediction error rate of linear ensembles on two bench,marks.
图7中,展示了两个benchmarks的线性组合的预测错误率。
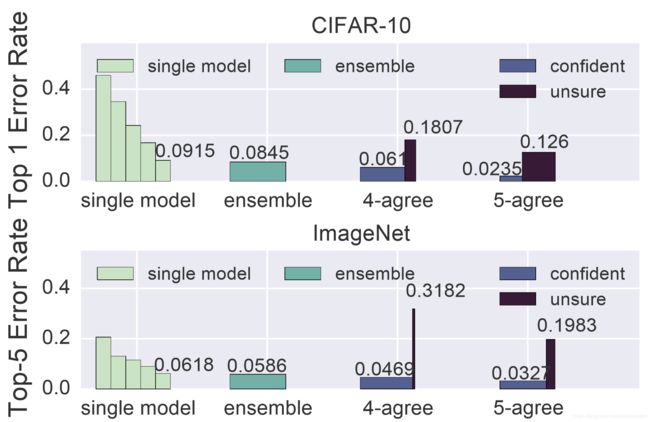
In both cases linear ensembles are able to marginally reduce the overall error rate.
在这两种情况下,线性组合都能略微降低总体错误率。
In the ImageNet benchmark, the ensemble formulation achieves a 5.2% relative reduction in the error rate simply by combining off-the-shelf models (Table 2).
在ImageNet基准测试中,仅通过组合现成的模型(表2),组合公式就可以将错误率相对降低5.2%。

While this may seem small, on the difficult computer vision tasks for which these models are used, a lot of time and energy is spent trying to achieve even small reductions in error, and marginal improvements are considered significant [49].
尽管这看起来很小,但在使用这些模型的困难的计算机视觉任务上,却花费了大量的时间和精力来尝试减少一点点的错误率,并且微小的改进也被认为是重要的[49]。
There are many methods for estimating the ensemble weights including linear regression, boosting [43], and bandit formulations.
有许多方法可以估计整体权重,包括线性回归,boosting、老虎机。
We adopt the bandits approach and use the Exp4 algorithm [6] to learn the weights.
我们采用老虎机方法并使用Exp4算法[6]来学习权重。
Unlike Exp3, Exp4 constructs a weighted combination of all base model predictions and updates weights based on the individual model prediction error. Exp4 confers many of the same theoretical guarantees as Exp3. But while the accuracy when using Exp3 is bounded by the accuracy of the single best model, Exp4 can further improve prediction accuracy as the number of models increases.
与Exp3不同,Exp4构建所有基本模型预测的加权组合,并根据单个模型预测误差更新权重。 Exp4提供与Exp3相同的许多理论保证。 但是,尽管使用Exp3时的准确性受到单个最佳模型的准确性的限制,但随着模型数量的增加,Exp4可以进一步提高预测准确性。
The extent to which accuracy increases depends on the relative accuracies of the set of base models, as well as the independence of their predictions. This increased accuracy comes at the cost of increased computational resources consumed by each prediction in order to evaluate all the base models.
准确性提高的程度取决于基本模型集的相对准确性以及其预测的独立性。 为了评估所有基本模型,这种提高的准确性是以每次预测消耗的计算资源增加为代价的。
The accuracy of a deployed model can silently degrade over time. Clipper’s online selection policies can automatically detect these failures using feedback and compensate by switching to another model (Exp3) or down-weighting the failing model (Exp4).
部署模型的准确性会随着时间的推移(其实不是时间的推移,而是推理样本量的增大)而略微下降。 Clipper的在线选择策略可以使用反馈自动检测这些失败的预测,并通过切换到其他模型(Exp3)或降低故障模型的权重(Exp4)进行补偿。
To evaluate how quickly and effectively the model selection policies react in the presence of changes in model accuracy, we simulated a severe model degradation while receiving real-time feedback.
为了评估模型选择策略在模型准确性变化的情况下如何快速有效地做出反应,我们在接收实时反馈的同时模拟了严重的模型失误。
Using the CIFAR dataset we trained five different Caffe models with varying levels of accuracy to perform object recognition. During a simulated run of 20K sequential queries with immediate feedback, we degraded the accuracy of the best-performing model after 5K queries and then allowed the model to recover after 10K queries.
使用CIFAR数据集,我们以不同的准确度训练了5个不同的Caffe模型以执行目标识别。在立即反馈的20K顺序查询模拟运行期间,我们降低了5K查询后最佳的模型的准确性,然后让该模型在10K查询后(逐渐)恢复。
In Figure 8 we plot the cumulative average error rate for each of the five base models as well as the single (Exp3) and ensemble (Exp4) model selection policies.
在图8中,我们绘制了五个基本模型以及单个(Exp3)和组合模型选择策略(Exp4)的累积平均错误率。

In the first 5K queries both model selection policies quickly converge to an error rate near the best performing model (model 5).
在第一个5K查询中,两个模型选择策略都迅速收敛到接近最佳性能模型(model 5)的错误率。
When we degrade the predictions from model 5 its cumulative error rate spikes.
当我们对模型5的预测进行降级时,其累积错误率会上升。
The model selection policies are able to quickly mitigate the consequences of the increase in errors by learning to divert queries to the other models.
通过选择将查询转移到其他模型,模型选择策略能够快速减轻错误增加的后果。
When model 5 recovers after 10K queries the model selection policies also begin to improve by gradually sending queries back to model 5.
在10K查询后模型5恢复时,通过逐渐将查询发送回模型5,模型选择策略也开始得到改进。
5.2.1 Robust Predictions
The advantages of online model selection go beyond detecting and mitigating model failures to leveraging new opportunities to improve application accuracy and performance. For many real-time decision-making applications, knowing the confidence of the prediction can significantly improve the end-user experience of the application.
在线模型选择的优势不仅仅在于检测和减轻模型故障,还在于利用新机会来提高应用程序的准确性和性能。 对于许多实时决策应用程序,了解预测的置信度可以显着改善应用程序的最终用户体验。
For example, in many settings, applications have a sensible default action they can take when a prediction is unavailable. This is critical for building highly available applications that can survive partial system failures or when building applications where a mistake can be costly.
例如,在许多设置中,当预测不可用时,应用程序会采用合理的默认值。 这对于构建可以在部分系统故障中幸免的高可用性应用程序或在构建错误可能代价高昂的应用程序时至关重要。
Rather than blindly using all predictions regardless of the confidence in the result, applications can choose to only accept predictions above a confidence threshold by using the robust model selection policy.
应用程序可以选择使用鲁棒的模型选择策略,选择仅接受超出置信度阈值的预测,而不是盲目地使用所有预测,不考虑预测结果的置信度。
When the confidence in a prediction for a query falls below the confidence threshold, the application can instead use the sensible default decision for the query and avoid a costly mistake.
当查询的预测中的置信度降至置信度阈值以下时,应用程序可以改为对查询使用合理的默认决策,从而避免代价高昂的错误。
By evaluating predictions from multiple competing models concurrently we can obtain an estimator of the confidence in our predictions.
通过同时评估来自多个竞争模型的预测,我们可以获得估计的可信度。
In settings where models have high variance or are trained on random samples from the training data (e.g., bagging), agreement in model predictions is an indicator of prediction confidence.
在模型具有高方差或在训练数据中随机抽取样本(例如bagging)的情况下,模型预测中的一致性是预测可信度的指标。
When evaluating the combine function in the ensemble selection policy we compute a measure of confidence by calculating the number of models that agree with the final prediction.
当评估整体选择策略中的组合函数时,我们通过计算与最终预测相符的模型数量来衡量计算置信度。
End user applications can use this confidence score to decide whether to rely on the prediction.
最终用户应用程序可以使用此置信度分数来决定是否使用预测结果。
If we only consider predictions where multiple models agree, we can substantially reduce the error rate (see Figure 7) while declining to predict a small fraction of queries.
如果仅考虑多个模型一致的预测,减少一小部分预测查询可以大幅降低错误率(见图7)。
图7:组合预测精度。 由应用于CIFAR和ImageNet基准的五个计算机视觉模型(表2)线性组合而成。 4-agree和5-agree对应于整体预测,其中查询已通过整体预测置信度(四个或五个模型相同)分开,并且每个条形的宽度定义了该类别中示例的比例。
5.2.2 Straggler Mitigation
While the ensemble model selection policy can improve prediction accuracy and help quantify uncertainty, it introduces additional system costs. As we increase the size of the ensemble the computational cost of rendering a prediction increases. Fortunately, we can compensate for the increased prediction cost by scaling-out the model abstraction layer. Unfortunately, as we add model containers we increase the chance of stragglers adversely affecting tail latencies.
虽然组合模型选择策略可以提高预测准确性并帮助量化不确定性,但它会带来额外的系统成本。 随着我们增加基础模型数量的大小,进行预测的计算成本会增加。 幸运的是,我们可以通过扩展模型抽象层来补偿增加的预测成本。 不幸的是,当我们添加模型容器时,我们增加了落后者对尾延时产生不利影响的机会。
To evaluate the cost of stragglers, we deployed ensembles of increasing size and measured the resulting prediction latency (Figure 9a) under moderate query load. Even with small ensembles we observe the effect of stragglers on the P99 tail latency, which rise sharply to well beyond the 20ms latency objective. As the size of the ensemble increases and the system becomes more heavily loaded, stragglers begin to affect the mean latency.
为了评估落后者的影响,我们在中等查询负载下部署了规模越来越大的组合模型并测量了产生的预测等待时间(图9a)。 即使使用小型组合,我们也可以观察到落后者对P99尾延迟的影响,该延迟急剧上升至远远超过20ms延迟目标。 随着整体规模的增加和系统负载的增加,落后者开始影响平均等待时间。

To address stragglers, Clipper introduces a simple best-effort straggler-mitigation strategy motivated by the design choice that rendering a late prediction is worse than rendering an inaccurate prediction. For each query the model selection layer maintains a latency deadline determined by the latency SLO. At the latency deadline the combine function of the model selection policy is invoked with the subset of the predictions that are available.
为了解决落后者问题,Clipper引入了一种简单的尽力而为的落后者缓解策略,该策略受设计选择的影响,即提供较晚的预测比提供不准确的预测更糟。 对于每个查询,模型选择层维护由延迟SLO确定的延迟期限。 在等待时间的最后期限,将模型选择策略的合并功能与可用的预测子集一起调用。(预设一个SLO延时,超时的模型就不管了,只组合现有预测结果)
The model selection policy must render a final prediction using only the available base model predictions and communicate the potential loss in accuracy in its confidence score.
模型选择策略必须仅使用可用的基本模型预测进行最终预测,并在其置信度评分中体现潜在的正确率损失。
Currently, we substitute missing predictions with their average value and define the confidence as the fraction of models that agree on the prediction.
目前,我们用(已有预测结果的)平均值代替缺失的预测,并将置信度定义为部分模型的预测置信度。(置信度这后半句没太看懂咋定义)
The best-effort straggler-mitigation strategy prevents model container tail latencies from propagating to frontend applications by maintaining the latency objective as additional models are deployed.
Best-effort straggler-mitigation策略通过新增模型时部署延时目标,防止模型容器尾延时传播到前端应用程序。
However, the straggler mitigation strategy reduces the size of the ensemble. In Figure 9b we plot the reduction in ensemble size and find that while tail latencies increase significantly with even small ensembles, most of the predictions arrive by the latency deadline.
但是,straggler mitigation策略可减小组合模型数量的大小。 在图9b中,我们绘制了组合模型数量大小的减小,发现即使在较小的数量中尾延迟也会显着增加,但大多数预测是在延迟期限之前得出的。
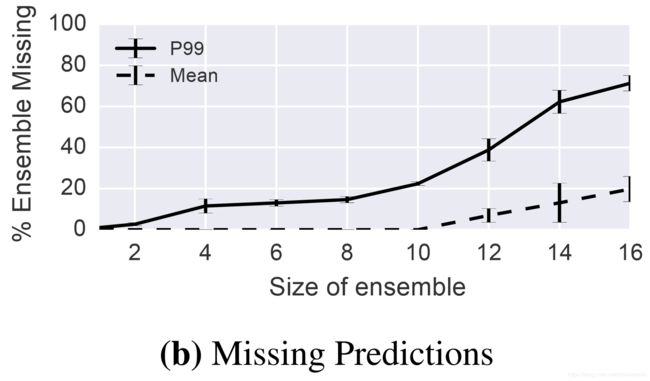
In Figure 9c we plot the effect of ensemble size on accuracy and observe that this ensemble can tolerate the loss of small numbers of component models with only a slight reduction in accuracy.
在图9c中,我们绘制了组合模型数量大小对精度的影响,并观察到组合模型可以容忍少量模型的缺失,而准确度仅略有降低。(个人感觉还是要大于8之后吧,从2到4变化还是挺大的。)

5.3 Contextualization 情景化
这一章暂且忽略吧,好像对我后面的工作没事帮助。
6 System Comparison
不翻译了,总结一下吧。
第6章就是和Tensorflow Seving做了一下对比。
对比了3个数据集(mnist--4层CNN、cifer10--8层AlexNet、imagenet--22层InceptionV3)。
Tensorflow Serving是用的python模型,Clipper用了C++和python两种模型。
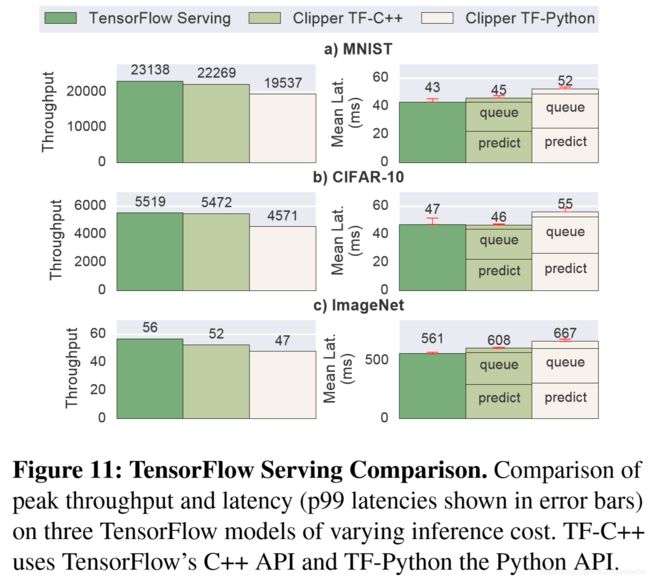
作者说图11显示,Clipper在吞吐量和延时方面与Tensorflow Serving差不多(comparable)。其实是比Tensorflow Serving哪方面都差点。