mongoDB的复制集2----同步机制(工作原理,oplog详解,初始化同步的过程
一、复制集是怎么工作的
1-1.复制集工作原理
Mongodb复制集由一组Mongod实例(进程)组成,包含一个Primary节点和多个Secondary节点,Mongodb Driver(客户端)的所有数据都写入Primary,Secondary从Primary同步写入的数据,以保持复制集内所有成员存储相同的数据集,提供数据的高可用。
下图(图片源于Mongodb官方文档)是一个典型的Mongdb复制集,包含一个Primary节点和2个Secondary节点。
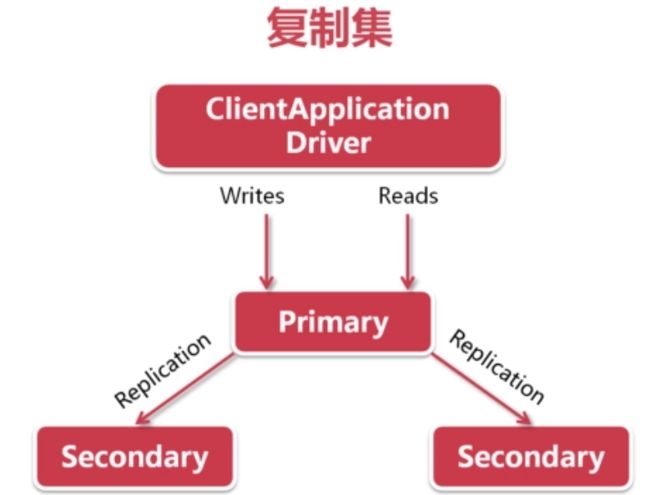
mongodb集群:复制,复制集和分片。 强烈建议在生产环境中使用mongodb的复制功能。复制具有故障切换,读扩展,热备份和离线批处理操作。
默认情况下,主节点负责客户端所有的读写请求,从节点不可读不可写。
工作原理
1). mongodb的复制至少需要两个实例。其中一个是主节点,负责处理客户端请求,其余的都是从节点,负责复制主节点上的数据。主节点记录在其上的所有操作oplog,从节点定期轮询主节点获取这些操作,然后对自己的数据副本执行这些操作,从而保证从节点的数据与主节点一致。
2). 主节点的操作记录称为oplog(operation log),存储在local数据库中(local数据库不会被复制,用来存放复制状态信息的)。oplog中的每个文档代表着主节点上执行的操作。oplog只作为从节点与主节点保持数据同步的机制。
3). oplog.rs是一个固定长度的capped collection。默认情况下,64位的实例将使用oplog 5%的可用空间,这个空间将在local数据库中分配,并在服务器启动时预先分配。
4). 如果从节点落后主节点很远了,oplog日志从节点还没执行完,oplog可能已经轮滚一圈了,那么从节点将会追赶不上主节点了,复制将会停止。从节点需要重新做完整的同步,可以用{resync:1}命令来手动执行重新同步或在启动从节点时指定--autoresync选项让其自动重新同步。重新同步的代价昂贵,应尽量避免,避免的方法就是配置足够大的oplog。
查看oplog信息:db.oplog.rs.stats()
查看oplog.rs内容:db.oplog.rs.find().limit(1).to
1-2.oplog是复制集的复制源
字段说明:
ts:操作的时间戳(8字节),用于跟踪操作执行的时间。
h : 此操作的独一无二的ID
v : oplog的版本
op:操作类型,i代表插入,u代表更新,d代表delete,cmd, null
ns:执行操作的集合名(命名空间),以db_name,coll_name
o : 操作对应的文档
o2: 仅update操作时有更新操作的变更条件
changwen:PRIMARY> use changwen
switched to db changwen
changwen:PRIMARY> db.changwen2.insert({"name":"insert_oplog_test"})
WriteResult({ "nInserted" : 1 })
changwen:PRIMARY> use local
switched to db local
changwen:PRIMARY> db.oplog.rs.find().sort({$natural:-1}).limit(1).pretty()
{
"ts" : Timestamp(1472480366, 1),
"t" : NumberLong(2),
"h" : NumberLong("-560593709840393662"),
"v" : 2,
"op" : "i",
"ns" : "changwen.changwen2",
"o" : {
"_id" : ObjectId("57c4446e0c13aa68781c47d5"),
"name" : "insert_oplog_test"
}
}
------------------------------------------------
changwen:PRIMARY> use changwen
switched to db changwen
changwen:PRIMARY> db.changwen2.update({"name":"insert_oplog_test"},{$set:{"name":"update_oplog_test"}})
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
changwen:PRIMARY> use local
switched to db local
changwen:PRIMARY> db.oplog.rs.find().sort({$natural:-1}).limit(1).pretty()
{
"ts" : Timestamp(1472481441, 1),
"t" : NumberLong(2),
"h" : NumberLong("6796117594516952707"),
"v" : 2,
"op" : "u",
"ns" : "changwen.changwen2",
"o2" : {
"_id" : ObjectId("57c4446e0c13aa68781c47d5")
},
"o" : {
"$set" : {
"name" : "update_oplog_test"
}
}
}
-----------------------------------------------
changwen:PRIMARY> use changwen
switched to db changwen
changwen:PRIMARY> db.changwen2.remove({"name":"update_oplog_test"})
WriteResult({ "nRemoved" : 1 })
changwen:PRIMARY> use local
switched to db local
changwen:PRIMARY> db.oplog.rs.find().sort({$natural:-1}).limit(1).pretty()
{
"ts" : Timestamp(1472481535, 1),
"t" : NumberLong(2),
"h" : NumberLong("-2737498259321252386"),
"v" : 2,
"op" : "d",
"ns" : "changwen.changwen2",
"o" : {
"_id" : ObjectId("57c4446e0c13aa68781c47d5")
}
}
--不要对数据进行物理删除,要进行逻辑删除,类似备份2-3.oplog的数据结构
oplog:
特点:封顶表Capped collection滚动覆盖写入,固定大小
什么是封顶表?
创建封顶表命令
db.createCollection("coll_name",
{capped:true,size:1024*1024*1024*4,[max:5000]})
--上面的大小为4G,[]为可选
默认大小:64位Linux,windows操作系统为当前分区可用空间5%,体积不会超过50G
--oplogSize 单位是mb
复制时间窗口:
按记录条数封顶
按文件体积封顶)(设置大小可以为40G)
二、复制集初始化同步的过程
初始前需要在配置文件设置replSet。
如下流程图是已存在的复制集,往这个复制集添加新的节点的流程。(添加节点命令rs.add()或者rs.addArb())

三、复制集的管理维护
1.眼光长远
即使(暂时)只有一台服务器,也要以单节点模式启动复制集
1).单机多实例启动复制集
2).单节点启动复制集
3-1.单节点启动复制集如下:
# 创建两个启动和连接shell脚本
changwen@ubuntu:~/shell$ cat start_mongoDB.sh
#!/bin/bash
port=$1
sudo /usr/local/mongoDB/bin/mongod -f /usr/local/mongoDB/conf/$port.conf
changwen@ubuntu:~/shell$ cat link_mongoDB.sh
#!/bin/bash
port=$1
sudo /usr/local/mongoDB/bin/mongo 192.168.23.129:$port
# 启动数据库
changwen@ubuntu:~/shell$ sh link_mongoDB.sh 28001
......
> config = { _id:"changwen", members:[ {_id:0, host:"192.168.23.129:28001"}]}
{
"_id" : "changwen",
"members" : [
{
"_id" : 0,
"host" : "192.168.23.129:28001"
}
]
}
> rs.initiate(config)
{ "ok" : 1 }
changwen:OTHER>
# 过大概一分钟再按enter
changwen:PRIMARY> rs.status()
{
"set" : "changwen",
"date" : ISODate("2016-08-30T14:26:59.829Z"),
"myState" : 1,
"term" : NumberLong(1),
"heartbeatIntervalMillis" : NumberLong(2000),
"members" : [
{
"_id" : 0,
"name" : "192.168.23.129:28001",
"health" : 1,
"state" : 1,
"stateStr" : "PRIMARY",
"uptime" : 1159,
"optime" : {
"ts" : Timestamp(1472567178, 1),
"t" : NumberLong(1)
},
"optimeDate" : ISODate("2016-08-30T14:26:18Z"),
"infoMessage" : "could not find member to sync from",
"electionTime" : Timestamp(1472567177, 2),
"electionDate" : ISODate("2016-08-30T14:26:17Z"),
"configVersion" : 1,
"self" : true
}
],
"ok" : 1
}
changwen:PRIMARY> show dbs
local 0.000GB
changwen:PRIMARY> use changwenDB
switched to db changwenDB
changwen:PRIMARY> db
changwenDB
changwen:PRIMARY> db.test.save({"name":"relpSet_initiate"})
WriteResult({ "nInserted" : 1 })
changwen:PRIMARY> db.test.find()
{ "_id" : ObjectId("57c597e85d6786a802bee7c5"), "name" : "relpSet_initiate" }
# 如果再增加实例,不要先配置文件(这样会有一小段时间的断开),用add方法
changwen:PRIMARY> rs.add
rs.add( rs.addArb(
changwen:PRIMARY> rs.add3-2.暂停服务
# 在上面的基础上操作
changwen:PRIMARY> rs.add({_id:1,host:"192.168.23.129:28002"})
{ "ok" : 1 }
changwen:PRIMARY> rs.add({_id:2,host:"192.168.23.129:28003"})
{ "ok" : 1 }
# 将发出这个命令的节点冻结
changwen:PRIMARY> rs.freeze(100)
{ "ok" : 1 }
# stepDown在多少秒的时间内让出主节点
changwen:PRIMARY> rs.stepDown(100)
......
changwen:SECONDARY>
# 然后就可以对28001进行其它操作了3-3.修改复制集成员属性
大多数操作都要主节点操作,所以需要直接在主节点操作
#如果其中一台服务器性能好,我们需要每次启动时都使用它,如下:
changwen:PRIMARY> config=rs.conf()
changwen:PRIMARY> config.members[0]
{
"_id" : 0,
"host" : "192.168.23.129:28001",
"arbiterOnly" : false,
"buildIndexes" : true,
"hidden" : false,
"priority" : 1,
"tags" : {
},
"slaveDelay" : NumberLong(0),
"votes" : 1
}
# 其中priority默认是1
changwen:PRIMARY> config.members[0].priority=5
5
# 让配置文件生效
changwen:PRIMARY> rs.reconfig(config)
{ "ok" : 1 }
changwen:PRIMARY>
2016-08-30T08:07:19.265-0700 I NETWORK [thread1] trying reconnect to 192.168.23.129:28002 (192.168.23.129) failed
2016-08-30T08:07:19.266-0700 I NETWORK [thread1] reconnect 192.168.23.129:28002 (192.168.23.129) ok
# 过段时间就成了从节点
changwen:SECONDARY>
# 在连接28001服务就会成从节点变成主节点1).将priority进行修改
2).将主节点rs.freeze(),rs.stepDown()
3-4.调整oplog大小
尽量变大,没事别变小