FreeAnchor: Learning to Match Anchors for Visual Object Detection阅读
摘要
现在基于CNN的算法都是使用IOU对目标分配Anchor,我们提出一种方法打破了IOU的限制,允许自由的分配Anchor。我们的方法,称为自由锚(FreeAnchor),将手工锚分配升级为“自由”锚匹配。
FreeAnchor的目标是学习最能分类和定位的特征。FreeAnchor可以和基于CNN的检测器随意融合。
介绍
为了使用有限卷积特征表示具有各种外观,纵横比和空间布局的物体,大多数基于CNN的检测器利用具有多尺度和多长宽比的锚框作为物体定位的参考点。通过将每个物体分配给单个或多个锚框,可以确定特征并进行物体分类和定位。有锚框的物体检测器利用空间关系,即物体和锚框的交并比(IoU),作为锚框划分的唯一标准。基于与物体边界框(Box)空间对齐的锚框(Anchor)最适合于对物体进行分类和定位的直觉,网络在每个锚框处的损失独立地监督下进行学习。然而,在下文中,我们认为这种直觉是不准确的,手工设计IoU匹配物体与特征的方法不是最佳选择。
一方面,对于“偏心”的物体,其最有判别力的特征并不靠近物体中心。空间对齐的锚框可能对应于较少的代表性特征,这会限制目标分类和定位能力。另一方面,当多个物体聚集在一起时,使用IoU标准匹配具有适当锚框/特征的物体是不可行的。亟待解决的问题是如何将锚框/特征与物体完美匹配。
本研究提出了一种学习匹配锚框的物体检测方法,目标是丢弃手工设计的锚框划分,同时优化以下三个视觉物体检测学习目标。首先,为了实现高召回率,检测器需要保证对于每个物体,至少一个锚框的预测足够准确。其次,为了实现高检测精度,检测器需要将具有较差定位(边界框回归误差大)的锚框分类为背景。第三,锚框的预测应该与非极大抑制(NMS)程序兼容,即分类得分越高,定位越准确。否则,在使用NMS过程时,可能抑制具有精确定位但是低分类分数的锚框预测。
本文贡献
- 将检测器训练作为一个最大似然估计(MLE)的训练过程,并将手工制作的锚分配更新为自由锚匹配。该方法突破了iou的限制,允许对象在最大似然原则下灵活地选择锚。
- 自定义了一种检测似然估计,并实现了端到端的分类和定位的联合优化。
相关工作
略
The Proposed Approach
为了实现以上目标,我们将物体-锚框匹配表示为最大似然估计(MLE)过程,从每个物体的锚框集合中选择最具代表性的锚框。定义每个锚框集合的似然概率为包中各锚框预测置信度的最大值,保证了存在至少一个锚框,对物体分类和定位都具有很高的置信度。同时,具有较大定位误差的锚框被归类为背景。在训练期间,似然概率被转换为损失函数,然后该函数同时驱动物体-锚框匹配和检测器的学习。
3.1 Detector Training as Maximum Likelihood Estimation
对于原始的单阶段检测器,给定一张输入图片,用![]() 表示图片中的物体,经过网络的前向传播后,每个锚框
表示图片中的物体,经过网络的前向传播后,每个锚框![]() 都将得到分类和回归的预测,基于IoU的手工设计准则将为每个锚框划分一个物体或者划分为背景,匹配矩阵
都将得到分类和回归的预测,基于IoU的手工设计准则将为每个锚框划分一个物体或者划分为背景,匹配矩阵![]() 表示物体
表示物体![]() 是否被划分给锚框
是否被划分给锚框![]() 。定义正例锚框集合
。定义正例锚框集合![]() 为
为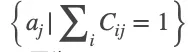 ,负例锚框集合
,负例锚框集合![]() 为
为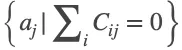 。其总体损失可写为:
。其总体损失可写为:
其中![]() 表示带学习的网络参数。
表示带学习的网络参数。![]() ,
,![]() ,
,![]() ,其中BCE为双线性交叉损失熵,用于分类;SmoothL1损失函数用于定位。
,其中BCE为双线性交叉损失熵,用于分类;SmoothL1损失函数用于定位。![]() 是一个正则因子。
是一个正则因子。
根据极大似然估计,原始的总体损失可以转化为似然概率:
要使![]() 最小,就要使
最小,就要使![]() 最大。这个似然概率描述了基于CNN的目标检测框架,严格约束了锚框分类和回归的优化,却忽略了对匹配矩阵
最大。这个似然概率描述了基于CNN的目标检测框架,严格约束了锚框分类和回归的优化,却忽略了对匹配矩阵![]() 的学习。
的学习。
3.2 Detection Customized Likelihood
为了实现物体-锚框匹配的优化,我们引入自由锚框匹配似然概率来扩展基于CNN的检测框架。所引入的似然概率在结合检测召回率和精度的要求的同时,保证与NMS的兼容性。
首先根据锚框与物体的空间关系选择n个IoU比较大的锚框为每个物体构建锚框集合![]() 。为了优化召回率,对于每个物体
。为了优化召回率,对于每个物体![]() ,需要保证至少存在一个锚框
,需要保证至少存在一个锚框![]() ,其预测(包括分类和回归)接近真实标注,其似然概率如下:
,其预测(包括分类和回归)接近真实标注,其似然概率如下:
![]()
为提高检测精度,检测器需要将定位不佳的锚框分类为背景,其似然概率如下:
![]()
其中 是
是![]() 错过所有物体的概率,
错过所有物体的概率,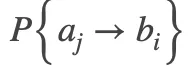 表示锚框
表示锚框![]() 正确预测物体
正确预测物体![]() 的概率。
的概率。
为了与NMS过程兼容,应具有以下三个属性:
(1)关于锚框![]() 预测结果与物体
预测结果与物体![]() 之间的交并比
之间的交并比 单调递增。
单调递增。
(2)小于阈值t时,为0.
(3)对于物体![]() ,存在一个满足
,存在一个满足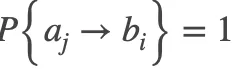 的
的![]() 。这些属性可以定义一个饱和线性函数来实现:
。这些属性可以定义一个饱和线性函数来实现:
,如下图
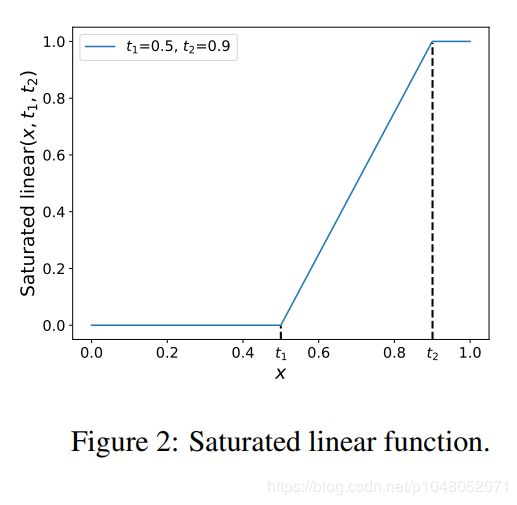
我们令![]() ,实现上面描述的三个属性,自由锚框匹配似然概率定义如下:
,实现上面描述的三个属性,自由锚框匹配似然概率定义如下:
它结合了召回率、精确和与NMS兼容的目标。通过优化这个似然概率,我们同时最大化召回率似然和精度似然,并且在检测器训练期间实现自由的物体-锚框匹配。
3.3 Anchor Matching Mechanism
为了在CNN检测框架中实现上述锚框-物体匹配方法,我们定义自由锚框匹配似然概率,并将似然概率转换为匹配损失,如下:
其中max函数用于为每个物体选择最佳锚框。在训练期间,从一个锚框集合A中选择单个锚框,然后使用该锚框来更新网络参数θ。但在训练早期,对于随机初始化的网络参数,所有锚框的置信度都很小,具有最高置信度的锚框不一定合适。因此,我们使用Mean-max函数选择锚框,定义如下:
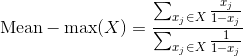
当训练不充分时,如下图所示,Mean-max函数将接近平均功能,这意味着锚框集合中的几乎所有锚框都用于训练。随着训练的进行,一些锚框的置信度增加,并且Mean-max函数更接近max函数。当充分训练网络后,Mean-max函数可以从锚框集合中为每个物体选择一个最佳锚框。
最终,用Mean-max函数替换检测定制损失中的max函数,增加平衡因子w1 w2,并将Focal Loss应用于损失的第二项,结果如下:
其中 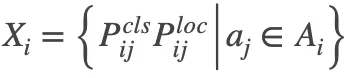 是每个物体对于锚框集合
是每个物体对于锚框集合![]() 的似然概率集合。通过从FocalLoss继承参数α和γ,得到
的似然概率集合。通过从FocalLoss继承参数α和γ,得到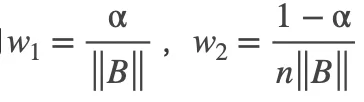 和
和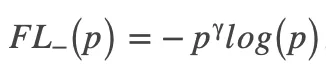 。
。
4 Experiments
FreeAnchor是通过最先进的一级探测器Retinanet实现的,使用resnet和resnext作为骨干网。通过将损失函数替换为提出的损失函数,将retinanet检测器升级为到自由锚探测器。对于分类子网的最后一个卷积层,我们设置偏差初始化为b=-log((1-ρ)=ρ),其中ρ=0:02。训练使用同步SGD,4块特斯拉v100 gpu,每小批共16个图像(每gpu 4个图像)。除非另有规定
指定,所有模型都经过90k次迭代训练,初始学习率为0.01,然后在60K时除以10,在80K迭代时再次除以10。
4.2 模型效果
1. 学习锚框匹配:所提出的学习匹配方法可以选择适当的锚框来表示感兴趣的物体,如图所示:

图为“笔记本电脑”学习匹配锚框(左)与手工设计锚框分配的比较(右),红点表示锚中心。较红的点表示较高的置信度。为清楚起见,我们从所有50个锚框中选择了16个长宽比为1:1的锚框。
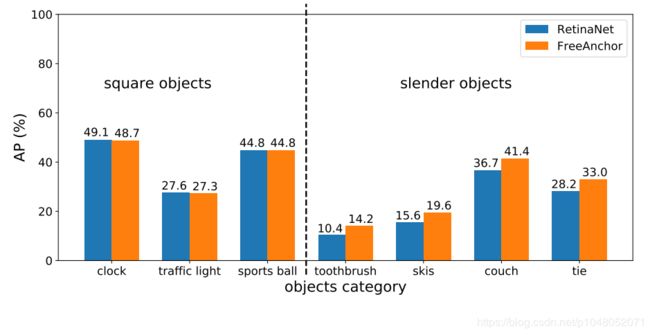
手工设计的锚框分配在两种情况下失败:物体特征偏心和拥挤场景。FreeAnchor有效地缓解了这两个问题。对于容易出现特征偏心的细长物体类别,如牙刷,滑雪板,沙发和领带,FreeAnchor显著优于RetinaNet基线,如图4所示。对于其他物体类别,包括时钟,交通信号灯和运动球FreeAnchor的性能相当与RetinaNet。其原因在于,学习匹配过程驱动网络激活每个物体的锚框集合内的至少一个锚框,以便预测正确的类别和位置。激活的锚框没有必要与物体空间对齐,只需要有对物体分类和定位的最具代表性的特征。
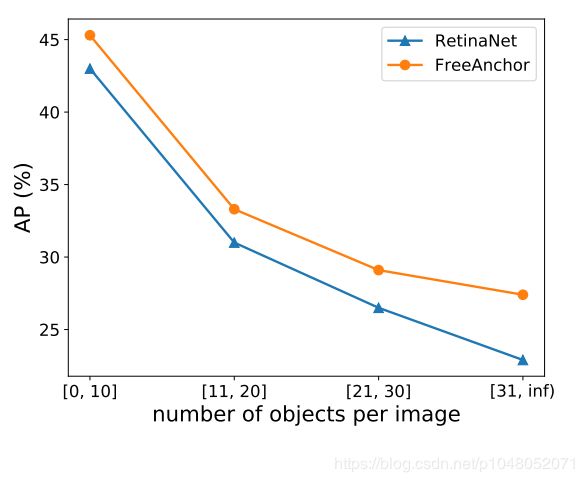
我们进一步比较了RetinaNet和FreeAnchor在拥挤场景中的表现,如图所示。随着单个图像中物体数量的增加,FreeAnchor对RetinaNet的提升变得越来越明显。这表明FreeAnchor具有学习匹配锚框的能力,可以在拥挤的场景中为物体选择更合适的锚框。
2. 保证与NMS的兼容性:为了评估锚框预测与NMS的兼容性,我们将NMS召回率(![]() )定义为给定IoU阈值τ时,在NMS之前和之前的召回率之比。遵循COCO中AP的定义方式,NR被定义为τ从0.50以0.05为间隔变化到0.90中NRτ的平均值。在表1.中我们用NRτ比较了RetinaNet和FreeAnchor。可以看出,FreeAnchor的NR值显著高于RetinaNet,意味着与NMS的兼容性更高,验证了自由锚框匹配损失可以实现分类和定位的联合优化。
)定义为给定IoU阈值τ时,在NMS之前和之前的召回率之比。遵循COCO中AP的定义方式,NR被定义为τ从0.50以0.05为间隔变化到0.90中NRτ的平均值。在表1.中我们用NRτ比较了RetinaNet和FreeAnchor。可以看出,FreeAnchor的NR值显著高于RetinaNet,意味着与NMS的兼容性更高,验证了自由锚框匹配损失可以实现分类和定位的联合优化。

检测性能
表2将FreeAnchor与RetinaNet基线进行比较。FreeAnchor通过可忽略不计的训练和测试时间成本将AP提升至3.5%左右,这对具有挑战性的通用物体检测任务来说是一个显著提升。

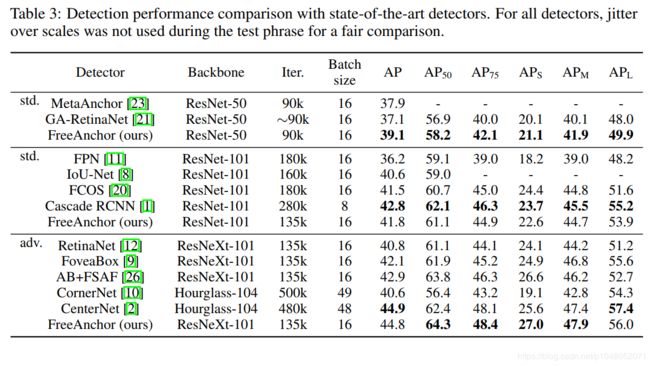
在表 3中FreeAnchor和其他方法进行了对比。它显著超出了Two-stage的FPN方法,也优于最新的基于点检测方法。在使用更少的训练迭代(135K vs 500K)和更少的网络参数(96.9M vs210.1M)前提下,FreeAnchor超过了CornerNet。
FreeAnchor的本质是通过目标与特征的自由匹配,实现为每个物体选择适合的锚框,其本质为每个物体选择合适的CNN特征。FreeAnchor突破了“Object as Box”, 与“Object as Point”的建模思路,通过极大似然估计对物体范围内的特征分配不同的置信度建立起一个无参数的分布,探索了“Object as Distribution”的新思路。