TIDB架构自我总结
TiDB 是什么?
TiDB 是一个分布式 NewSQL 数据库。它支持水平弹性扩展、ACID 事务、标准 SQL、MySQL 语法和 MySQL 协议,具有数据强一致的高可用特性,是一个不仅适合 OLTP 场景还适合 OLAP 场景的混合数据库。
TiDB怎么来的?
著名的开源分布式缓存服务 codis 的作者,PingCAP联合创始人& CTO ,资深 infrastructure 工程师的黄东旭,擅长分布式存储系统的设计与实现,开源狂热分子的技术大神级别人物。即使在互联网如此繁荣的今天,在数据库这片边界模糊且不确定地带,他还在努力寻找确定性的实践方向。
直到 2012 年底,他看到 Google 发布的两篇论文,如同棱镜般,折射出他自己内心微烁的光彩。这两篇论文描述了 Google 内部使用的一个海量关系型数据库 F1/Spanner ,解决了关系型数据库、弹性扩展以及全球分布的问题,并在生产中大规模使用。“如果这个能实现,对数据存储领域来说将是颠覆性的”,黄东旭为完美方案的出现而兴奋, PingCAP 的 TiDB 在此基础上诞生了。
TiDB架构
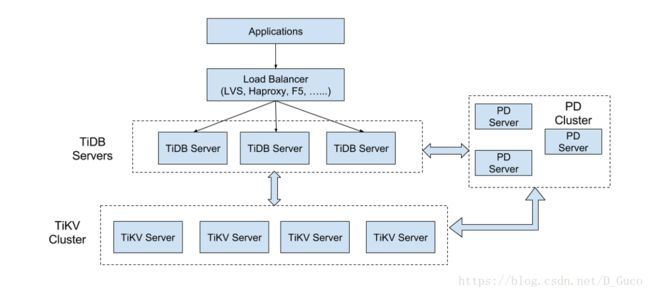
TiDB 集群主要分为三个组件:
1TiDB Server
TiDB Server 负责接收 SQL 请求,处理 SQL 相关的逻辑,并通过 PD 找到存储计算所需数据的 TiKV 地址,与 TiKV 交互获取数据,最终返回结果。 TiDB Server是无状态的,其本身并不存储数据,只负责计算,可以无限水平扩展,可以通过负载均衡组件(如LVS、HAProxy 或F5)对外提供统一的接入地址。
2PD Server
Placement Driver (简称 PD) 是整个集群的管理模块,其主要工作有三个: 一是存储集群的元信息(某个 Key 存储在哪个 TiKV 节点);二是对 TiKV 集群进行调度和负载均衡(如数据的迁移、Raft group leader的迁移等);三是分配全局唯一且递增的事务 ID。
PD 是一个集群,需要部署奇数个节点,一般线上推荐至少部署 3 个节点。
3TiKV Server
TiKV Server 负责存储数据,从外部看 TiKV 是一个分布式的提供事务的 Key-Value 存储引擎。存储数据的基本单位是 Region,每个 Region 负责存储一个 Key Range (从 StartKey 到EndKey 的左闭右开区间)的数据,每个 TiKV 节点会负责多个 Region 。TiKV 使用 Raft协议做复制,保持数据的一致性和容灾。副本以 Region 为单位进行管理,不同节点上的多个 Region 构成一个 RaftGroup,互为副本。数据在多个 TiKV 之间的负载均衡由 PD 调度,这里也是以 Region 为单位进行调度。
以上三个分别是指计算、调度、存储三个技术点:
这次重点讲一下存储:
TIKV采用的key-》value的数据模型,我们可以把TIKV想象为一个巨大的Map,里面的是按照Key的二进制的顺序进行排序,也就是可以认为里面存储的都是一个个key-》value对,在这里我们需要记住的是这里的存储模型与SQL中的Table无关!
RocksDb
任何持久化的存储引擎,数据终究都是要存储在磁盘之上的,TIKV也不例外,但是TIKV是没有选择直接将数据写在磁盘之上的,而是采用了RocksDB,将数据交给OocksDB,由它将数据写在磁盘上,他们采用这个的原因是开发单机的引擎要把各种细致化的话,还要满足他们的各种需求,工作量较大。所以他们直接采用了Fecebook开发的RocksDB来使用,这样的话,就是存储的数据模型和数据的落地已经选择好。
Raft
目前已经有一个高效可靠的本地存储机制,现在要做的就是要求数据的分布,单机的存储就算再强大,也会丢失数据,机器挂掉了,或者机房断电了,再或者地震了等等情况,都会造成数据的丢失,所以他们要实现数据的分布,也就是分布式。单机不可能支持高可用。他们在这里采用Raft协议,Raft是一致性协议,在这里我们简单的讲解一下Raft,采用这个协议可以达成三个目标:
1. Leader 选举
2. 成员变更
3. 日志复制
TIKV通过Raft来做数据复制,每个数据变更都会落地成为一条Raft日志,通过Raft的日志复制功能,将数据安全可靠地同步到group的多数节点中。
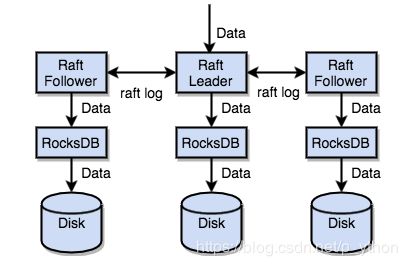
到这里我们总结一下,通过单机的RocksDB,我们可以将数据快速地存储在磁盘上;通过Raft,我们可以将数据复制到多台机器上,以防单机失效。数据的写入是通过Raft这一层的接口写入,而不是直接写RocksDB。通过实现Raft,我们拥有了一个分布式的KV,现在再也不用担心某台机器挂掉了。
Region
前面提到,我们将 TiKV 看做一个巨大的有序的 KV Map,那么为了实现存储的水平扩展,我们需要将数据分散在多台机器上。这里提到的数据分散在多台机器上和 Raft 的数据复制不是一个概念,在这一节我们先忘记 Raft,假设所有的数据都只有一个副本,这样更容易理解。
对于一个 KV 系统,将数据分散在多台机器上有两种比较典型的方案:一种是按照 Key 做 Hash,根据 Hash 值选择对应的存储节点;另一种是分 Range,某一段连续的 Key 都保存在一个存储节点上。TiKV 选择了第二种方式,将整个 Key-Value 空间分成很多段,每一段是一系列连续的 Key,我们将每一段叫做一个 Region,并且我们会尽量保持每个 Region 中保存的数据不超过一定的大小(这个大小可以配置,目前默认是 64MB)。每一个 Region 都可以用 StartKey 到 EndKey 这样一个左闭右开区间来描述。

注意,这里的 Region 还是和 SQL 中的表没什么关系! 请各位继续忘记 SQL,只谈 KV。
将数据划分成 Region 后,我们将会做两件重要的事情:
-
以 Region 为单位,将数据分散在集群中所有的节点上,并且尽量保证每个节点上服务的 Region 数量差不多
-
以 Region 为单位做 Raft 的复制和成员管理
这两点非常重要,我们一点一点来说。
先看第一点,数据按照 Key 切分成很多 Region,每个 Region 的数据只会保存在一个节点上面。我们的系统会有一个组件来负责将 Region 尽可能均匀的散布在集群中所有的节点上,这样一方面实现了存储容量的水平扩展(增加新的节点后,会自动将其他节点上的 Region 调度过来),另一方面也实现了负载均衡(不会出现某个节点有很多数据,其他节点上没什么数据的情况)。同时为了保证上层客户端能够访问所需要的数据,我们的系统中也会有一个组件记录 Region 在节点上面的分布情况,也就是通过任意一个 Key 就能查询到这个 Key 在哪个 Region 中,以及这个 Region 目前在哪个节点上。至于是哪个组件负责这两项工作,会在后续介绍。
对于第二点,TiKV 是以 Region 为单位做数据的复制,也就是一个 Region 的数据会保存多个副本,我们将每一个副本叫做一个 Replica。Repica 之间是通过 Raft 来保持数据的一致(终于提到了 Raft),一个 Region 的多个 Replica 会保存在不同的节点上,构成一个 Raft Group。其中一个 Replica 会作为这个 Group 的 Leader,其他的 Replica 作为 Follower。所有的读和写都是通过 Leader 进行,再由 Leader 复制给 Follower。
大家理解了 Region 之后,应该可以理解下面这张图:

我们以 Region 为单位做数据的分散和复制,就有了一个分布式的具备一定容灾能力的 KeyValue 系统,不用再担心数据存不下,或者是磁盘故障丢失数据的问题。这已经很 Cool,但是还不够完美,我们需要更多的功能。
MVCC
很多数据库都会实现多版本控制(MVCC),TiKV 也不例外。设想这样的场景,两个 Client 同时去修改一个 Key 的 Value,如果没有 MVCC,就需要对数据上锁,在分布式场景下,可能会带来性能以及死锁问题。
TiKV 的 MVCC 实现是通过在 Key 后面添加 Version 来实现,简单来说,没有 MVCC 之前,可以把 TiKV 看做这样的:
Key1 -> Value
Key2 -> Value
……
KeyN -> Value
有了 MVCC 之后,TiKV 的 Key 排列是这样的:
Key1-Version3 -> Value
Key1-Version2 -> Value
Key1-Version1 -> Value
……
Key2-Version4 -> Value
Key2-Version3 -> Value
Key2-Version2 -> Value
Key2-Version1 -> Value
……
KeyN-Version2 -> Value
KeyN-Version1 -> Value
……
注意,对于同一个 Key 的多个版本,我们把版本号较大的放在前面,版本号小的放在后面(回忆一下 Key-Value 一节我们介绍过的 Key 是有序的排列),这样当用户通过一个 Key + Version 来获取 Value 的时候,可以将 Key 和 Version 构造出 MVCC 的 Key,也就是 Key-Version。然后可以直接 Seek(Key-Version),定位到第一个大于等于这个 Key-Version 的位置。
这里有一篇更详细的文档,可以进一步阅读。
事务
TiKV 的事务采用的是 Percolator 【https://research.google.com/pubs/pub36726.html】模型,并且做了大量的优化。事务的细节这里不详述,大家可以参考论文以及我们的其他文章(点击阅读原文可查看)。这里只提一点,TiKV 的事务采用乐观锁,事务的执行过程中,不会检测写冲突,只有在提交过程中,才会做冲突检测,冲突的双方中比较早完成提交的会写入成功,另一方会尝试重新执行整个事务。当业务的写入冲突不严重的情况下,这种模型性能会很好,比如随机更新表中某一行的数据,并且表很大。但是如果业务的写入冲突严重,性能就会很差,举一个极端的例子,就是计数器,多个客户端同时修改少量行,导致冲突严重的,造成大量的无效重试。
欢迎加入TIDB技术交流群:606112401