Hadoop3.0安装以及新特性介绍
Apache Hadoop 3.0.0在前一个主要发行版本(hadoop-2.x)中包含了许多重要的增强功能
环境安装:
192.168.18.160 CDH1
192.168.18.161 CDH2
192.168.18.162 CDH3
192.168.18.163 CDH4
1,java8是必须
所有hadoop 的jar都是利用java8的运行时版本进行编译的。依然在使用java7或者更低版本的用户必须升级到Java8.
2,HDFS支持纠删码(Erasure Coding)
与副本相比纠删码是一种更节省空间的数据持久化存储方法。标准编码(比如Reed-Solomon(10,4))会有1.4 倍的空间开销;然而HDFS副本则会有3倍的空间开销。因为纠删码额外开销主要是在重建和执行远程读,它传统用于存储冷数据,即不经常访问的数据。当部署这个新特性时用户应该考虑纠删码的网络和CPU 开销。
3,MapReduce任务级本地优化
MapReduce添加了Map输出collector的本地实现。对于shuffle密集型的作业来说,这将会有30%以上的性能提升。更多内容请参见 MAPREDUCE-2841
4,支持多于2个的NameNodes
最初的HDFS NameNode high-availability实现仅仅提供了一个active NameNode和一个Standby NameNode;并且通过将编辑日志复制到三个JournalNodes上,这种架构能够容忍系统中的任何一个节点的失败。然而,一些部署需要更高的容错度。我们可以通过这个新特性来实现,其允许用户运行多个Standby NameNode。比如通过配置三个NameNode和五个JournalNodes,这个系统可以容忍2个节点的故障,而不是仅仅一个节点。HDFS high-availability文档已经对这些信息进行了更新,我们可以阅读这篇文档了解如何配置多于2个NameNodes。,
5,多个服务的默认端口被改变
在此之前,多个Hadoop服务的默认端口都属于Linux的临时端口范围(32768-61000)。这就意味着我们的服务在启动的时候可能因为和其他应用程序产生端口冲突而无法启动。现在这些可能会产生冲突的端口已经不再属于临时端口的范围,这些端口的改变会影响NameNode, Secondary NameNode, DataNode以及KMS。与此同时,官方文档也进行了相应的改变,具体可以参见 HDFS-9427以及HADOOP-12811。
6,Intra-datanode均衡器
一个DataNode可以管理多个磁盘,正常写入操作,各磁盘会被均匀填满。然而,当添加或替换磁盘时可能导致此DataNode内部的磁盘存储的数据严重内斜。这种情况现有的HDFS balancer是无法处理的。这种情况是由新intra-DataNode平衡功能来处理,通过hdfs diskbalancer CLI来调用。更多请参考HDFS Commands Guide,
7,重写守护进程以及任务的堆内存管理
Hadoop守护进程和MapReduce任务的堆内存管理发生了一系列变化。
HADOOP-10950:介绍了配置守护集成heap大小的新方法。主机内存大小可以自动调整,HADOOP_HEAPSIZE 已弃用。
MAPREDUCE-5785:map和reduce task堆大小的配置方法,所需的堆大小不再需要通过任务配置和Java选项实现。已经指定的现有配置不受此更改影响。
8,HDFS Router-Based Federation
HDFS Router-Based Federation 添加了一个 RPC路由层,提供了多个 HDFS 命名空间的联合视图。与现有 ViewFs 和 HDFS Federation 功能类似,不同之处在于挂载表(mount table)由服务器端(server-side)的路由层维护,而不是客户端。这简化了现有 HDFS客户端 对 federated cluster 的访问。 详细请参见:HDFS-10467,
9,YARN Resource Types
YARN 资源模型(YARN resource model)已被推广为支持用户自定义的可数资源类型(support user-defined countable resource types),不仅仅支持 CPU 和内存。比如集群管理员可以定义诸如 GPUs、软件许可证(software licenses)或本地附加存储器(locally-attached storage)之类的资源。YARN 任务可以根据这些资源的可用性进行调度。详细请参见: YARN-3926。
10,基于API来配置 Capacity Scheduler 队列的配置
OrgQueue 扩展了 capacity scheduler ,通过 REST API 提供了以编程的方式来改变队列的配置,This enables automation of queue configuration management by administrators in the queue’s administer_queue ACL.。详细请参见:YARN-5734
环境安装:
1、关闭防火墙
service iptables stop
2、配置免密码登录
ssh-keygen -t rsa 这个应该网上很多了,在这里不做过多的介绍了
3、解压Hadoop
[elk@cdh1 ~]$ tar -zxvf hadoop-3.0.0.tar.gz
4、hadoop配置
hadoop3.0需要配置的文件有core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml、hadoop-env.sh、workers
修改core-site.xml
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://cdh1:9000value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>file:///opt/hadoop3/tmpvalue>
property>
configuration>修改hdfs-site.xml
<configuration>
<property>
<name>dfs.replicationname>
<value>3value>
property>
<property>
<name>dfs.namenode.name.dirname>
<value>file:///opt/hadoop3/hdfs/namevalue>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>file:///opt/hadoop3/hdfs/datavalue>
property>
<property>
<name>dfs.namenode.secondary.http-addressname>
<value>cdh2:9001value>
property>
configuration>workers中设置slave节点,将slave机器的名称写入
cdh2
cdh3
cdh4mapred-site配置
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
<property>
<name>mapreduce.application.classpathname>
<value>
/opt/hadoop-3.0.0/etc/hadoop,
/opt/hadoop-3.0.0/share/hadoop/common/*,
/opt/hadoop-3.0.0/share/hadoop/common/lib/*,
/opt/hadoop-3.0.0/share/hadoop/hdfs/*,
/opt/hadoop-3.0.0/share/hadoop/hdfs/lib/*,
/opt/hadoop-3.0.0/share/hadoop/mapreduce/*,
/opt/hadoop-3.0.0/share/hadoop/mapreduce/lib/*,
/opt/hadoop-3.0.0/share/hadoop/yarn/*,
/opt/hadoop-3.0.0/share/hadoop/yarn/lib/*
value>
property>
configuration>上面的mapreduce.application.classpath一开始没有配置,导致使用mapreduce时报错
Error: Could not find or load main class org.apache.hadoop.mapreduce.v2.app.MRAppMaster
yarn-site.xml配置
<configuration>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.classname>
<value>org.apache.hadoop.mapred.ShuffleHandlevalue>
property>
<property>
<name>yarn.resourcemanager.resource-tracker.addressname>
<value>cdh1:8025value>
property>
<property>
<name>yarn.resourcemanager.scheduler.addressname>
<value>cdh1:8030value>
property>
<property>
<name>yarn.resourcemanager.addressname>
<value>cdh1:8040value>
property>
configuration>hadoop-env.sh中配置java_home
export JAVA_HOME=/opt/jdk1.8.0_111格式化namenode
[elk@cdh1 bin]$ hdfs namenode -format
如果看到了标注的字说明格式化成功了
启动hdfs 和yarn
[elk@cdh1 sbin]$ ./start-all.sh我们可以用过
http://192.168.18.160:8088
和http://192.168.18.160:9870 访问hdfs地址和YARN地址
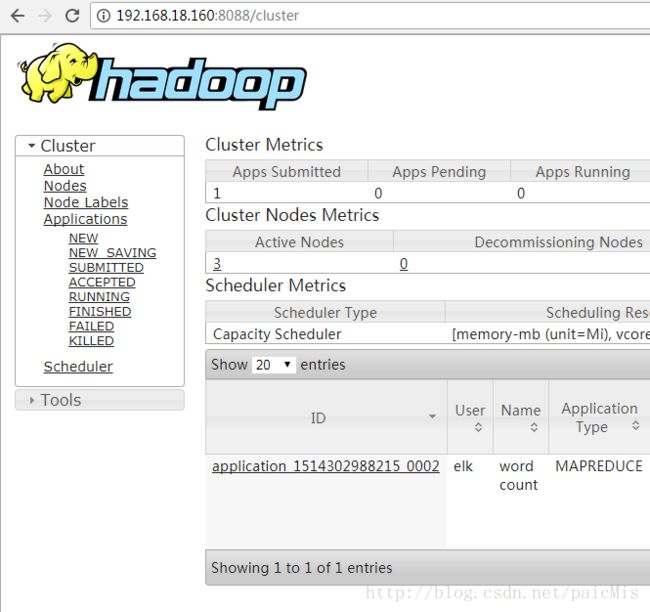
测试。命令基本和Hadoop2一样的
[elk@cdh1 sbin]$ hadoop fs -ls /
[elk@cdh1 sbin]$ hadoop fs -mkdir /user
[elk@cdh1 sbin]$ hadoop fs -ls /
drwxr-xr-x - elk supergroup 0 2017-12-26 23:24 /user执行MapReduce的时候失败
[2017-12-26 23:36:47.058]Container exited with a non-zero exit code 1. Error file: prelaunch.err.
Last 4096 bytes of prelaunch.err :
Last 4096 bytes of stderr :
Error: Could not find or load main class org.apache.hadoop.mapreduce.v2.app.MRAppMaster
Please check whether your etc/hadoop/mapred-site.xml contains the below configuration:
<property>
<name>yarn.app.mapreduce.am.envname>
HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}
property>
<property>
<name>mapreduce.map.envname>
HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}
property>
<property>
<name>mapreduce.reduce.envname>
HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}
property>运行成功
[elk@cdh1 mapreduce]$
[elk@cdh1 mapreduce]$ hadoop jar hadoop-mapreduce-examples-3.0.0.jar wordcount /user/passwd /output
2017-12-26 23:43:58,173 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2017-12-26 23:43:59,210 INFO client.RMProxy: Connecting to ResourceManager at cdh1/192.168.18.160:8040
2017-12-26 23:43:59,817 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/elk/.staging/job_1514302988215_0002
2017-12-26 23:44:01,017 INFO input.FileInputFormat: Total input files to process : 1
2017-12-26 23:44:01,198 INFO mapreduce.JobSubmitter: number of splits:1
2017-12-26 23:44:01,238 INFO Configuration.deprecation: yarn.resourcemanager.system-metrics-publisher.enabled is deprecated. Instead, use yarn.system-metrics-publisher.enabled
2017-12-26 23:44:01,387 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1514302988215_0002
2017-12-26 23:44:01,389 INFO mapreduce.JobSubmitter: Executing with tokens: []
2017-12-26 23:44:01,608 INFO conf.Configuration: resource-types.xml not found
2017-12-26 23:44:01,608 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2017-12-26 23:44:01,890 INFO impl.YarnClientImpl: Submitted application application_1514302988215_0002
2017-12-26 23:44:01,944 INFO mapreduce.Job: The url to track the job: http://cdh1:8088/proxy/application_1514302988215_0002/
2017-12-26 23:44:01,945 INFO mapreduce.Job: Running job: job_1514302988215_0002
2017-12-26 23:44:11,098 INFO mapreduce.Job: Job job_1514302988215_0002 running in uber mode : false
2017-12-26 23:44:11,101 INFO mapreduce.Job: map 0% reduce 0%
2017-12-26 23:44:19,223 INFO mapreduce.Job: map 100% reduce 0%
2017-12-26 23:44:25,269 INFO mapreduce.Job: map 100% reduce 100%
2017-12-26 23:44:25,290 INFO mapreduce.Job: Job job_1514302988215_0002 completed successfully
2017-12-26 23:44:25,468 INFO mapreduce.Job: Counters: 53
File System Counters
FILE: Number of bytes read=1963
FILE: Number of bytes written=415199
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=1758
HDFS: Number of bytes written=1741
HDFS: Number of read operations=8
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=4962
Total time spent by all reduces in occupied slots (ms)=3408
Total time spent by all map tasks (ms)=4962
Total time spent by all reduce tasks (ms)=3408
Total vcore-milliseconds taken by all map tasks=4962
Total vcore-milliseconds taken by all reduce tasks=3408
Total megabyte-milliseconds taken by all map tasks=5081088
Total megabyte-milliseconds taken by all reduce tasks=3489792
Map-Reduce Framework
Map input records=35
Map output records=55
Map output bytes=1885
Map output materialized bytes=1963
Input split bytes=93
Combine input records=55
Combine output records=54
Reduce input groups=54
Reduce shuffle bytes=1963
Reduce input records=54
Reduce output records=54
Spilled Records=108
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=100
CPU time spent (ms)=2130
Physical memory (bytes) snapshot=523571200
Virtual memory (bytes) snapshot=5573931008
Total committed heap usage (bytes)=443023360
Peak Map Physical memory (bytes)=302100480
Peak Map Virtual memory (bytes)=2781454336
Peak Reduce Physical memory (bytes)=221470720
Peak Reduce Virtual memory (bytes)=2792476672
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=1665
File Output Format Counters
Bytes Written=1741