xxl-job源码阅读笔记
xxl-job源码阅读笔记
官方文档地址:分布式任务调度平台xxl-job
Github地址:https://github.com/xuxueli/xxl-job/
阅读源码版本:2.1.1-SNAPSHOT (当前Master主干)
Maven3+
Jdk1.7+
Mysql5.6+
一、架构图
xxl-job分为调度中心和执行器。调度中心分配任务,根据任务列表cron表达式、分配策略(Hash、轮循)计算出具体由哪个执行器执行任务。执行器负责具体任务的执行。执行器启动后向调度中心注册自己,也可以在调度中心手工注册执行器地址和端口(在多网卡容器出错时使用)。调度中心和执行器之间通过自研RPC通信。最后是由JobHandler进行具体的任务。
[外链图片转存失败(img-L19TybEG-1569134487438)(https://live.staticflickr.com/65535/48735850558_366afcaa56_b.jpg)]
二、定时任务
XxlJobScheduler因为继承InitializingBean,而InitializingBean接口为bean提供了初始化方法的方式,它只包括afterPropertiesSet方法,凡是继承该接口的类,在spring初始化bean的时候会执行该方法。
2.1 执行流程图
定时任务执行流程图如下所示,点击看大图:

通过继承InitializingBean,在spring初始化bean的时候,执行afterPropertiesSet()。
- 在
afterPropertiesSet()中,初始化rpc:创建XxlRpcProviderFactory,通过initConfig()初始化XxlRpcProviderFactory配置;将AdminBiz类全名和AdminBiz实现类传给xxlRpcProviderFactory;创建ServletServerHandler,构造参为xxlRpcProviderFactory,最后由客户端调用时,由servletServerHandler.handle()调用AdminBiz的方法。 - 运行定时任务
- 创建一个
Daemon线程,在while循环中更新定时任务的执行时间,符合定时任务表达式条件的,执行任务。关于算法后另起一章。 - 执行
JobTriggerPoolHelper.addTrigger()中维护2个线程池,线程池中调用XxlJobTrigger.trigger()。两个线程池:fastTriggerPool、slowTriggerPool,如果1分钟内10次任务超时,会由slowTriggerPool执行。 - 在
XxlJobTrigger.trigger()中查询数据库,根据jobId获取任务信息。 - 调用
processTrigger(),根据入参triggerParam和addressList判断路由到哪个执行器执行。 - 在
runExecutor(TriggerParam triggerParam, String address)中,通过RPC的方式远程调用真正的执行器。xxl-job内部封装了基于jetty/netty的RPC通信框架:xxl-rpc-core。
- 创建一个
2.2 XxlJobScheduler初始化和执行定时任务
@DependsOn控制bean加载顺序
@Component
@DependsOn("xxlJobAdminConfig")
public class XxlJobScheduler implements InitializingBean, DisposableBean {
@Override
public void afterPropertiesSet() throws Exception {
// init i18n
initI18n();
// admin registry monitor run
JobRegistryMonitorHelper.getInstance().start();
// admin monitor run
JobFailMonitorHelper.getInstance().start();
// admin-server
initRpcProvider();
// start-schedule
JobScheduleHelper.getInstance().start();
logger.info(">>>>>>>>> init xxl-job admin success.");
}
//...
}
此方法中有2个重要的方法:initRpcProvider()、JobScheduleHelper.getInstance().start()
initRpcProvider()作用:
- 初始化Rpc,通过
xxlRpcProviderFactory初始化 - 将
AdminBiz类全名和AdminBiz实现类传给xxlRpcProviderFactory - 创建
ServletServerHandler,构造参为xxlRpcProviderFactory,最后由执行器调用时,由servletServerHandler#handle调用AdminBiz的方法。比如执行器进行注册时,会这样调用:JobApiController#api->XxlJobScheduler#invokeAdminService->ServletServerHandler#handle->xxlRpcProviderFactory#invokeService->ServletServerHandler#writeResponse
Rpc调度器初始化代码如下:
private void initRpcProvider(){
// init
XxlRpcProviderFactory xxlRpcProviderFactory = new XxlRpcProviderFactory();
xxlRpcProviderFactory.initConfig(
NetEnum.NETTY_HTTP,
Serializer.SerializeEnum.HESSIAN.getSerializer(),
null,
0,
XxlJobAdminConfig.getAdminConfig().getAccessToken(),
null,
null);
// add services
xxlRpcProviderFactory.addService(AdminBiz.class.getName(), null, XxlJobAdminConfig.getAdminConfig().getAdminBiz());
// servlet handler
servletServerHandler = new ServletServerHandler(xxlRpcProviderFactory);
}
//最后由客户端调用AdminBiz的方法
public static void invokeAdminService(HttpServletRequest request, HttpServletResponse response) throws IOException, ServletException {
servletServerHandler.handle(null, request, response);
}
//...
}
JobScheduleHelper.getInstance().start()执行定时任务
start()方法代码太长,和调度策略单独放一章说明算法。
大体过程:
- 根据定时任务策略,筛选出要执行的任务,触发任务。
- 触发任务后,根据调度策略,选择执行器IP。
- RPC调用执行器。
- 返回结果,写日志。如果执行失败,则写失败日志。调度器会一个失败线程检测失败的日志,如果重试次数大于0,则进行任务重试。
三、执行器向调度中心注册
执行器需要配置:调度中心地址、appName(用于各执行器业务隔离)、IP和Port(自动注册的可以不写IP)、Token、日志保留天数。在执行器系统中需要一个类:XxlJobConfig,在这个类中,通过start()方法初始化jobHandler、初始化调度中心地址、初始化日志文件删除线程、初始化回调、和初始化RPC。
3.1 注册流程
- 在spring启动时,调用XxlJobConfig#xxlJobExecutor对执行器进行初始化,读取配置参数。
- 执行XxlJobSpringExecutor#start进行具体的初始化操作。
- 初始化JobHandler,将系统中带有JobHandler注解的取出来,放入到ConcurrentMap
- 创建SpringGlueFactory工厂类
- 初始化文件日志路径、初始化调度器列表、启动文件日志清除线程、启动回调线程、初始化RPC。
- 初始化JobHandler,将系统中带有JobHandler注解的取出来,放入到ConcurrentMap
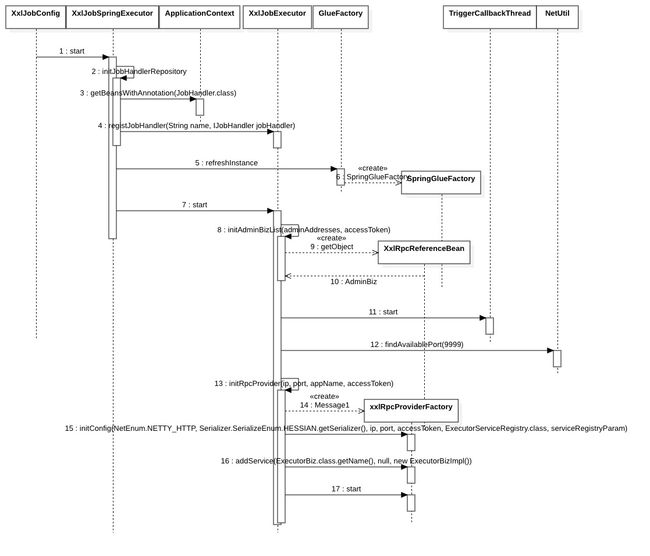
3.2 初始化JobHandler
// init job handler action
Map<String, Object> serviceBeanMap = applicationContext.getBeansWithAnnotation(JobHandler.class);
if (serviceBeanMap!=null && serviceBeanMap.size()>0) {
for (Object serviceBean : serviceBeanMap.values()) {
if (serviceBean instanceof IJobHandler){
String name = serviceBean.getClass().getAnnotation(JobHandler.class).value();
IJobHandler handler = (IJobHandler) serviceBean;
//...
registJobHandler(name, handler);
}
}
}
3.3 XxlJobExecutor#run 初始化其它
-
初始化文件日志路径
-
初始化调度列表
initAdminBizListprivate void initAdminBizList(String adminAddresses, String accessToken) throws Exception { serializer = Serializer.SerializeEnum.HESSIAN.getSerializer(); if (adminAddresses!=null && adminAddresses.trim().length()>0) { for (String address: adminAddresses.trim().split(",")) { if (address!=null && address.trim().length()>0) { String addressUrl = address.concat(AdminBiz.MAPPING); AdminBiz adminBiz = (AdminBiz) new XxlRpcReferenceBean( NetEnum.NETTY_HTTP, serializer, CallType.SYNC, LoadBalance.ROUND, AdminBiz.class, null, 3000, addressUrl, accessToken, null, null ).getObject(); if (adminBizList == null) { adminBizList = new ArrayList<AdminBiz>(); } adminBizList.add(adminBiz); } } } } -
启动文件日志清除线程
-
启动回调线程,为后面执行完任务,调度器执行回调用。(后面有执行器具体的执行过程)
-
初始化RPC
private void initRpcProvider(String ip, int port, String appName, String accessToken) throws Exception { // init, provider factory String address = IpUtil.getIpPort(ip, port); Map<String, String> serviceRegistryParam = new HashMap<String, String>(); serviceRegistryParam.put("appName", appName); serviceRegistryParam.put("address", address); xxlRpcProviderFactory = new XxlRpcProviderFactory(); xxlRpcProviderFactory.initConfig(NetEnum.NETTY_HTTP, Serializer.SerializeEnum.HESSIAN.getSerializer(), ip, port, accessToken, ExecutorServiceRegistry.class, serviceRegistryParam); // add services xxlRpcProviderFactory.addService(ExecutorBiz.class.getName(), null, new ExecutorBizImpl()); // start xxlRpcProviderFactory.start(); }先创建
XxlRpcProviderFactory,然后初始化RPC工厂,这里可以看到,默认使用的是NETTY_HTTP,序列化方式使用HESSIAN执行器在初始化的时候,如果没有填写IP,那么会调用Java原生的
InetAddress.getLocalHost()获取IP(InetAddress)。将
ExecutorBiz、new ExecutorBizImpl()放到工厂中,以便和调度器进行RPC通信。启动
XxlRpcProviderFactorstart(),最后调用Netty。ServerBootstrap bootstrap = new ServerBootstrap(); ((ServerBootstrap)bootstrap.group(bossGroup, workerGroup).channel(NioServerSocketChannel.class)).childHandler(new ChannelInitializer<SocketChannel>() { public void initChannel(SocketChannel channel) throws Exception { channel.pipeline().addLast(new ChannelHandler[]{new IdleStateHandler(0L, 0L, 10L, TimeUnit.MINUTES)}).addLast(new ChannelHandler[]{new NettyDecoder(XxlRpcRequest.class, xxlRpcProviderFactory.getSerializer())}).addLast(new ChannelHandler[]{new NettyEncoder(XxlRpcResponse.class, xxlRpcProviderFactory.getSerializer())}).addLast(new ChannelHandler[]{new NettyServerHandler(xxlRpcProviderFactory, serverHandlerPool)}); } }).childOption(ChannelOption.TCP_NODELAY, true).childOption(ChannelOption.SO_KEEPALIVE, true); ChannelFuture future = bootstrap.bind(xxlRpcProviderFactory.getPort()).sync(); NettyServer.logger.info(">>>>>>>>>>> xxl-rpc remoting server start success, nettype = {}, port = {}", NettyServer.class.getName(), xxlRpcProviderFactory.getPort()); NettyServer.this.onStarted(); future.channel().closeFuture().sync();
四、执行器执行过程
4.1 调用总流程
调度器调度ExecutorBizImpl#run大体分为以下几个步骤
ExecutorBiz#run创建JobThread,将triggerParam(执行器的参数,包括jobParam) 放入LinkedBlockingQueue中。- 执行任务由
Jobthread执行。从LinkedBlockingQueue中取出triggerParam,执行IJobHandler#executor,执行目标任务,所有的任务最后都是由IJobHandler#executor执行。 - 执行回调方法:
Adminbiz#callback,这方法中主要是调度器执行子任务以及记录日志。
调用流程如下图所示
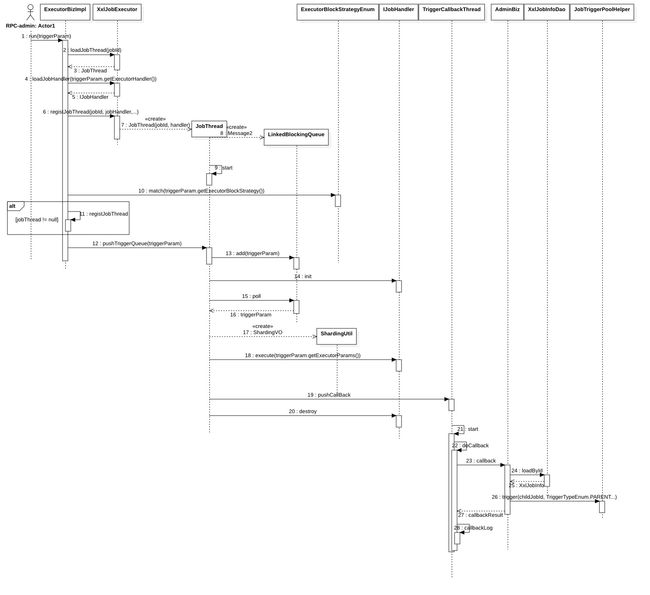
4.2 ExecutorBiz#run
-
XxlJobExecutor.loadJobThread根据jobId在ConcurrentMap中取出当前线程,如果没有则后面创建一个,也就是说一个jobId对应一个JobThread,创建后通过start()方法启动起来,将它放到Map中,jobThreadRepository.put(jobId, newJobThread),缓存到ConcurrentMap中是为了线程复用,不用每次执行完再执行时,创建一个新线程。后面有JobThread线程回收的方法。 -
判断任务执行器类型,获取相对类型的
jobHandler,目前以下模式:BEAN模式:任务以JobHandler方式维护在执行器端;需要结合 "JobHandler" 属性匹配执行器中任务; GLUE模式(Java):任务以源码方式维护在调度中心;该模式的任务实际上是一段继承自IJobHandler的Java类代码并 "groovy" 源码方式维护,它在执行器项目中运行,可使用@Resource/@Autowire注入执行器里中的其他服务; GLUE模式(Shell):任务以源码方式维护在调度中心;该模式的任务实际上是一段 "shell" 脚本; GLUE模式(Python):任务以源码方式维护在调度中心;该模式的任务实际上是一段 "python" 脚本; GLUE模式(PHP):任务以源码方式维护在调度中心;该模式的任务实际上是一段 "php" 脚本; GLUE模式(NodeJS):任务以源码方式维护在调度中心;该模式的任务实际上是一段 "nodejs" 脚本; GLUE模式(PowerShell):任务以源码方式维护在调度中心;该模式的任务实际上是一段 "PowerShell" 脚本;springboot使用BEAN模式,先根据任务配置handler名称参数取handler实例
IJobHandler newJobHandler = XxlJobExecutor.loadJobHandler(triggerParam.getExecutorHandler()); -
判断当前的阻塞类型,目前支持2种:丢弃,如果当前线程正在执行中,则丢弃后面的任务;覆盖,如果当前线程执行中,则关掉当前线程。
ExecutorBlockStrategyEnum blockStrategy = ExecutorBlockStrategyEnum.match(triggerParam.getExecutorBlockStrategy(), null); if (ExecutorBlockStrategyEnum.DISCARD_LATER == blockStrategy) { // discard when running if (jobThread.isRunningOrHasQueue()) { return new ReturnT<String>(ReturnT.FAIL_CODE, "block strategy effect:"+ExecutorBlockStrategyEnum.DISCARD_LATER.getTitle()); } } else if (ExecutorBlockStrategyEnum.COVER_EARLY == blockStrategy) { // kill running jobThread if (jobThread.isRunningOrHasQueue()) { removeOldReason = "block strategy effect:" + ExecutorBlockStrategyEnum.COVER_EARLY.getTitle(); jobThread = null; } } else { // just queue trigger } -
如果第一步中
XxlJobExecutor.loadJobThread取出的jobThread为空,则创建并注册一个新的线程。jobThread = XxlJobExecutor.registJobThread(triggerParam.getJobId(), jobHandler, removeOldReason);这里创建线程时,会传入jobId、handler,后面执行时会用到。
public static JobThread registJobThread(int jobId, IJobHandler handler, String removeOldReason){ JobThread newJobThread = new JobThread(jobId, handler); newJobThread.start(); logger.info(">>>>>>>>>>> xxl-job regist JobThread success, jobId:{}, handler:{}", new Object[]{jobId, handler}); JobThread oldJobThread = jobThreadRepository.put(jobId, newJobThread); // putIfAbsent | oh my god, map's put method return the old value!!! if (oldJobThread != null) { oldJobThread.toStop(removeOldReason); oldJobThread.interrupt(); } return newJobThread; } -
将
triggerParam放入到jobThread队列中。ReturnT<String> pushResult = jobThread.pushTriggerQueue(triggerParam);jobThread之前已经启动起来了,在run()方法中,当队列中有triggerParam时,会执行handler.execute方法。
4.3 JobThread#run
JotThread有了jobId、handler,在队列中取出triggerParam,就可以真正执行handler.execute了。
JobThread.run(),进入后,调用IJobHandler#init方法,IJobHandler除了提供执行时的execute()方法,还提供调用之前init()和调用后destroy()方法。
-
取triggerParam
triggerParam = triggerQueue.poll(3L, TimeUnit.SECONDS); -
获取分片信息。执行器集群部署时,任务路由策略选择"分片广播"情况下,一次任务调度将会广播触发对应集群中所有执行器执行一次任务,同时系统自动传递分片参数;可根据分片参数开发分片任务;
ShardingUtil.setShardingVo(new ShardingUtil.ShardingVO(triggerParam.getBroadcastIndex(), triggerParam.getBroadcastTotal())); -
执行
handler.executeexecuteResult = handler.execute(triggerParam.getExecutorParams());得到结果集后,写文件日志。如果执行异常,则写异常日志。
-
如果while中取队列的时候,30次取不到,则删除当前工作线程。
XxlJobExecutor.removeJobThread(jobId, "excutor idel times over limit."); -
执行
TriggerCallbackThread.pushCallBack,将HandleCallbackParam参数推入队列中。之前在执行器启动时,通过XxlJobConfig->XxlJobSpringExecutor#start-> XxlJobExecutor#start->TriggerCallbackThread.getInstance().start() 进行了线程的启动。
getInstance().callBackQueue.add(callback);在TriggerCallbackThread#start中,通过RPC调用调度器callback方法:adminBiz#callback
终止JobThread线程
Thread.interrupt只支持终止线程的阻塞状态(wait、join、sleep),
在阻塞出抛出InterruptedException异常,但是并不会终止运行的线程本身;
所以需要注意,此处彻底销毁本线程,需要通过共享变量方式;
进while(!toStop)循环,在最开始时使用idleTimes计数。在JobThread当中,使用volatile boolean toStop来停止线程。当triggerQueue中无法取出triggerParam30次,则会停止当前线程。调用XxlJobExecutor.removeJobThread(jobId, "excutor idel times over limit.");来真正停止。
public static void removeJobThread(int jobId, String removeOldReason){
JobThread oldJobThread = jobThreadRepository.remove(jobId);
if (oldJobThread != null) {
oldJobThread.toStop(removeOldReason);
oldJobThread.interrupt();
}
}
4.3 AdminBiz#callback
-
查询XxlJobInfo信息,主要是为了执行子任务。
XxlJobInfo xxlJobInfo = xxlJobInfoDao.loadById(log.getJobId());执行子任务
for (int i = 0; i < childJobIds.length; i++) { //... JobTriggerPoolHelper.trigger(childJobId, TriggerTypeEnum.PARENT, -1, null, null); //... } -
更新日志
xxlJobLogDao.updateHandleInfo(log)
五、算法
5.1 路由算法
路由策略:执行器集群部署时提供丰富的路由策略,包括:
第一个(ExecutorRouteFirst)、最后一个(ExecutorRouteLast)、轮询(ExecutorRouteRound)、随机(ExecutorRouteRandom)、一致性HASH(ExecutorRouteConsistentHash)、最不经常使用(ExecutorRouteLFU)、最近最久未使用(ExecutorRouteLRU)、故障转移(ExecutorRouteFailover)、忙碌转移(ExecutorRouteBusyover)等;
官网说明:
调度密集或者耗时任务可能会导致任务阻塞,集群情况下调度组件小概率情况下会重复触发; 针对上述情况,可以通过结合 “单机路由策略(如:第一台、一致性哈希)” + “阻塞策略(如:单机串行、丢弃后续调度)” 来规避,最终避免任务重复执行。
第一个台路由策略,只是从地址列表中取第一个执行器执行,不推荐。
public class ExecutorRouteFirst extends ExecutorRouter {
@Override
public ReturnT<String> route(TriggerParam triggerParam, List<String> addressList){
return new ReturnT<String>(addressList.get(0));
}
}
一致性Hash。
-
计算HashCode。实现一致性哈希算法中使用的哈希函数,使用MD5算法来保证一致性哈希的平衡性
- 计算摘要的第一步是创建报文摘要实例,此处选择MD5:
MessageDigest.getInstance("MD5") - 计算数据的摘要的第二步是向已初始化的报文摘要对象提供数据。更新摘要:
md5.update(keyBytes); - 通过调用
update方法提供数据后,程序就调用以下某个digest(摘要)方法来计算摘要:byte[] digest = md5.digest(),digest.length=16。
- 计算摘要的第一步是创建报文摘要实例,此处选择MD5:
-
由于一般的哈希函数返回一个int(32bit)型的hashCode。因此,可以将该哈希函数能够返回的hashCode表示成一个范围为0—(2^32)-1 环。此处是一个long。
先将ipList地址做hash,得到一个ip hash list存入到treeMap中,相当于分布到环上。当执行任务时,根据jobId做hash运算,得到一个值,使用treeMap#tailMap方法,取所有大于jobId的ipList,最后在结果集中取第一个,后返对应的ip地址。就这是整个一致性Hash选取执行器ip地址的过程。
Redis cluster依赖的一个核心的算法,一致性哈希算法,也是用的下面的hash算法。作用也是差不多:为了当新任务加进来的时候可以均匀的分布;当新加一个redis节点的时候,数据所存储的机器要么是新机器,要么是原来的旧机器,不会产生旧机器A上的数据需要转移到旧机器B上,保证了单调一致性。
/**
* 分组下机器地址相同,不同JOB均匀散列在不同机器上,保证分组下机器分配JOB平均;且每个JOB固定调度其中一台机器;
* a、virtual node:解决不均衡问题
* b、hash method replace hashCode:String的hashCode可能重复,需要进一步扩大hashCode的取值范围
* Created by xuxueli on 17/3/10.
*/
public class ExecutorRouteConsistentHash extends ExecutorRouter {
private static int VIRTUAL_NODE_NUM = 5;
/**
* get hash code on 2^32 ring (md5散列的方式计算hash值)
* @param key
* @return
*/
private static long hash(String key) {
// md5 byte
MessageDigest md5;
try {
md5 = MessageDigest.getInstance("MD5");
} catch (NoSuchAlgorithmException e) {
throw new RuntimeException("MD5 not supported", e);
}
md5.reset();
byte[] keyBytes = null;
try {
keyBytes = key.getBytes("UTF-8");
} catch (UnsupportedEncodingException e) {
throw new RuntimeException("Unknown string :" + key, e);
}
md5.update(keyBytes);
byte[] digest = md5.digest();
// hash code, Truncate to 32-bits
long hashCode = ((long) (digest[3] & 0xFF) << 24)
| ((long) (digest[2] & 0xFF) << 16)
| ((long) (digest[1] & 0xFF) << 8)
| (digest[0] & 0xFF);
long truncateHashCode = hashCode & 0xffffffffL;
return truncateHashCode;
}
public String hashJob(int jobId, List<String> addressList) {
// ------A1------A2-------A3------
// -----------J1------------------
TreeMap<Long, String> addressRing = new TreeMap<Long, String>();
for (String address: addressList) {
for (int i = 0; i < VIRTUAL_NODE_NUM; i++) {
long addressHash = hash("SHARD-" + address + "-NODE-" + i);
addressRing.put(addressHash, address);
}
}
long jobHash = hash(String.valueOf(jobId));
SortedMap<Long, String> lastRing = addressRing.tailMap(jobHash);
if (!lastRing.isEmpty()) {
return lastRing.get(lastRing.firstKey());
}
return addressRing.firstEntry().getValue();
}
@Override
public ReturnT<String> route(TriggerParam triggerParam, List<String> addressList) {
String address = hashJob(triggerParam.getJobId(), addressList);
return new ReturnT<String>(address);
}
}
实现一致性哈希算法中使用的哈希函数,使用MD5算法来保证一致性哈希的平衡性
MessageDigest 类为应用程序提供信息摘要算法的功能,如 MD5 或 SHA 算法。信息摘要是安全的单向哈希函数,它接收任意大小的数据,并输出固定长度的哈希值。
MessageDigest 类是一个引擎类,它是为了提供诸如 SHA1 或 MD5 等密码上安全的报文摘要功能而设计的。密码上安全的报文摘要可接受任意大小的输入(一个字节数组),并产生固定大小的输出,该输出称为一个摘要或散列。摘要具有以下属性:
- 无法通过计算找到两个散列成相同值的报文。
- 摘要不反映任何与输入有关的内容。
返回实现指定摘要算法的 MessageDigest 对象。 algorithm - 所请求算法的名称,SUN提供的常用的算法名称有:MD2
MD5、 SHA-1、SHA-256、SHA-384、 SHA-512
public static MessageDigest getInstance(String algorithm) throws NoSuchAlgorithmException
使用指定的 byte 数组更新摘要。
public void update(byte[] input)
通过执行诸如填充之类的最终操作完成哈希计算。在调用此方法之后,摘要被重置。
public byte[] digest()
十六进制及符号运算
0xFF 是计算机十六进制的表示: 0x就是代表十六进制,A B C D E F 分别代表10 11 12 13 14 15 F就是15 一个F 代表4位二进制:可以看做 是 8 4 2 1。
0xffffffffL 的二进制表示就是:1111,1111 1111,1111 1111,1111 1111,1111
0xFF的二进制表示就是:1111 1111。 高24位补0:0000 0000 0000 0000 0000 0000 1111 1111;
与运算符 &,两个操作数中位都为1,结果才为1,否则结果为0
或运算符 |,两个位只要有一个为1,那么结果就是1,否则就为0
原码、反码、补码
反码:解决负数加法运算问题,将减法运算转换为加法运算,从而简化运算规则;
补码:解决负数加法运算正负零问题,弥补了反码的不足。
总之,反码与补码都是为了解决负数运算问题,跟正数没关系,因此,不管是正整数还是正小数,原码,反码,补码都全部相同。
1、正数的原码、补码、反码均为其本身;
2、负数(二进制)的原码、补码、反码公式:
反码 = 原码(除符号位外)每位取反
补码 = 反码 + 1
例子
public class Test {
public static void main(String[] args) {
byte[] a = new byte[10];
a[0]= -127;
System.out.println(a[0]);
int c = a[0]&0xff;
System.out.println(c);
}
}
结果
-127
129
当将-127赋值给a[0]时候,a[0]作为一个byte类型,其计算机存储的补码是10000001(8位)。
将a[0] 作为int类型向控制台输出的时候,jvm作了一个补位的处理,因为int类型是32位所以补位后的补码就是1111111111111111111111111 10000001(32位),这个32位二进制补码表示的也是-127.
发现没有,虽然byte->int计算机背后存储的二进制补码由10000001(8位)转化成了1111111111111111111111111 10000001(32位)很显然这两个补码表示的十进制数字依然是相同的。
但是我做byte->int的转化 所有时候都只是为了保持 十进制的一致性吗?
不一定吧?好比我们拿到的文件流转成byte数组,难道我们关心的是byte数组的十进制的值是多少吗?我们关心的是其背后二进制存储的补码吧。我做Hash运算,我输入一个IP,转成hashcode,我会在意它的十进制是多少,要保持不变么?我在意的是它的补码保持不变。
所以大家应该能猜到为什么byte类型的数字要&0xff再赋值给int类型,其本质原因就是想保持二进制补码的一致性。
当byte要转化为int的时候,高的24位必然会补1,这样,其二进制补码其实已经不一致了,&0xff可以将高的24位置为0,低8位保持原样。这样做的目的就是为了保证二进制数据的一致性。
当然拉,保证了二进制数据性的同时,如果二进制被当作byte和int来解读,其10进制的值必然是不同的,因为符号位位置已经发生了变化。
象例2中,int c = a[0]&0xff; a[0]&0xff=1111111111111111111111111 10000001&11111111=000000000000000000000000 10000001 ,这个值算一下就是129,
所以c的输出的值就是129。**有人问为什么上面的式子中a[0]不是8位而是32位,因为当系统检测到byte可能会转化成int或者说byte与int类型进行运算的时候,就会将byte的内存空间高位补1(也就是按符号位补位)扩充到32位,再参与运算。**上面的0xff其实是int类型的字面量值,所以可以说byte与int进行运算。
a[0]&0xff相当于
1111 1111 1111 1111 1111 11111 1000 0001 & 0000 0000 0000 0000 0000 0000 1111 1111
运算后
0000 0000 0000 0000 0000 0000 1000 0001
这样一来,保证了补码不变。
在做hash运算的时候,往往输入都不是数值,更多的时候可能是字符串。在做运算的时候,希望保持的是补码的不变,所以byte->int的时候,要&oxff,int->long的时候,要&0xffffffffL
一致性Hash取执行器address过程
由于一般的哈希函数返回一个int(32bit)型的hashCode。因此,可以将该哈希函数能够返回的hashCode表示成一个范围为0—(2^32)-1 环。此处是一个long。
先将ipList地址做hash,得到一个ip hash list存入到treeMap中,相当于分布到环上。当执行任务时,根据jobId做hash运算,得到一个值,使用treeMap#tailMap方法,取所有大于jobId的ipList,最后在结果集中取第一个,后返对应的ip地址。就这是整个一致性Hash选取执行器ip地址的过程。
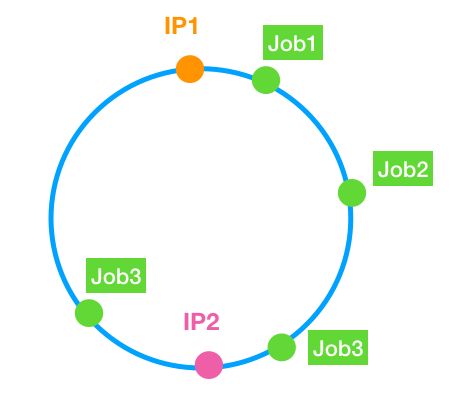
上面的算法,可能会存在任务集中在某个IP执行器的情况,所以算法对其改进,一个IP虚出5个地址来,这样一来,可以更均匀的使任务布到不同的执行器上。

整个一致性Hash的优点:
- 使用MD5做Hash,可以使任务和执行器的分布更加均匀。
- 当新加入执行器后,旧的任务不会出现大规模的调动。当新加入了一个执行器节点后,任务要么在原机器上执行,要么任务在新机器上执行。保证单调一致性。
此Hash算法,也可以应用到网关负载均衡中。
5.2 执行定时任务策略
执行定时任务由2个线程触发:scheduleThread和ringThread
scheduleThread
进入后,先使用数据库锁锁表。
conn.setAutoCommit(false);
preparedStatement = conn.prepareStatement( "select * from xxl_job_lock where lock_name = 'schedule_lock' for update" );
后从数据库中取出triggerNextTime <= nowTime+5s的所有任务,每次会预读未来5s的任务。

待处理的任务分为3个部分:
①过期5s的任务;②过期5s内的任务;③未来5秒要执行的任务
-
对于过期5s的不再执行任务,计算并更新下次执行时间。
-
过期5s内的任务,会立即触发,对任务进行执行。执行后,更新上次执行时间和下次执行时间。如果下次执行时间在未来5s内,那么构造一个[秒环],将下次执行时间的秒和jobId放入到`Map
-
对于未来5s内的任务,执行同上,构造一个[秒环],将下次执行时间的秒和jobId放入到`Map
-
最后更新任务表字段:triggerStatus(是否执行定时任务)、triggerLastTime(上次执行时间)、triggerNextTime(下次执行时间)。
-
释放锁:提交
conn.commit()
ringThread
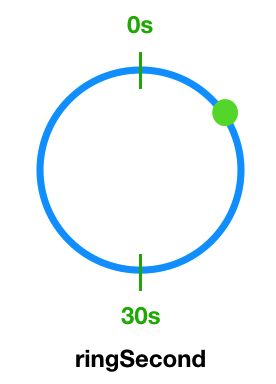
取当前时间秒,以及上一秒(避免处理耗时太长,跨过刻度,向前校验一个刻度)
如果能在Map中取到,那么就会执行jobList。
失败重试
失败后的重试是通过失败日志来实现的。如果执行失败后,会写失败日志。调度器启动时,会启动一个monitorThread线程用来检查失败的任务。在此线程会不断的查询失败的任务,如果失败重试次数大于0,则会再次调用执行器,每执行一次,重试次数减1,直到为0后不再重试。
参考:
&0xFF是怎么个意思
byte类型转换为int类型
负载均衡中的一致性hash算法
一致性哈希算法学习及JAVA代码实现分析
redis入门-一致性哈希算法
buff.getInt() & 0xffffffffL is an identity?